Apriori算法是经典的挖掘频繁项集和关联规则的数据挖掘算法。Apriori算法的名字正是基于这样的事实:算法使用频繁项集性质的先验性质,即频繁项集的所有非空子集也一定是频繁的。Apriori算法使用一种称为逐层搜索的迭代方法,其中k项集用于探索(k+1)项集。首先,通过扫描数据库,累计每个项的计数,并收集满足最小支持度的项,找出频繁1项集的集合。该集合记为L1。然后,使用L1找出频繁2项集的集合L2,使用L2找出L3,如此下去,直到不能再找到频繁k项集。每找出一个Lk需要一次数据库的完整扫描。Apriori算法使用频繁项集的先验性质来压缩搜索空间。
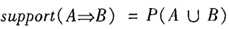
其中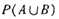 表示事务包含集合A和B的并(即包含A和B中的每个项)的概率。注意与P(A or B)区别,后者表示事务包含A或B的概率。
表示事务包含集合A和B的并(即包含A和B中的每个项)的概率。注意与P(A or B)区别,后者表示事务包含A或B的概率。
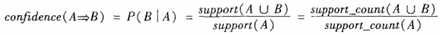
输入:数据集合D,支持度阈值αα
输出:最大的频繁k项集
1)扫描整个数据集,得到所有出现过的数据,作为候选频繁1项集。k=1,频繁0项集为空集。
2)挖掘频繁k项集
a) 扫描数据计算候选频繁k项集的支持度
b) 去除候选频繁k项集中支持度低于阈值的数据集,得到频繁k项集。如果得到的频繁k项集为空,则直接返回频繁k-1项集的集合作为算法结果,算法结束。如果得到的频繁k项集只有一项,则直接返回频繁k项集的集合作为算法结果,算法结束。
c) 基于频繁k项集,连接生成候选频繁k+1项集。
3) 令k=k+1,转入步骤2。
原文:https://www.cnblogs.com/danhuang101/p/10890407.html