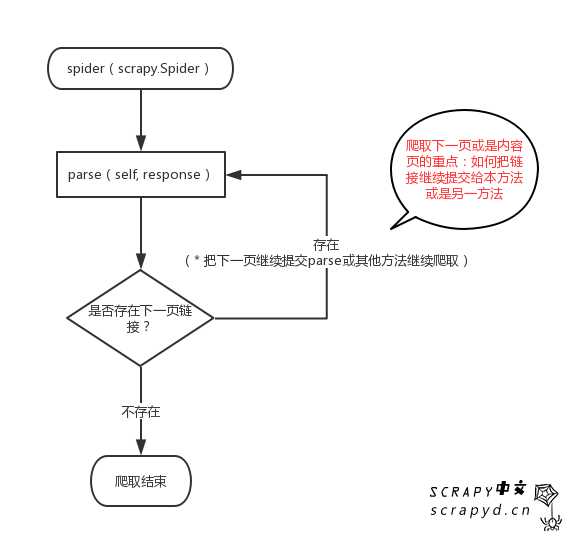
1. 检测当前页是否存在“下一页”
2. 如果存在,把“下一页”的链接交给本方法或者其他方法
3. 如果不存在,结束
图示
def parse(self, response): mingyan = response.css(‘div.quote‘) for v in mingyan: text = v.css(‘.text::text‘).extract_first() tags = v.css(‘.tags .tag::text‘).extract() tags = ‘,‘.join(tags) fileName = ‘%s-语录.txt‘ % tags with open(fileName, "a+") as f: f.write(text) f.write(‘\n‘) f.write(‘标签:‘ + tags) f.write(‘\n-------\n‘) f.close()
next_page = response.css(‘li.next a::attr(href)‘).extract_first() if next_page is not None: next_page = response.urljoin(next_page) yield scrapy.Request(next_page, callback=self.parse)
在解析器中,检测下一页的链接,如果存在,就在解析器中继续爬取,这是一种递归实现分页爬取的策略。
当然你可以用其他方法。
注意,这只是一种思路,并不是绝对正确的方法,有些网站即使没有下一页链接,它也会有href,可能会href到第一页,要根据实际情况制定策略。
原文:https://www.cnblogs.com/yanshw/p/10844768.html