磨人的小妖精们啊!终于可以归置下自己的大脑啦,在这里我要把——整型,长整型,浮点型,字符串,列表,元组,字典,集合,这几个知识点特别多的东西,统一的捯饬捯饬,不然一直脑袋里面乱乱的。
对于Python,一切事物都是对象,对象基于类创建
所以,以下这些值都是对象: "wupeiqi"、38、[‘北京‘, ‘上海‘, ‘深圳‘],并且是根据不同的类生成的对象。
官方的解释是这样的:对象是对客观事物的抽象,类是对对象的抽象。
因此str是类,int是类,dict、list、tuple等等都是类,但是str却不能直接使用,因为它是抽象的表示了字符串这一类事物,并不能满足表示某个特定字符串的需求,我们必须要str1 = ‘‘初始化一个对象,这时的str1具有str的属性,可以使用str中的方法。
类为我们创建对象,提供功能,在python中,一切事物都是对象!(瞧,谁还敢嫌弃我们程序员没有对象,我们可以new一个呀!)
在这里介绍些类、对象、方法的查看方式:
1 >>> str1=‘zhenghao‘
2 >>> type(str1)
3 <type ‘str‘>
4 >>>
查看类的所有方法:dir(类名),就打印出了所有的类方法。
>>> dir(str)
[‘__add__‘, ‘__class__‘, ‘__contains__‘, ‘__delattr__‘, ‘__doc__‘, ‘__eq__‘, ‘__format__‘, ‘__ge__‘, ‘__getattribute__‘, ‘__getitem__‘, ‘__getnewargs__‘, ‘__getslice__‘, ‘__gt__‘, ‘__hash__‘, ‘__init__‘, ‘__le__‘, ‘__len__‘, ‘__lt__‘, ‘__mod__‘, ‘__mul__‘, ‘__ne__‘, ‘__new__‘, ‘__reduce__‘, ‘__reduce_ex__‘, ‘__repr__‘, ‘__rmod__‘, ‘__rmul__‘, ‘__setattr__‘, ‘__sizeof__‘, ‘__str__‘, ‘__subclasshook__‘, ‘_formatter_field_name_split‘, ‘_formatter_parser‘, ‘capitalize‘, ‘center‘, ‘count‘, ‘decode‘, ‘encode‘, ‘endswith‘, ‘expandtabs‘, ‘find‘, ‘format‘, ‘index‘, ‘isalnum‘, ‘isalpha‘, ‘isdigit‘, ‘islower‘, ‘isspace‘, ‘istitle‘, ‘isupper‘, ‘join‘, ‘ljust‘, ‘lower‘, ‘lstrip‘, ‘partition‘, ‘replace‘, ‘rfind‘, ‘rindex‘, ‘rjust‘, ‘rpartition‘, ‘rsplit‘, ‘rstrip‘, ‘split‘, ‘splitlines‘, ‘startswith‘, ‘strip‘, ‘swapcase‘, ‘title‘, ‘translate‘, ‘upper‘, ‘zfill‘]
那么问题来了,方法名为什么有的两边带着下划线,有的没有呢?那是python用来标识私有方法、非私有方法哒,带下划线的标识私有方法,他们通常拥有不止一种调用方法。如下,我定义了两个字符串,__add__的+的效果是相同的。这里有一个内置方法很特殊:__init__,它是类中的构造方法,会在调用其所在类的时候自动执行。
1 >>> str1=‘zhenghao‘
2 >>> str2=‘love xiaokai‘
3 >>> str1.__add__(str2)
4 ‘zhenghaolove xiaokai‘
5 >>> str1+str2
6 ‘zhenghaolove xiaokai‘
7 >>>
在python中,还有一个“help(类名)”方法:可以查看类的详细功能;“help(类名.功能名)”:查看类中某功能的详细情况
一、整数
整数是不可变的,不可迭代的
1.全部的方法
1 >>> dir(int)
2 [‘__abs__‘, ‘__add__‘, ‘__and__‘, ‘__clas s__‘, ‘__cmp__‘, ‘__coerce__‘, ‘__delattr__‘, ‘__div__‘, ‘__divmod__‘, ‘__doc__‘, ‘__float__‘, ‘__floordiv__‘, ‘__format__‘, ‘__getattribute__‘, ‘__getnewargs__‘, ‘__hash__‘, ‘__hex__‘, ‘__index__‘, ‘__init__‘, ‘__int__‘, ‘__invert__‘, ‘__long__‘, ‘__lshift__‘, ‘__mod__‘, ‘__mul__‘, ‘__neg__‘, ‘__new__‘, ‘__nonzero__‘, ‘__oct__‘, ‘__or__‘, ‘__pos__‘, ‘__pow__‘, ‘__radd__‘, ‘__rand__‘, ‘__rdiv__‘, ‘__rdivmod__‘, ‘__reduce__‘, ‘__reduce_ex__‘, ‘__repr__‘, ‘__rfloordiv__‘, ‘__rlshift__‘, ‘__rmod__‘, ‘__rmul__‘, ‘__ror__‘, ‘__rpow__‘, ‘__rrshift__‘, ‘__rshift__‘, ‘__rsub__‘, ‘__rtruediv__‘, ‘__rxor__‘, ‘__setattr__‘, ‘__sizeof__‘, ‘__str__‘, ‘__sub__‘, ‘__subclasshook__‘, ‘__truediv__‘, ‘__trunc__‘, ‘__xor__‘, ‘bit_length‘, ‘conjugate‘, ‘denominator‘, ‘imag‘, ‘numerator‘, ‘real‘]
每一个整数都具备如下功能:


1 class int(object): 2 """ 3 int(x=0) -> int or long 4 int(x, base=10) -> int or long 5 6 Convert a number or string to an integer, or return 0 if no arguments 7 are given. If x is floating point, the conversion truncates towards zero. 8 If x is outside the integer range, the function returns a long instead. 9 10 If x is not a number or if base is given, then x must be a string or 11 Unicode object representing an integer literal in the given base. The 12 literal can be preceded by ‘+‘ or ‘-‘ and be surrounded by whitespace. 13 The base defaults to 10. Valid bases are 0 and 2-36. Base 0 means to 14 interpret the base from the string as an integer literal. 15 >>> int(‘0b100‘, base=0) 16 4 17 """ 18 def bit_length(self): # real signature unknown; restored from __doc__ 19 """返回表示该数字时所用的最小位数 20 int.bit_length() -> int 21 22 Number of bits necessary to represent self in binary. 23 >>> bin(37) 24 ‘0b100101‘ 25 >>> (37).bit_length() 26 6 27 """ 28 return 0 29 30 def conjugate(self, *args, **kwargs): # real signature unknown 31 """返回一个复数的共轭复数 32 Returns self, the complex conjugate of any int. """ 33 pass 34 35 def __abs__(self): # real signature unknown; restored from __doc__ 36 """ 返回绝对值 37 x.__abs__() <==> abs(x) """ 38 pass 39 40 def __add__(self, y): # real signature unknown; restored from __doc__ 41 """ 返回两个数的和 42 x.__add__(y) <==> x+y """ 43 pass 44 45 def __and__(self, y): # real signature unknown; restored from __doc__ 46 """ 返回两个数按位与的结果 47 x.