爬虫学习的一点心得
任务:抓取某小说网站小说并下载
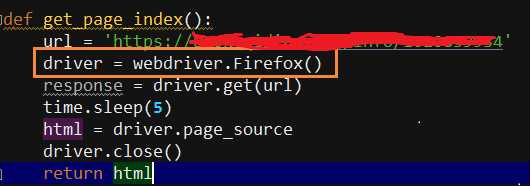
抓取:selenium
解析:xpath,正则表达式
遇到的问题:
1.用requests抓取的时候,无论如何修改请求头,抓取的源代码明显缺失严重,特别是小说文本、链接地址等重要信息都无法获取,最后万不得已只能使用
selenium模拟浏览器(我这里使用的火狐浏览器)进行抓取成功
python爬虫学习之起点小说抓取
原文:https://www.cnblogs.com/tian2B/p/10878274.html