4.1 xml库
https://cuiqingcai.com/5545.html
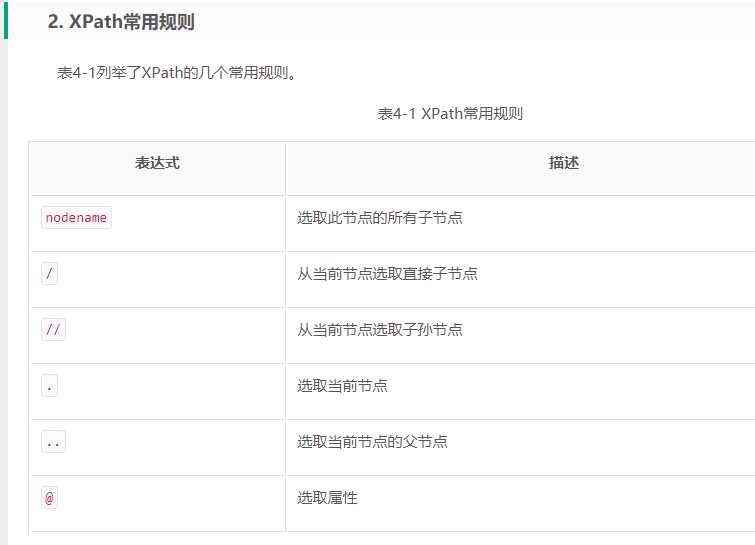
XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言。它最初是用来搜寻XML文档的
lxml 操作xml
from lxml import etree
# https://cuiqingcai.com/5545.html
text = ‘‘‘
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</di>
‘‘‘
html=etree.HTML(text) #调用HTML类进行初始化构造了一个XPath解析对象;etree模块可以自动修正HTML文本
print(html)
result=etree.tostring(html) #方法即可输出修正后的HTML代码,但是结果是bytes类型。这里利用decode()方法将其转成str类型
print(result.decode("utf-8"))
#另一中方式解析 html
print(‘----------------------------------------------------------‘)
html=etree.parse(‘./test.html‘,etree.HTMLParser())
result=etree.tostring(html)
print(result.decode())
html_xpath=html.xpath(‘//*‘) #获取对应节点的内容
print(html_xpath)

原文:https://www.cnblogs.com/x2x3/p/10887388.html