__and__(y) <==> x&y """ 48 pass 49 50 def __cmp__(self, y): # real signature unknown; restored from __doc__ 51 """返回两个数比较的结果,参数从左至右(a,b),a>b返回1,a<b返回-1,a=b返回0 52 x.__cmp__(y) <==> cmp(x,y) """ 53 pass 54 55 def __coerce__(self, y): # real signature unknown; restored from __doc__ 56 """a.__coerce__(b),强制返回一个元组(a,b) 57 x.__coerce__(y) <==> coerce(x, y) """ 58 pass 59 60 def __divmod__(self, y): # real signature unknown; restored from __doc__ 61 """ 相除,得到商和余数组成的元组 62 x.__divmod__(y) <==> divmod(x, y) """ 63 pass 64 65 def __div__(self, y): # real signature unknown; restored from __doc__ 66 """返回两数相除的商 67 x.__div__(y) <==> x/y """ 68 pass 69 70 def __float__(self): # real signature unknown; restored from __doc__ 71 """将数据类型强制转换为float 72 x.__float__() <==> float(x) """ 73 pass 74 75 def __floordiv__(self, y): # real signature unknown; restored from __doc__ 76 """ 不保留小数点后的小数除法,也可以用‘//’来表示:a//b,我们亲切地称之为“地板除”!!! 77 x.__floordiv__(y) <==> x//y """ 78 pass 79 80 def __format__(self, *args, **kwargs): # real signature unknown 81 """ 格式化""" 82 pass 83 84 def __getattribute__(self, name): # real signature unknown; restored from __doc__ 85 """无条件被调用,通过实例访问属性 86 x.__getattribute__(‘name‘) <==> x.name """ 87 pass 88 89 def __getnewargs__(self, *args, **kwargs): # real signature unknown 90 """ 内部调用 __new__方法或创建对象时传入参数使用 """ 91 pass 92 93 def __hash__(self): # real signature unknown; restored from __doc__ 94 """ 如果对象object为哈希表类型,返回对象object的哈希值。哈希值为整数。在字典查找中,哈希值用于快速比较字典的键。两个数值如果相等,则哈希值也相等 95 x.__hash__() <==> hash(x) """ 96 pass 97 98 def __hex__(self): # real signature unknown; restored from __doc__ 99 """ 返回当前数的 十六进制 表示 100 x.__hex__() <==> hex(x) """ 101 pass 102 103 def __index__(self): # real signature unknown; restored from __doc__ 104 """ 用于切片,对数字无意义 105 x[y:z] <==> x[y.__index__():z.__index__()] """ 106 pass 107 108 def __init__(self, x, base=10): # known special case of int.__init__ 109 """构造函数 110 int(x=0) -> int or long 111 int(x, base=10) -> int or long 112 113 Convert a number or string to an integer, or return 0 if no arguments 114 are given. If x is floating point, the conversion truncates towards zero. 115 If x is outside the integer range, the function returns a long instead. 116 117 If x is not a number or if base is given, then x must be a string or 118 Unicode object representing an integer literal in the given base. The 119 literal can be preceded by ‘+‘ or ‘-‘ and be surrounded by whitespace. 120 The base defaults to 10. Valid bases are 0 and 2-36. Base 0 means to 121 interpret the base from the string as an integer literal. 122 >>> int(‘0b100‘, base=0) 123 4 124 # (copied from class doc) 125 """ 126 pass 127 128 def __int__(self): # real signature unknown; restored from __doc__ 129 """ 转换为整数 130 x.__int__() <==> int(x) """ 131 pass 132 133 def __invert__(self): # real signature unknown; restored from __doc__ 134 """按位求反 135 x.__invert__() <==> ~x """ 136 pass 137 138 def __long__(self): # real signature unknown; restored from __doc__ 139 """转换为长整数 140 x.__long__() <==> long(x) """ 141 pass 142 143 def __lshift__(self, y): # real signature unknown; restored from __doc__ 144 """ 左移,相对二进制的操作 145 x.__lshift__(y) <==> x<<y """ 146 pass 147 148 def __mod__(self, y): # real signature unknown; restored from __doc__ 149 """ 取余 150 x.__mod__(y) <==> x%y """ 151 pass 152 153 def __mul__(self, y): # real signature unknown; restored from __doc__ 154 """ 返回两数相乘的积 155 x.__mul__(y) <==> x*y """ 156 pass 157 158 def __neg__(self): # real signature unknown; restored from __doc__ 159 """ 返回一个数的负数,个人觉得和相反数没差 160 x.__neg__() <==> -x """ 161 pass 162 163 @staticmethod # known case of __new__ 164 def __new__(S, *more): # real signature unknown; restored from __doc__ 165 """ 创建一个int类的新对象 166 T.__new__(S, ...) -> a new object with type S, a subtype of T """ 167 pass 168 169 def __nonzero__(self): # real signature unknown; restored from __doc__ 170 """ 判断一个数是不是0 171 x.__nonzero__() <==> x != 0 """ 172 pass 173 174 def __oct__(self): # real signature unknown; restored from __doc__ 175 """ 返回该值的 八进制 表示 176 x.