在开发工具内获取“请求头”来伪装成浏览器,以便更好地抓取数据
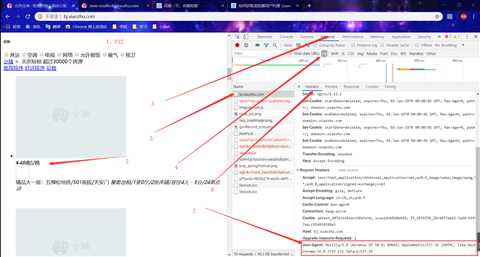
!/usr/bin/env python -*- encoding:UTF-8 -*- import requests headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36‘ } res = requests.get(‘http://bj.xiaozhu.com/‘,headers=headers) # get方法加入请求头 try: print(res.text) except ConnectionError: print(‘拒绝连接‘) # 通过BeautiSoup库解析得到的Soup文档是标准结构化数据比上面的更好 import requests from bs4 import BeautifulSoup headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36‘ } res = requests.get(‘http://bj.xiaozhu.com/‘,headers=headers) # get方法加入请求头 try: soup = BeautifulSoup(res.text, ‘html.parser‘) print(soup.prettify()) except ConnectionError: print(‘拒绝连接‘)
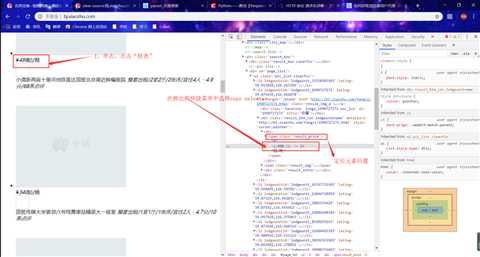

更新后:
price = soup.select(‘#page_list > ul > li:nth-child(1) > div.result_btm_con.lodgeunitname > div:nth-child(1) > ‘ ‘span.result_price > i‘)
原文:https://www.cnblogs.com/King-boy/p/10901389.html