主要是阅读以下博文的总结:
https://zhuanlan.zhihu.com/p/31547842
https://www.zhihu.com/question/68482809/answer/264632289
https://blog.csdn.net/thriving_fcl/article/details/73381217
https://kexue.fm/archives/4765
http://ir.dlut.edu.cn/news/detail/486
这篇主要讲的是soft-Attention
在不同的论文中Attention分为soft Attention 与Hard Attention、Global Attention和Local Attention以及Self Attention以及组合Attention中的层次化Attention等等
soft Attention的本质:
从概念上理解,把Attention仍然理解为从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息,这种思路仍然成立。聚焦的过程体现在权重系数的计算上,权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
对其理解可以参考如图:
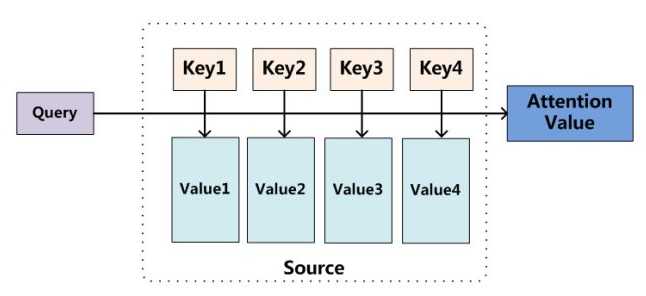
我们可以这样来看待Attention机制(参考上图):将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。即可以将其本质思想改写为如下公式:
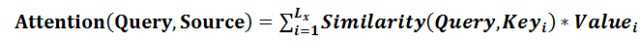
也可以将Attention机制看作一种软寻址(Soft Addressing):Source可以看作存储器内存储的内容,元素由地址Key和值Value组成,当前有个Key=Query的查询,目的是取出存储器中对应的Value值,即Attention数值。通过Query和存储器内元素Key的地址进行相似性比较来寻址,之所以说是软寻址,指的不像一般寻址只从存储内容里面找出一条内容,而是可能从每个Key地址都会取出内容,取出内容的重要性根据Query和Key的相似性来决定,之后对Value进行加权求和,这样就可以取出最终的Value值,也即Attention值。所以不少研究人员将Attention机制看作软寻址的一种特例,这也是非常有道理的。
至于Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理;这样,可以将Attention的计算过程抽象为如图展示的三个阶段:
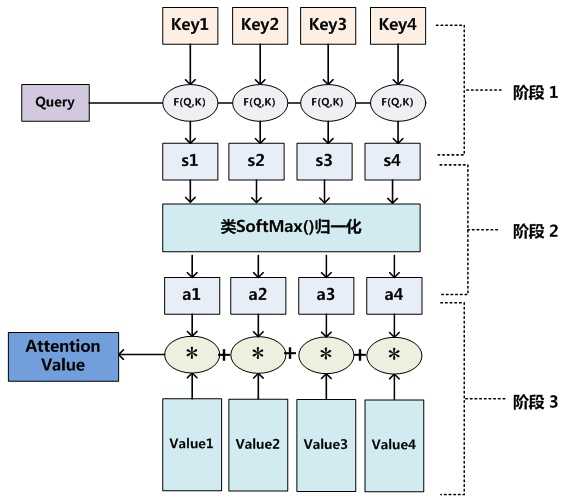
在第一个阶段,可以引入不同的函数和计算机制,根据Query和某个Key_i,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,即如下方式:
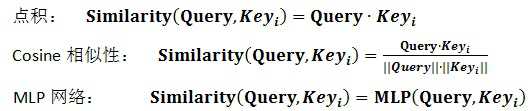
第一阶段产生的分值根据具体产生的方法不同其数值取值范围也不一样,第二阶段引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:
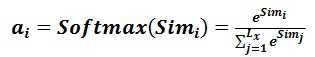
第二阶段的计算结果a_i即为value_i对应的权重系数,然后进行加权求和即可得到Attention数值:
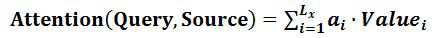
通过如上三个阶段的计算,即可求出针对Query的Attention数值,目前绝大多数具体的注意力机制计算方法都符合上述的三阶段抽象计算过程。
Q,K,V理解以及运算:
上面提到的query与key之间计算相似度有许多方法,如dot、general、concat和MLP等方式,具体公式如下所示。而attention模型抽象为query、key和value之间的相似度计算,总共有3个阶段。第一阶段:query与keyi使用特定的相似度函数计算相似度,得到si;第二阶段:对si进行softmax()归一化得到ai;第三阶段,将ai与valuei对应相乘再求和,得到最终的attention value。其实对比传统的attention公式,我们可以看出,这两套公式还是很像的。

分类模型中具体代码
#属于soft-Attention,即为对于LSTM的输出层所有节点都计算attention with tf.name_scope(‘attention‘), tf.variable_scope(‘attention‘): attention_w = tf.Variable(tf.truncated_normal([FLAGS.n_hidden, attention_size], stddev=0.1), name=‘attention_w‘) attention_b = tf.Variable(tf.constant(0.1, shape=[attention_size]), name=‘attention_b‘) u_list = [] #以下部分为相似度的计算,对每个时间序列计算相似度 #用于衡量encoder端的位置j个词,对于decoder端的位置i个词的对齐程度(影响程度) #使用的是最简单且最常用的对齐模型是dot product乘积矩阵 for t in xrange(FLAGS.sentence_length): #由于使用的是soft Attention,单层时attention_size和隐藏层神经元个数相等故outputs维度没变 #outputs[t]是二维的Tensor,[batch_size*lstm隐层节点的个数] u_t = tf.tanh(tf.matmul(outputs[t], attention_w) + attention_b) #u_t是一个二维的Tensor,[batch_size*attention_size],在这里用的soft-Attention,即为对于LSTM的输出层所有节点都计算attention u_list.append(u_t) u_w = tf.Variable(tf.truncated_normal([attention_size,1], stddev=0.1), name=‘attention_uw‘) #每个时间序列注意力权值的计算(计算得到对一个批次的各条数据具体的注意力权值分配) attn_z = [] for t in xrange(FLAGS.sentence_length): #z_t是[batch_size*1] z_t = tf.matmul(u_list[t], u_w) attn_z.append(z_t) # transform to batch_size * sequence_length # 获得对输入的每个序列应该给予的注意力权重 attn_zconcat = tf.concat(attn_z, axis=1) #这里采用softmax的原因是: #一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布 #另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。 #alpha依然是batch_size * sequence_length只是对批次中每条数据进行了归一化 alpha = tf.nn.softmax(attn_zconcat) # 和注意力权值相乘得到注意力值 #在给予对原文语义的表述进行权重相乘的更新,得到对原文更加合理的的带有注意力的语义表述之前,先进行注意力权重值维度的转换 #tf.transpose(alpha, [1,0])转换为时间批次优先的 # transform to sequence_length * batch_size * 1 , same rank as outputs alpha_trans = tf.reshape(tf.transpose(alpha, [1,0]), [FLAGS.sentence_length, -1, 1]) #输出和权值相乘,使得重要的特征更加突出,不重要的减小其影响 #这里进行的是元素相乘不是矩阵相乘 # outputs的shape为[sentence_length,batch_size,n_hidden] # alpha_trans的shape为[sentence_length * batch_size * 1] #直接相乘outputs * alpha_trans维度为[sentence_length,batch_size,n_hidden] # final_output shape: (batch_size, n_hidden==attn_size) # 最后结果的计算,得到的是对原文赋予权重之后的表示 final_output = tf.reduce_sum(outputs * alpha_trans,0)
从以上代码来看:
至于Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性,第二个阶段对第一阶段的原始分值进行归一化处理。
一些思考:
在文本分类中k、v都是网络层的输出,q是随机生成的向量。第一个过程的第一个阶段,会先后经过一次非线性变换和线性变换,其中的权重系数W都是随机的(为什么要这样做,考虑该如何获得各特征的重要程度,可以通过神经网络去学习,经过训练后的W会倾向于重要的特征);
attention其实就是学出一个权重分布,再拿这个权重分布施加在原来的特征之上,给重要的特征分布较大的权重,为不重要的特征分布较小的特征,以此来加大重要特征的影响。一方面在网络输出层后再加个attention是因为对于文本分类而言对于最后的类别而言不同的特征可能所起的作用不同。但是另一方面,在NLP中常用的LSTM其输出门就有一定的特征选择作用了,输出的为对类别决定性更大的特征,所以在LSTM后再加Attention似乎意义不大。
Attention设计之初用于seq2seq,较为典型的Attention为乘性Attention和加性Attention
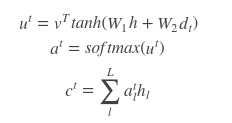
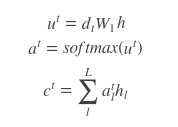
原文:https://www.cnblogs.com/dyl222/p/10885947.html