__oct__() <==> oct(x) """ 177 pass 178 179 def __or__(self, y): # real signature unknown; restored from __doc__ 180 """ 位运算,或,针对二进制数 181 x.__or__(y) <==> x|y """ 182 pass 183 184 def __pos__(self): # real signature unknown; restored from __doc__ 185 """ 并没什么卵用,说是a.__pos__(),会返回一个+a,但是不管输入整数还是负数,返回值都是他本身,感觉歪果仁真有幽默感 186 x.__pos__() <==> +x """ 187 pass 188 189 def __pow__(self, y, z=None): # real signature unknown; restored from __doc__ 190 """ 幂,次方 191 x.__pow__(y[, z]) <==> pow(x, y[, z]) """ 192 pass 193 194 def __radd__(self, y): # real signature unknown; restored from __doc__ 195 """x.__radd__(y) <==> y+x """ 196 pass 197 198 def __rand__(self, y): # real signature unknown; restored from __doc__ 199 """x.__rand__(y) <==> y&x """ 200 pass 201 202 def __rdivmod__(self, y): # real signature unknown; restored from __doc__ 203 """ x.__rdivmod__(y) <==> divmod(y, x) """ 204 pass 205 206 def __rdiv__(self, y): # real signature unknown; restored from __doc__ 207 """ x.__rdiv__(y) <==> y/x """ 208 pass 209 210 def __repr__(self): # real signature unknown; restored from __doc__ 211 """ 转化为解释器可读取的形式 212 x.__repr__() <==> repr(x) """ 213 pass 214 215 def __rfloordiv__(self, y): # real signature unknown; restored from __doc__ 216 """ 217 x.__rfloordiv__(y) <==> y//x """ 218 pass 219 220 def __rlshift__(self, y): # real signature unknown; restored from __doc__ 221 """ x.__rlshift__(y) <==> y<<x """ 222 pass 223 224 def __rmod__(self, y): # real signature unknown; restored from __doc__ 225 """ x.__rmod__(y) <==> y%x """ 226 pass 227 228 def __rmul__(self, y): # real signature unknown; restored from __doc__ 229 """ x.__rmul__(y) <==> y*x """ 230 pass 231 232 def __ror__(self, y): # real signature unknown; restored from __doc__ 233 """ x.__ror__(y) <==> y|x """ 234 pass 235 236 def __rpow__(self, x, z=None): # real signature unknown; restored from __doc__ 237 """ y.__rpow__(x[, z]) <==> pow(x, y[, z]) """ 238 pass 239 240 def __rrshift__(self, y): # real signature unknown; restored from __doc__ 241 """ x.__rrshift__(y) <==> y>>x """ 242 pass 243 244 def __rshift__(self, y): # real signature unknown; restored from __doc__ 245 """ x.__rshift__(y) <==> x>>y """ 246 pass 247 248 def __rsub__(self, y): # real signature unknown; restored from __doc__ 249 """ x.__rsub__(y) <==> y-x """ 250 pass 251 252 def __rtruediv__(self, y): # real signature unknown; restored from __doc__ 253 """ x.__rtruediv__(y) <==> y/x """ 254 pass 255 256 def __rxor__(self, y): # real signature unknown; restored from __doc__ 257 """ x.__rxor__(y) <==> y^x """ 258 pass 259 260 def __str__(self): # real signature unknown; restored from __doc__ 261 """ 转换为人阅读的形式,如果没有适于人阅读的解释形式的话,则返回解释器课阅读的形式 262 x.__str__() <==> str(x) """ 263 pass 264 265 def __sub__(self, y): # real signature unknown; restored from __doc__ 266 """ 返回两数相减的差 267 x.__sub__(y) <==> x-y """ 268 pass 269 270 def __truediv__(self, y): # real signature unknown; restored from __doc__ 271 """返回两数相除的商,这里的除是精确的除法,不会省略小数点后的值 272 x.__truediv__(y) <==> x/y """ 273 pass 274 275 def __trunc__(self, *args, **kwargs): # real signature unknown 276 """返回数值被截取为整形的值,在整形中无意义 277 Truncating an Integral returns itself. """ 278 pass 279 280 def __xor__(self, y): # real signature unknown; restored from __doc__ 281 """ 按位异或 282 x.__xor__(y) <==> x^y """ 283 pass 284 285 denominator = property(lambda self: object(), lambda self, v: None, lambda self: None) # default 286 """ 分母 = 1 """ 287 """the denominator of a rational number in lowest terms""" 288 289 imag = property(lambda self: object(), lambda self, v: None, lambda self: None) # default 290 """ 虚数,无意义 """ 291 """the imaginary part of a complex number""" 292 293 numerator = property(lambda self: object(), lambda self, v: None, lambda self: None) # default 294 """ 分子 = 数字大小 """ 295 """the numerator of a rational number in lowest terms""" 296 297 real = property(lambda self: object(), lambda self, v: None, lambda self: None) # default 298 """ 实数,无意义 """ 299 """the real part of a complex number""" 300 301 int Code
我已经在源码中加入了注释,原谅我后面很多函数没有加注释都,因为那些前面在前面已近出现过了,只是在前面多了一个‘r‘的,比如and,变成了rand,在这里统一总结,就是参数的顺序从右到左反过来了。比如原本的a.__div__(b)是a/b,但是a.__rdiv__(b)的表示的就是b/a,对!就是这么坑爹!
