这里简单记录和概述学习目标检测算法的心得,尽可能的详细一些,但限于写博客的一些语法和格式不是很好,所以请阅读者见谅!
概述:1、什么是目标检测
2、目标检测任务描述
2.1、目标检测算法分类(接下来我会更新常见的目标检测算法原理)
2.2、目标检测的常见指标
2.3、目标定位的简单实现
1、什么是目标检测
识别图片中有哪些物体以及物体的位置(坐标位置)

什么是物体
即图像中存在的物体对象,但是能检测哪些物体会受到人为设定限制。
目标检测中能检测出来的物体取决于当前任务(数据集)需要检测的物体有哪些。假设我们的目标检测模型定位是检测动物(牛、羊、猪、狗、猫五种结果),那么模型对任何一张图片输出结果不会输出鸭子、书籍等其它类型结果。
什么是位置
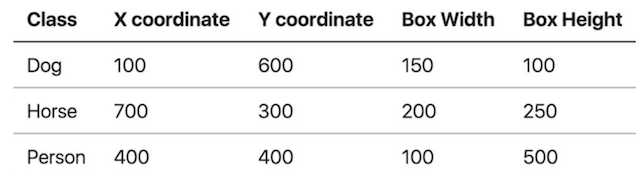
目标检测的位置信息一般由两种格式(以图片左上角为原点(0,0)):
假设这个图像是1000x800,所有这些坐标都是构建在像素层面上:

中心点坐标结果如下:
2、目标检测任务描述
2.1 目标检测算法分类
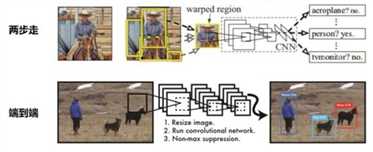
两步走的目标检测:先进行区域推荐,而后进行目标分类
端到端的目标检测:采用一个网络一步到位
2.2 目标检测的任务
2.2.1 分类原理
先来回顾下分类的原理,这是一个常见的CNN组成图,输入一张图片,经过其中卷积、激活、池化相关层,最后加入全连接层达到分类概率的效果

在训练的时候需要计算每个样本的损失,那么CNN做分类的时候使用softmax函数计算结果,损失为交叉熵损失
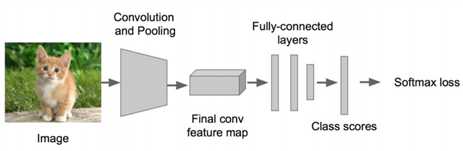
对于目标检测来说不仅仅是分类这样简单的一个图片输出一个结果,而且还需要输出图片中目标的位置信息,所以从分类到检测,如下图标记了过程:


2.3 检测的任务
分类:

定位:

其中我们得出来的(x,y,w,h)有一个专业的名词,叫做bounding box(bbox).
2.3.1 两种Bounding box名称
在目标检测当中,对bbox主要由两种类别。
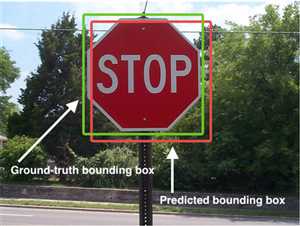
一般在目标检测当中,我们预测的框有可能很多个,真实框GT也有很多个。
| 任务 | description | 输入 | 输出 | 评价标准 |
|---|---|---|---|---|
|
Detection and Localization (检测和定位) |
在输入图片中找出存在的物 体类别和位置(可能存在多种物体) |
图片(image ) |
类别标签(categories)和 位置(bbox(x,y,w,h)) |
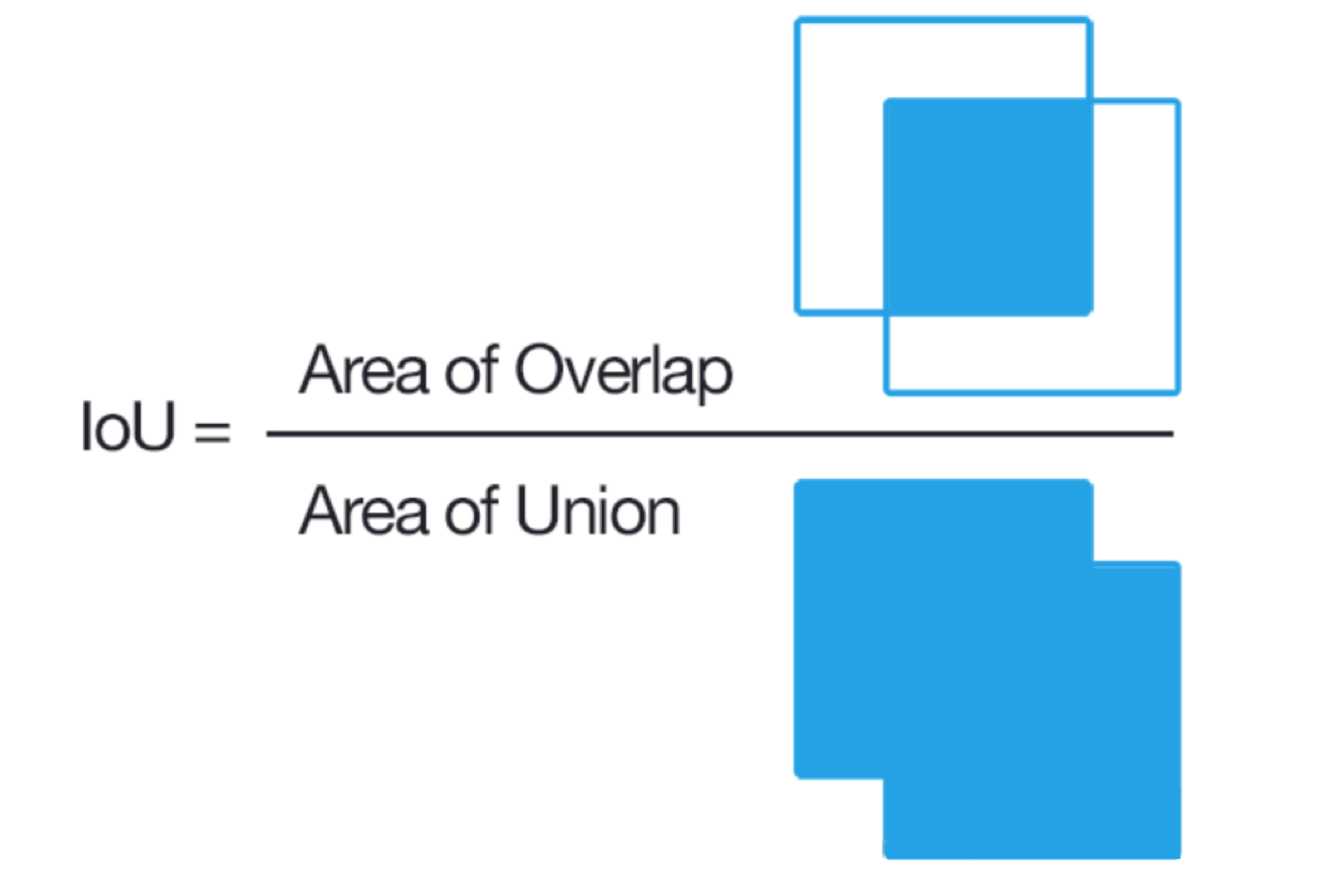
IoU (Intersection over Union) mAP (Mean Average Precision) |
2.5 目标定位的简单实现
在分类的时候我们直接输出各个类别的概率,如果再加上定位的话,我们可以考虑在网络的最后输出加上位置信息。
2.5.1 回归位置
增加一个全连接层,即为FC1、FC2
FC1:作为类别的输出
FC2:作为这个物体位置数值的输出
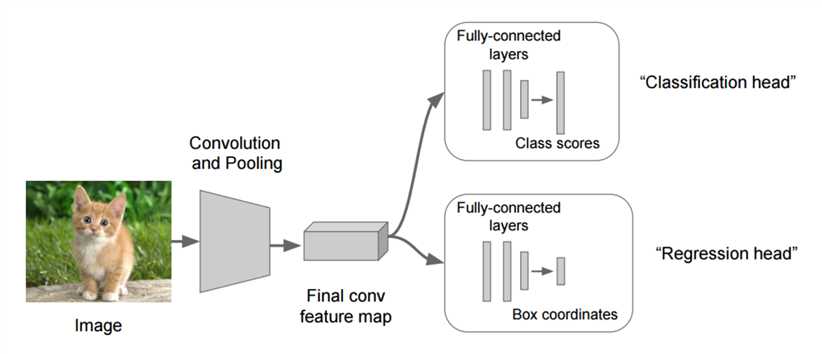
假设有10个类别,输出[p1,p2,p3,...,p10],然后输出这一个对象的四个位置信息[x,y,w,h]。同理知道要网络输出什么,如果衡量整个网络的损失
如下图所示

2.5.2 位置数值的处理
对于输出的位置信息是四个比较大的像素大小值,在回归的时候不适合。目前统一的做法是,每个位置除以图片本身像素大小。
假设以中心坐标方式,那么x = x/x_image,y/y_image, w/x_image,h/y_image,也就是这几个点最后都变成了0~1之间的值(归一化)。
原文:https://www.cnblogs.com/kongweisi/p/10894415.html