scrapy 是个爬虫框架,是由python编写的,用法类似 django 框架。
在开始爬虫之前,先创建工程
scrapy startproject projectname
目录结构如下图
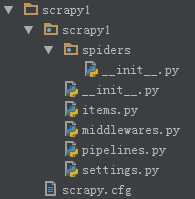
文件说明
顶层的scrapy1是工程名
第二层的scrapy1相当于app名
scrapy.cfg 工程的配置信息,目的是使得工程能够正常运行
# Automatically created by: scrapy startproject # # For more information about the [deploy] section see: # https://scrapyd.readthedocs.io/en/latest/deploy.html [settings] default = scrapy1.settings [deploy] #url = http://localhost:6800/ project = scrapy1
spiders 用来创建具体的爬虫
settings.py 具体爬虫的配置文件,相当于django中app的settings
BOT_NAME = ‘scrapy1‘ SPIDER_MODULES = [‘scrapy1.spiders‘] NEWSPIDER_MODULE = ‘scrapy1.spiders‘
items.py 设置数据存储的模板,用于结构化数据,相当于django中app的model
import scrapy class Scrapy1Item(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass
pipelines.py 数据处理行为,如数据持久化
class Scrapy1Pipeline(object): def process_item(self, item, spider): return item
middlewares.py 中间件
可以手动创建,跟创建普通py文件一样;
也可以命令行创建;
进入工程目录,运行
scrapy genspider baidu baidu.com
baidu 表示文件名,也是爬虫名,也是爬虫类名;baidu.com是网站域名
class BaiduSpider(scrapy.Spider): name = ‘baidu‘ allowed_domains = [‘baidu.com‘] start_urls = [‘http://baidu.com/‘]
allowed_domains 表示搜索域,如果 start_urls 与 不在搜索域内,不会发送请求,但是经我实验,貌似也可以
1. 爬虫类需要继承自 scrapy的爬虫类型,如 scrapy.Spider
2. 必须显示定义 name 类属性,表示爬虫名;
3. 明确爬取的网址;
4. 重写 scrapy 的 start_requests 方法,用于下载页面,这个方法内显示调用解析器,网址也可以写在这个方法内(可选)
5. 解析器定义(也可选,如果没有,只下载就是了)
class Kachezhijia(scrapy.Spider): # 需要继承scrapy.Spider类 name = "kache" # 定义蜘蛛名 def start_requests(self): ‘‘‘ 下载器‘‘‘ # 爬取的链接 urls = [‘https://bbs.360che.com/thread-3119294-1-1.html‘] for url in urls: yield scrapy.Request(url=url, callback=self.parse) # 爬取到的页面提交给parse方法处理 def parse(self, response): ‘‘‘ 解析器‘‘‘ # 这里只是做个简单存储 page = response.url.split("/")[-2] filename = ‘mingyan-%s.html‘ % page with open(filename, ‘wb‘) as f: f.write(response.body) self.log(‘保存文件: %s‘ % filename) # 调用父类的log方法
如果不重写 start_requests,会运行父类的该方法,需要在 start_urls 中定义url;
如果不重写 start_requests ,解析器的名字必须为 parse,框架自动调用,如果不是parse,无法调用,如果重写了 start_requests,解析器名字随意,反正是显示调用
class Test2Spider(scrapy.Spider): name = ‘test2‘ allowed_domains = [‘baidu.com‘] start_urls = [‘https://bbs.360che.com/thread-3119294-1-1.html‘] def parse(self, response): ‘‘‘ 解析器‘‘‘ filename = ‘test2.html‘ with open(filename, ‘wb‘) as f: f.write(response.body) self.log(‘保存文件: %s‘ % filename) # 调用父类的log方法
爬虫文件与items.py、pipelines.py 的关系
爬虫文件 返回 item,【item的格式是item.py中的类格式,类似字典】
这个item会被交给 scrapy 引擎,
引擎把item交给pipelines.py,
pipelines 会判断item是否是item.py的类型,如果是,会执行后续操作,然后必须返回item,【如果不返回,整个下载存储的链条会断掉】
item被交给后面的pipelines,如果只有一个pipelines,那item被交给 scrapy 引擎,引擎告知解析器。
进入工程目录,运行
scrapy crawl test2
注意最后的 test2 是爬虫名,不是文件名,也不是爬虫类名
这里其实已经可以爬了,但是还有更专业的作法。
上面是解析的同时已经存储了,但是可以分开做。
items.py,设定数据格式
class TianqiItem(scrapy.Item): # define the fields for your item here like: test = scrapy.Field()
如存储数据
class TianqiPipeline(object): def __init__(self): self.f = open(‘save.txt‘, ‘wb‘) def process_item(self, item, spider): self.f.write(str(dict(item))) return item def close_spider(self, spider): # 爬虫结束时执行该方法 self.f.close()
要执行管道需要在settings中进行设置
原文:https://www.cnblogs.com/yanshw/p/10843403.html