2.常用方法
在int类中,比较普通的就是+,-,*,/,%,位运算,进制间以及数据类型间的转换。下面对于比较特别但是常用的方法再进行一下记录:
(1) __cmp__:比较两个数的大小
1 >>> a = 12 2 >>> b = 15 3 >>> cmp(a,b) #比较两个参数的值,如果第一个参数小于第二个参数,返回-1 4 -1 5 >>> cmp(b,a) #比较两个参数的值,如果第一个参数大于第二个参数,返回1 6 1 7 >>> c = 12 8 >>> a.__cmp__(c) #比较两个参数的值,如果第一个参数等于第二个参数,返回0 9 0 #cmp方法也有两种调用方式
(2)__neg__/__abs__:取相反数/取绝对值
1 >>> a = -12
2 >>> b = 21
3 >>> a.__neg__() #求相反数
4 12
5 >>> b.__neg__()
6 -21
7 >>> a.__abs__() #求绝对值
8 12
9 >>> b.__abs__()
10 21
(3)__coerce__:强制返回一个元组(好吧,我承认这个并不常用,就是和divmod比较看看)
(4)__divmod__:返回两个数相除的商和余数组成的元组(商,余数) 应用:显示数据分页
1 >>> a = 102 2 >>> b = 10 3 >>> a.__divmod__(b) 4 (10, 2) 5 >>> a.__coerce__(b) 6 (102, 10)
(5)__floordiv__:不保留小数点后的小数除法,在这儿把所有的除法都整理了,然而我并没发现__div__和__floordiv__的区别啊~~~
1 >>> a = 13 2 >>> b = 2 3 >>> a.__div__(b) 4 6 5 >>> a.__truediv__(b) 6 6.5 7 >>> a.__floordiv__(b) 8 6 9 >>> a/b 10 6 11 >>> a//b 12 6
(6)__repr__/__str__:转化为解释器可读取的形式/转换为人阅读的形式
二、长整型
可能如:2147483649、9223372036854775807
1 >>> dir(long)
2 [‘__abs__‘, ‘__add__‘, ‘__and__‘, ‘__class__‘, ‘__cmp__‘, ‘__coerce__‘, ‘__delattr__‘, ‘__div__‘, ‘__divmod__‘, ‘__doc__‘, ‘__float__‘, ‘__floordiv__‘, ‘__format__‘, ‘__getattribute__‘, ‘__getnewargs__‘, ‘__hash__‘, ‘__hex__‘, ‘__index__‘, ‘__init__‘, ‘__int__‘, ‘__invert__‘, ‘__long__‘, ‘__lshift__‘, ‘__mod__‘, ‘__mul__‘, ‘__neg__‘, ‘__new__‘, ‘__nonzero__‘, ‘__oct__‘, ‘__or__‘, ‘__pos__‘, ‘__pow__‘, ‘__radd__‘, ‘__rand__‘, ‘__rdiv__‘, ‘__rdivmod__‘, ‘__reduce__‘, ‘__reduce_ex__‘, ‘__repr__‘, ‘__rfloordiv__‘, ‘__rlshift__‘, ‘__rmod__‘, ‘__rmul__‘, ‘__ror__‘, ‘__rpow__‘, ‘__rrshift__‘, ‘__rshift__‘, ‘__rsub__‘, ‘__rtruediv__‘, ‘__rxor__‘, ‘__setattr__‘, ‘__sizeof__‘, ‘__str__‘, ‘__sub__‘, ‘__subclasshook__‘, ‘__truediv__‘, ‘__trunc__‘, ‘__xor__‘, ‘bit_length‘, ‘conjugate‘, ‘denominator‘, ‘imag‘, ‘numerator‘, ‘real‘]
每个长整型都具备如下功能:
long长整形就是长长的整形。。。现在的操作系统大部分int类型的表示范围是2^32,而长整形就是2^64,在python里,不需要程序员手动的转换int和long的数据类型,当数值的大小超过了int的表示范围,python会自动将数据类型转换为long型,就是这么智能!!!既然long和int同表示整形,那么他们包含的方法也是差不多的,在这里就不再介绍了。
三、浮点型
如:3.14、2.88
1 >>> dir(float)
2 [‘__abs__‘, ‘__add__‘, ‘__class__‘, ‘__coerce__‘, ‘__delattr__‘, ‘__div__‘, ‘__divmod__‘, ‘__doc__‘, ‘__eq__‘, ‘__float__‘, ‘__floordiv__‘, ‘__format__‘, ‘__ge__‘, ‘__getattribute__‘, ‘__getformat__‘, ‘__getnewargs__‘, ‘__gt__‘, ‘__hash__‘, ‘__init__‘, ‘__int__‘, ‘__le__‘, ‘__long__‘, ‘__lt__‘, ‘__mod__‘, ‘__mul__‘, ‘__ne__‘, ‘__neg__‘, ‘__new__‘, ‘__nonzero__‘, ‘__pos__‘, ‘__pow__‘, ‘__radd__‘, ‘__rdiv__‘, ‘__rdivmod__‘, ‘__reduce__‘, ‘__reduce_ex__‘, ‘__repr__‘, ‘__rfloordiv__‘, ‘__rmod__‘, ‘__rmul__‘, ‘__rpow__‘, ‘__rsub__‘, ‘__rtruediv__‘, ‘__setattr__‘, ‘__setformat__‘, ‘__sizeof__‘, ‘__str__‘, ‘__sub__‘, ‘__subclasshook__‘, ‘__truediv__‘, ‘__trunc__‘, ‘as_integer_ratio‘, ‘conjugate‘, ‘fromhex‘, ‘hex‘, ‘imag‘, ‘is_integer‘, ‘real‘]
每个浮点型都具备如下功能:
float我们在创建对象的时候,python也会很聪明的识别出float类型,在计算的时候也是这样,不管表达式中有多少整形多少浮点型,只要存在浮点型,那么所有计算都按照浮点型计算,得出的结果也会是float类型。其余方法和整形并没有太大差别,在这里也不做详细总结了。
四、字符串
字符串是不可修改不可变的,有序的,不可迭代的,有索引和切片
1.字符串全部方法
如:‘zhenghao‘、‘xiaokai‘
1 >> dir(str)
2 [‘__add__‘, ‘__class__‘, ‘__contains__‘, ‘__delattr__‘, ‘__doc__‘, ‘__eq__‘, ‘__format__‘, ‘__ge__‘, ‘__getattribute__‘, ‘__getitem__‘, ‘__getnewargs__‘, ‘__getslice__‘, ‘__gt__‘, ‘__hash__‘, ‘__init__‘, ‘__le__‘, ‘__len__‘, ‘__lt__‘, ‘__mod__‘, ‘__mul__‘, ‘__ne__‘, ‘__new__‘, ‘__reduce__‘, ‘__reduce_ex__‘, ‘__repr__‘, ‘__rmod__‘, ‘__rmul__‘, ‘__setattr__‘, ‘__sizeof__‘, ‘__str__‘, ‘__subclasshook__‘, ‘_formatter_field_name_split‘, ‘_formatter_parser‘, ‘capitalize‘, ‘center‘, ‘count‘, ‘decode‘, ‘encode‘, ‘endswith‘, ‘expandtabs‘, ‘find‘, ‘format‘, ‘index‘, ‘isalnum‘, ‘isalpha‘, ‘isdigit‘, ‘islower‘, ‘isspace‘, ‘istitle‘, ‘isupper‘, ‘join‘, ‘ljust‘, ‘lower‘, ‘lstrip‘, ‘partition‘, ‘replace‘, ‘rfind‘, ‘rindex‘, ‘rjust‘, ‘rpartition‘, ‘rsplit‘, ‘rstrip‘, ‘split‘, ‘splitlines‘, ‘startswith‘, ‘strip‘, ‘swapcase‘, ‘title‘, ‘translate‘, ‘upper‘, ‘zfill‘]
每个字符串都具备如下功能:
1 class str(basestring): 2 """ 3 str(object=‘‘) -> string 4 5 Return a nice string representation of the object. 6 If the argument is a string, the return value is the same object. 7 """ 8 def capitalize(self): 9 """ 首字母变大写 """ 10 """ 11 S.capitalize() -> string 12 13 Return a copy of the string S with only its first character 14 capitalized. 15 """ 16 return "" 17 18 def center(self, width, fillchar=None): 19 """ 内容居中,width:总长度;fillchar:空白处填充内容,默认无 """ 20 """ 21 S.center(width[, fillchar]) -> string 22 23 Return S centered in a string of length width. Padding is 24 done using the specified fill character (default is a space) 25 """ 26 return "" 27 28 def count(self, sub, start=None, end=None): 29 """ 子序列个数 """ 30 """ 31 S.count(sub[, start[, end]]) -> int 32 33 Return the number of non-overlapping occurrences of substring sub in 34 string S[start:end]. Optional arguments start and end are interpreted 35 as in slice notation. 36 """ 37 return 0 38 39 def decode(self, encoding=None, errors=None): 40 """ 解码 """ 41 """ 42 S.decode([encoding[,errors]]) -> object 43 44 Decodes S using the codec registered for encoding. encoding defaults 45 to the default encoding. errors may be given to set a different error 46 handling scheme. Default is ‘strict‘ meaning that encoding errors raise 47 a UnicodeDecodeError. Other possible values are ‘ignore‘ and ‘replace‘ 48 as well as any other name registered with codecs.register_error that is 49 able to handle UnicodeDecodeErrors. 