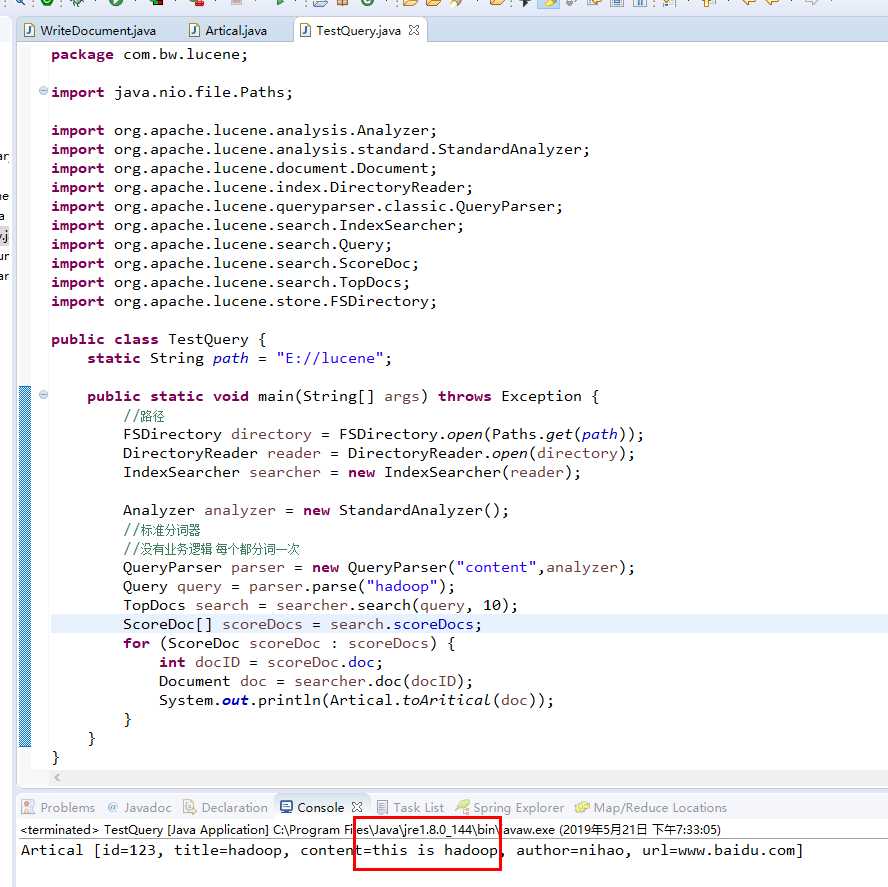
取值的时候 得到的 是document对象 将他转换成自己的对象 , 然后 在读取
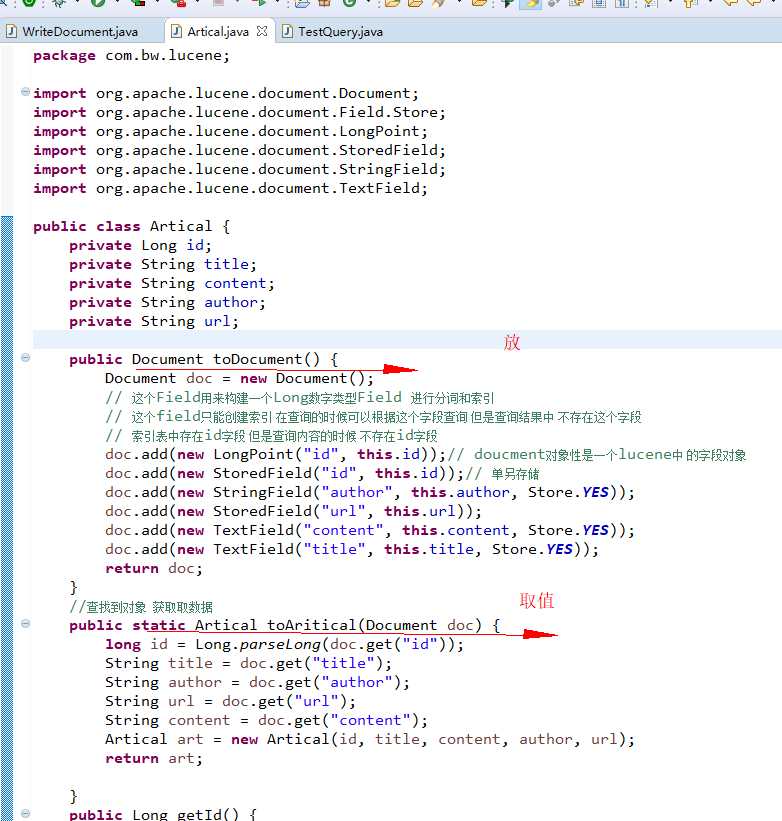
取值的类
package com.bw.lucene; import java.nio.file.Paths; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.queryparser.classic.QueryParser; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.FSDirectory; public class TestQuery { static String path = "E://lucene"; public static void main(String[] args) throws Exception { //路径 FSDirectory directory = FSDirectory.open(Paths.get(path)); DirectoryReader reader = DirectoryReader.open(directory); IndexSearcher searcher = new IndexSearcher(reader); Analyzer analyzer = new StandardAnalyzer(); //标准分词器 //没有业务逻辑 每个都分词一次 QueryParser parser = new QueryParser("content",analyzer); Query query = parser.parse("hadoop"); TopDocs search = searcher.search(query, 10); ScoreDoc[] scoreDocs = search.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { int docID = scoreDoc.doc; Document doc = searcher.doc(docID); System.out.println(Artical.toAritical(doc)); } } }
原文:https://www.cnblogs.com/JBLi/p/10901745.html