50 """ 51 return object() 52 53 def encode(self, encoding=None, errors=None): 54 """ 编码,针对unicode """ 55 """ 56 S.encode([encoding[,errors]]) -> object 57 58 Encodes S using the codec registered for encoding. encoding defaults 59 to the default encoding. errors may be given to set a different error 60 handling scheme. Default is ‘strict‘ meaning that encoding errors raise 61 a UnicodeEncodeError. Other possible values are ‘ignore‘, ‘replace‘ and 62 ‘xmlcharrefreplace‘ as well as any other name registered with 63 codecs.register_error that is able to handle UnicodeEncodeErrors. 64 """ 65 return object() 66 67 def endswith(self, suffix, start=None, end=None): 68 """ 是否以 xxx 结束 """ 69 """ 70 S.endswith(suffix[, start[, end]]) -> bool 71 72 Return True if S ends with the specified suffix, False otherwise. 73 With optional start, test S beginning at that position. 74 With optional end, stop comparing S at that position. 75 suffix can also be a tuple of strings to try. 76 """ 77 return False 78 79 def expandtabs(self, tabsize=None): 80 """ 将tab转换成空格,默认一个tab转换成8个空格 """ 81 """ 82 S.expandtabs([tabsize]) -> string 83 84 Return a copy of S where all tab characters are expanded using spaces. 85 If tabsize is not given, a tab size of 8 characters is assumed. 86 """ 87 return "" 88 89 def find(self, sub, start=None, end=None): 90 """ 寻找子序列位置,如果没找到,则异常 """ 91 """ 92 S.find(sub [,start [,end]]) -> int 93 94 Return the lowest index in S where substring sub is found, 95 such that sub is contained within S[start:end]. Optional 96 arguments start and end are interpreted as in slice notation. 97 98 Return -1 on failure. 99 """ 100 return 0 101 102 def format(*args, **kwargs): # known special case of str.format 103 """ 字符串格式化,动态参数,将函数式编程时细说 """ 104 """ 105 S.format(*args, **kwargs) -> string 106 107 Return a formatted version of S, using substitutions from args and kwargs. 108 The substitutions are identified by braces (‘{‘ and ‘}‘). 109 """ 110 pass 111 112 def index(self, sub, start=None, end=None): 113 """ 子序列位置,如果没找到,则返回-1 """ 114 S.index(sub [,start [,end]]) -> int 115 116 Like S.find() but raise ValueError when the substring is not found. 117 """ 118 return 0 119 120 def isalnum(self): 121 """ 是否是字母和数字 """ 122 """ 123 S.isalnum() -> bool 124 125 Return True if all characters in S are alphanumeric 126 and there is at least one character in S, False otherwise. 127 """ 128 return False 129 130 def isalpha(self): 131 """ 是否是字母 """ 132 """ 133 S.isalpha() -> bool 134 135 Return True if all characters in S are alphabetic 136 and there is at least one character in S, False otherwise. 137 """ 138 return False 139 140 def isdigit(self): 141 """ 是否是数字 """ 142 """ 143 S.isdigit() -> bool 144 145 Return True if all characters in S are digits 146 and there is at least one character in S, False otherwise. 147 """ 148 return False 149 150 def islower(self): 151 """ 是否小写 """ 152 """ 153 S.islower() -> bool 154 155 Return True if all cased characters in S are lowercase and there is 156 at least one cased character in S, False otherwise. 157 """ 158 return False 159 160 def isspace(self): 161 """是否空格 162 S.isspace() -> bool 163 164 Return True if all characters in S are whitespace 165 and there is at least one character in S, False otherwise. 166 """ 167 return False 168 169 def istitle(self): 170 """是否标题 171 S.istitle() -> bool 172 173 Return True if S is a titlecased string and there is at least one 174 character in S, i.e. uppercase characters may only follow uncased 175 characters and lowercase characters only cased ones. Return False 176 otherwise. 177 """ 178 return False 179 180 def isupper(self): 181 """是否大写 182 S.isupper() -> bool 183 184 Return True if all cased characters in S are uppercase and there is 185 at least one cased character in S, False otherwise. 186 """ 187 return False 188 189 def join(self, iterable): 190 """ 连接 """ 191 """ 192 S.join(iterable) -> string 193 194 Return a string which is the concatenation of the strings in the 195 iterable. The separator between elements is S. 196 """ 197 return "" 198 199 def ljust(self, width, fillchar=None): 200 """ 内容左对齐,右侧填充 """ 201 """ 202 S.ljust(width[, fillchar]) -> string 203 204 Return S left-justified in a string of length width. Padding is 205 done using the specified fill character (default is a space). 206 """ 207 return "" 208 209 def lower(self): 210 """ 变小写 """ 211 """ 212 S.lower() -> string 213 214 Return a copy of the string S converted to lowercase. 215 """ 216 return "" 217 218 def lstrip(self, chars=None): 219 """ 移除左侧空白 """ 220 """ 221 S.lstrip([chars]) -> string or unicode 222 223 Return a copy of the string S with leading whitespace removed. 224 If chars is given and not None, remove characters in chars instead. 225 If chars is unicode, S will be converted to unicode before stripping 226 """ 227 return "" 228 229 def partition(self, sep): 230 """ 分割,前,中,后三部分 """ 231 """ 232 S.partition(sep) -> (head, sep, tail) 233 234 Search for the separator sep in S, and return the part before it, 235 the separator itself, and the part after it. If the separator is not 236 found, return S and two empty strings. 237 """ 238 pass 239 240 def replace(self, old, new, count=None): 241 """ 替换 """ 242 """ 243 S.replace(old, new[, count]) -> string 244 245 Return a copy of string S with all occurrences of substring 246 old replaced by new. If the optional argument count is 247 given, only the first count occurrences are replaced. 248 """ 249 return "" 250 251 def rfind(self, sub, start=None, end=None): 252 """ 253 S.rfind(sub [,start [,end]]) -> int 254 255 Return the highest index in S where substring sub is found, 256 such that sub is contained within S[start:end]. Optional 257 arguments start and end are interpreted as in slice notation. 258 259 Return -1 on failure. 260 """ 261 return 0 262 263 def rindex(self, sub, start=None, end=None): 264 """ 265 S.rindex(sub [,start [,end]]) -> int 266 267 Like S.rfind() but raise ValueError when the substring is not found. 268 """ 269 return 0 270 271 def rjust(self, width, fillchar=None): 272 """ 273 S.rjust(width[, fillchar]) -> string 274 275 Return S right-justified in a string of length width. Padding is 276 done using the specified fill character (default is a space) 277 """ 278 return "" 279 280 def rpartition(self, sep): 281 """ 282 S.rpartition(sep) -> (head, sep, tail) 283 284 Search for the separator sep in S, starting at the end of S, and return 285 the part before it, the separator itself, and the part after it. If the 286 separator is not found, return two empty strings and S. 287 """ 288 pass 289 290 def rsplit(self, sep=None, maxsplit=None): 291 """ 292 S.rsplit([sep [,maxsplit]]) -> list of strings 293 294 Return a list of the words in the string S, using sep as the 295 delimiter string, starting at the end of the string and working 296 to the front. If maxsplit is given, at most maxsplit splits are 297 done. If sep is not specified or is None, any whitespace string 298 is a separator. 299 """ 300 return [] 301 302 def rstrip(self, chars=None): 303 """ 304 S.rstrip([chars]) -> string or unicode 305 306 Return a copy of the string S with trailing whitespace removed. 307 If chars is given and not None, remove characters in chars instead. 308 If chars is unicode, S will be converted to unicode before stripping 309 """ 310 return "" 311 312 def split(self, sep=None, maxsplit=None): 313 """ 分割, maxsplit最多分割几次 """ 314 """ 315 S.split([sep [,maxsplit]]) -> list of strings 316 317 Return a list of the words in the string S, using sep as the 318 delimiter string. If maxsplit is given, at most maxsplit 319 splits are done. If sep is not specified or is None, any 320 whitespace string is a separator and empty strings are removed 321 from the result. 322 """ 323 return [] 324 325 def splitlines(self, keepends=False): 326 """ 根据换行分割 """ 327 """ 328 S.splitlines(keepends=False) -> list of strings 329 330 Return a list of the lines in S, breaking at line boundaries. 331 Line breaks are not included in the resulting list unless keepends 332 is given and true. 333 """ 334 return [] 335 336 def startswith(self, prefix, start=None, end=None): 337 """ 是否起始 """ 338 """ 339 S.startswith(prefix[, start[, end]]) -> bool 340 341 Return True if S starts with the specified prefix, False otherwise. 342 With optional start, test S beginning at that position. 343 With optional end, stop comparing S at that position. 344 prefix can also be a tuple of strings to try. 345 """ 346 return False 347 348 def strip(self, chars=None): 349 """ 移除两段空白 """ 350 """ 351 S.strip([chars]) -> string or unicode 352 353 Return a copy of the string S with leading and trailing 354 whitespace removed. 355 If chars is given and not None, remove characters in chars instead. 356 If chars is unicode, S will be converted to unicode before stripping 357 """ 358 return "" 359 360 def swapcase(self): 361 """ 大写变小写,小写变大写 """ 362 """ 363 S.swapcase() -> string 364 365 Return a copy of the string S with uppercase characters 366 converted to lowercase and vice versa. 367 """ 368 return "" 369 370 def title(self): 371 """ 372 S.title() -> string 373 374 Return a titlecased version of S, i.e. words start with uppercase 375 characters, all remaining cased characters have lowercase. 376 """ 377 return "" 378 379 def translate(self, table, deletechars=None): 380 """ 381 转换,需要先做一个对应表,最后一个表示删除字符集合 382 intab = "aeiou" 383 outtab = "12345" 384 trantab = maketrans(intab, outtab) 385 str = "this is string example....wow!!!" 386 print str.translate(trantab, ‘xm‘) 387 """ 388 389 """ 390 S.translate(table [,deletechars]) -> string 391 392 Return a copy of the string S, where all characters occurring 393 in the optional argument deletechars are removed, and the 394 remaining characters have been mapped through the given 395 translation table, which must be a string of length 256 or None. 396 If the table argument is None, no translation is applied and 397 the operation simply removes the characters in deletechars. 398 """ 399 return "" 400 401 def upper(self): 402 """ 403 S.upper() -> string 404 405 Return a copy of the string S converted to uppercase. 406 """ 407 return "" 408 409 def zfill(self, width): 410 """方法返回指定长度的字符串,原字符串右对齐,前面填充0。""" 411 """ 412 S.zfill(width) -> string 413 414 Pad a numeric string S with zeros on the left, to fill a field 415 of the specified width. The string S is never truncated. 416 """ 417 return "" 418 419 def _formatter_field_name_split(self, *args, **kwargs): # real signature unknown 420 pass 421 422 def _formatter_parser(self, *args, **kwargs): # real signature unknown 423 pass 424 425 def __add__(self, y): 426 """ x.__add__(y) <==> x+y """ 427 pass 428 429 def __contains__(self, y): 430 """ x.__contains__(y) <==> y in x """ 431 pass 432 433 def __eq__(self, y): 434 """ x.__eq__(y) <==> x==y """ 435 pass 436 437 def __format__(self, format_spec): 438 """ 439 S.__format__(format_spec) -> string 440 441 Return a formatted version of S as described by format_spec. 442 """ 443 return "" 444 445 def __getattribute__(self, name): 446 """ x.__getattribute__(‘name‘) <==> x.name """ 447 pass 448 449 def __getitem__(self, y): 450 """ x.__getitem__(y) <==> x[y] """ 451 pass 452 453 def __getnewargs__(self, *args, **kwargs): # real signature unknown 454 pass 455 456 def __getslice__(self, i, j): 457 """ 458 x.__getslice__(i, j) <==> x[i:j] 459 460 Use of negative indices is not supported. 461 """ 462 pass 463 464 def __ge__(self, y): 465 """ x.__ge__(y) <==> x>=y """ 466 pass 467 468 def __gt__(self, y): 469 """ x.__gt__(y) <==> x>y """ 470 pass 471 472 def __hash__(self): 473 """ x.__hash__() <==> hash(x) """ 474 pass 475 476 def __init__(self, string=‘‘): # known special case of str.__init__ 477 """ 478 str(object=‘‘) -> string 479 480 Return a nice string representation of the object. 481 If the argument is a string, the return value is the same object. 482 # (copied from class doc) 483 """ 484 pass 485 486 def __len__(self): 487 """ x.__len__() <==> len(x) """ 488 pass 489 490 def __le__(self, y): 491 """ x.__le__(y) <==> x<=y """ 492 pass 493 494 def __lt__(self, y): 495 """ x.__lt__(y) <==> x<y """ 496 pass 497 498 def __mod__(self, y): 499 """ x.__mod__(y) <==> x%y """ 500 pass 501 502 def __mul__(self, n): 503 """ x.__mul__(n) <==> x*n """ 504 pass 505 506 @staticmethod # known case of __new__ 507 def __new__(S, *more): 508 """ T.__new__(S, ...) -> a new object with type S, a subtype of T """ 509 pass 510 511 def __ne__(self, y): 512 """ x.__ne__(y) <==> x!=y """ 513 pass 514 515 def __repr__(self): 516 """ x.__repr__() <==> repr(x) """ 517 pass 518 519 def __rmod__(self, y): 520 """ x.__rmod__(y) <==> y%x """ 521 pass 522 523 def __rmul__(self, n): 524 """ x.__rmul__(n) <==> n*x """ 525 pass 526 527 def __sizeof__(self): 528 """ S.__sizeof__() -> size of S in memory, in bytes """ 529 pass 530 531 def __str__(self): 532 """ x.__str__() <==> str(x) """ 533 pass 534 535 str 536 537 str Code
2.字符串常用方法:
(1)capitalize:将首字母大写
1 >>> name = ‘hello‘ 2 >>> name.capitalize() 3 ‘Hello‘
(2)center/ljust/rjust:固定字符串长度,居中/居左/居右 ,下面是使用示例,当然没有正常人会上来就这么用,一般用在打印列表和字典的时候整理格式。
1 >>> str1=‘zhenghao love xiaokai‘ 2 >>> str1.center(30,‘*‘) #设置格式左对齐,其余剩余部分由‘*’填充 3 ‘****zhenghao love xiaokai*****‘ 4 >>> str1.ljust(30, ) #设置格式左对齐,其余剩余部分由空格填充 5 ‘zhenghao love xiaokai ‘ 6 >>> str1.rjust(30,‘$‘) #设置格式左对齐,其余剩余部分由‘$’填充 7 ‘$$$$$$$$$zhenghao love xiaokai‘ 8 >>>
(3)count:子序列个数,用来统计一个字符串中包含指定子序列的个数。这个子序列可以是一个字符,也可以是多个字符~~
1 >>> str1 = ‘hello,world‘ 2 >>> str1.count(‘o‘) 3 2 4 >>> str1.count(‘he‘) 5 1
(4)encode/decode:编码/解码,如下左图,各个编码之间是不能直接转换的,计算机内存中默认存储的编码格式是unicode,所以当我们需要将编码在utf8和gbk之间转换的时候,都需要和unicode做操作。
我的终端编码是gbk编码的,当我创建一个string = ‘景‘时,string就被存储成gbk格式。此时我想把gbk格式转换成utf8格式,就要先将原gbk格式的string转换成unicode格式,然后再将unicode转换成utf8格式。如下右图,老师说,把这个字整乱码了我们的目的就达到了,哈~
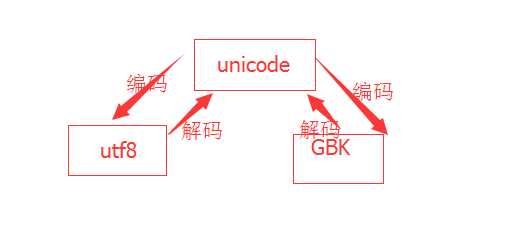
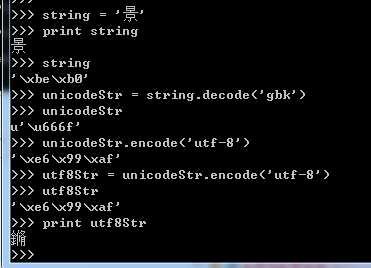
(5)endswith:是否以...(子串)结尾。这里的子串依然可以是一个或多个字符。
1 >>> str1 = ‘hello,Have a nice day‘ 2 >>> str1.endswith(‘day‘) 3 True
(6)expandtabs:将tab转换成空格,默认一个tab转换成8个空格。当然这里也可以自行指定转换成多少个空格,要不是怕写不下,我就指定它转成千八百个。。。
1 >>> name = ‘ E‘ 2 >>> name.expandtabs() 3 ‘ E‘ 4 >>> name.expandtabs(20) 5 ‘ E‘
(7)find:返回字符串中第一个子序列的下标。
rfind:和find用法一样,只是它是从右向左查找
index:和find的左右一致,只是find找不到的时候会返回-1,而index找不到的时候会报错
值得注意的是,当我们在一个字符串中查找某一个子序列的时候,如果这个字符串中含有多个子序列,只会返回第一个找到的下标,不会返回其他的。
3 4 4 >>> name.find(‘t‘) 5 -1
6 >>> name.index(‘e‘) 7 1 8 >>> name.index(‘t‘) 9 10 Traceback (most recent call last): 11 File "<pyshell#234>", line 1, in <module> 12 name.index(‘t‘) 13 ValueError: substring not found
(8)format:各种格式化,动态参数。
(9)isalnum/isalpha/isdigit/isspace/islower/istitle/isupper:是否是字母或数字/是否字母/是否数字/是否空格/是否小写/是否标题/是否全大写,总之都是一些判断的方法,返回的不是True就是False。。。
(10)partition/split:这两个方法都用来分割。
partition会将指定的子串串提取并将子串两侧内容分割,只匹配一次,并返回元祖;
split会根据指定子串,将整个字符串所有匹配的子串匹配到并剔除,将其他内容分割,返回数组。
1 >>> food = ‘apple,banana,chocolate‘ 2 >>> food.split(‘,‘) 3 [‘apple‘, ‘banana‘, ‘chocolate‘] 4 >>> food.partition(‘,‘) 5 (‘apple‘, ‘,‘, ‘banana,chocolate‘)
(11)replace:替换。会替换字符串中所有符合条件的子串。。。原谅我的chinglish。。。
1 >>> str1 = ‘I\‘m Rita,Do you remember,Rita?‘ 2 >>> str1.replace(‘Rita‘,‘Eva‘) 3 "I‘m Eva,Do you remember,Eva?"
(12)swapcase:大写变小写,小写变大写
1 >>> str1 = ‘I\‘m Eva‘ 2 >>> str1.swapcase() 3 "i‘M eVA"
(13)translate:替换,删除字符串。这个方法的使用比较麻烦,在使用前需要引入string类,并调用其中的maketrans方法建立映射关系。这样,在translate方法中,加入映射参数,就可以看到效果了。如下‘aeiou’分别和‘12345’建立了映射关系,于是在最后,aeiou都被12345相应的替换掉了,translate第二个参数是删除,它删除了所有的‘.’
1 >>> in_tab = ‘aeiou‘ 2 >>> out_tab = ‘12345‘ 3 >>> import string 4 >>> transtab = string.maketrans(in_tab,out_tab) 5 >>> str = ‘this is a translate example...wow!‘ 6 >>> str1 = ‘this is a translate example...wow!‘ 7 >>> print str1.translate(transtab,‘..‘) 8 th3s 3s 1 tr1nsl1t2 2x1mpl2w4w!
3.字符串转义字符:
如果字符串内部既包含‘又包含"怎么办?可以用转义字符\来标识,比如:
‘I\‘m \"OK\"!‘
表示的字符串内容是:
I‘m "OK"!
转义字符\可以转义很多字符,比如\n表示换行,\t表示制表符,字符\本身也要转义,所以\\表示的字符就是\,可以在Python的交互式命令行用print()打印字符串看看:
1 >>> print(‘I\‘m ok.‘) 2 I‘m ok. 3 >>> print(‘I\‘m learning\nPython.‘) 4 I‘m learning 5 Python. 6 >>> print(‘\\\n\\‘) 7 8 \
如果字符串里面有很多字符都需要转义,就需要加很多\,为了简化,Python还允许用r‘‘表示‘‘内部的字符串默认不转义,可以自己试试:
1 >>> print(‘\\\t\\‘) 2 \ 3 >>> print(r‘\\\t\\‘) 4 \\\t\\
如果字符串内部有很多换行,用\n写在一行里不好阅读,为了简化,Python允许用‘‘‘...‘‘‘的格式表示多行内容,可以自己试试:
1 >>> print(‘‘‘line1 2 3 ... line2 4 ... line3‘‘‘) 5 line1 6 line2 7 line3
上面是在交互式命令行内输入,注意在输入多行内容时,提示符由>>>变为...,提示你可以接着上一行输入。如果写成程序,就是:
1 print(‘‘‘line1 2 line2 3 line3‘‘‘)
多行字符串‘‘‘...‘‘‘还可以在前面加上r使用,请自行测试。
4.字符串格式化,占位符:
在Python中,采用的格式化方式和C语言是一致的,用%实现,举例如下:
1 >>> ‘Hello, %s‘ % ‘world‘ 2 ‘Hello, world‘ 3 >>> ‘Hi, %s, you have $%d.‘ % (‘zh‘, 1000000) 4 ‘Hi, zh, you have $1000000.‘
你可能猜到了,%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
常见的占位符有:
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
其中,格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
1 >>> ‘%2d-%02d‘ % (3, 1) 2 ‘ 3-01‘ 3 >>> ‘%.2f‘ % 3.1415926 4 ‘3.14‘
如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串:
1 >>> ‘Age: %s. Gender: %s‘ % (25, True) 2 ‘Age: 25. Gender: True’
有些时候,字符串里面的%是一个普通字符怎么办?这个时候就需要转义,用%%来表示一个%:
1 >>> ‘growth rate: %d %%‘ % 7 2 ‘growth rate: 7 %‘
其实,上面这种格式化方法,常常被认为是太“古老”了。因为在 Python 中还有新的格式化方法。
1 >>> s1 = "I like {}".format("python") 2 >>> s1 3 ‘I like python‘ 4 >>> s2 = "Suzhou is more than {} years. {} lives in here.".format(2500, "qiwsir") 5 >>> s2 6 ‘Suzhou is more than 2500 years. qiwsir lives in here.‘
这就是 Python 非常提倡的 string.format()的格式化方法,其中 {} 作为占位符。
这种方法真的是非常好,而且非常简单,只需要将对应的东西,按照顺序在 format 后面的括号中排列好,分别对应占位符 {} 即可。我喜欢的方法。
如果你觉得还不明确,还可以这样来做。
1 >>> print "Suzhou is more than {year} years. {name} lives in here.".format(year=2500, name="qiwsir") 2 Suzhou is more than 2500 years. qiwsir lives in here.
真的很简洁,堪称优雅。
其实,还有一种格式化的方法,被称为“字典格式化”,这里仅仅列一个例子,如果看官要了解字典的含义,本教程后续会有的。
1 >>> lang = "Python" 2 >>> print "I love %(program)s"%{"program":lang} 3 I love Python
列举了三种基本格式化的方法,你喜欢那种?我推荐:string.format()
5.字符串的索引和切片
例如这样一个字符串 Python,它就是几个字符:P,y,t,h,o,n,排列起来。这种排列是非常严格的,不仅仅是字符本身,而且还有顺序,换言之,如果某个字符换了,就编程一个新字符串了;如果这些字符顺序发生变化了,也成为了一个新字符串。在 Python 中,把像字符串这样的对象类型(后面还会冒出来类似的其它有这种特点的对象类型,比如列表),统称为序列。顾名思义,序列就是“有序排列”。
1 >>> str=‘python‘ 2 >>> str[0] 3 ‘p‘ 4 >>> str[:4] 5 ‘pyth‘ 6 >>> str[:] 7 ‘python‘ 8 >>> str[1:4] 9 ‘yth‘ 10 >>> str[-3:-1] 11 ‘ho‘ 12 >>> str.index(‘t‘) 13 2 14 >>>
6.字符串连接
1 >>> a=‘三毛‘ 2 >>> s=‘荷西‘ 3 >>> z=a+s 4 >>> z 5 ‘\xe4\xb8\x89\xe6\xaf\x9b\xe8\x8d\xb7\xe8\xa5\xbf‘ 6 >>> print(z) 7 三毛荷西 8 >>>