1、JML的理论基础,应用工具链情况。
2、使用OpenJML部署SMT Solver进行验证。
3、部署JMLUnitNG/JMLUnit自动生成测试用例。
4、分析架构设计与重构迭代情况。
5、分析bug与修复情况。
6、对规格撰写的心得体会。
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。JML是一种行为接口规格语言(Behavior Interface Specification Language,BISL),基于Larch方法构建。BISL提供了对方法和类型的规格定义手段。所谓接口即一个方法或类型外部可见的内容。JML主要由Leavens教授在Larch上的工作,并融入了BetrandMeyer, John Guttag等人关于Design by Contract的研究成果。近年来,JML持续受到关注,为严格的程序设计提供了一套行之有效的方法。
JML有与之相关的一整套工具链。如OpenJML能够整合SMT solver等其他工具对代码是否符合JML规格进行静态检查。JMLUnit等工具可以自动生成与JML规格相对应的测试样例来对规格实现情况进行动态检查。总的来说,通过这些工具可以确保我们规格实现的正确性,由此确定我们过程性的模块的正确性,进而使我们对象设计拥有稳定安全的基础。
采用了一个较简单的Demo进行验证。
public class Demo { /*@ public normal_behaviour @ ensures \result == lhs / rhs; @*/ public static int devide(int lhs, int rhs) { return lhs / rhs; } public static void main(String[] args) { devide(166614514,1919810); } }
1、OpenJML格式检查结果如下(删去了正确形式中rhs右侧的分号)

2、SMT Solver静态检查(未完成,不断报玄学错误,,至今未能解决)
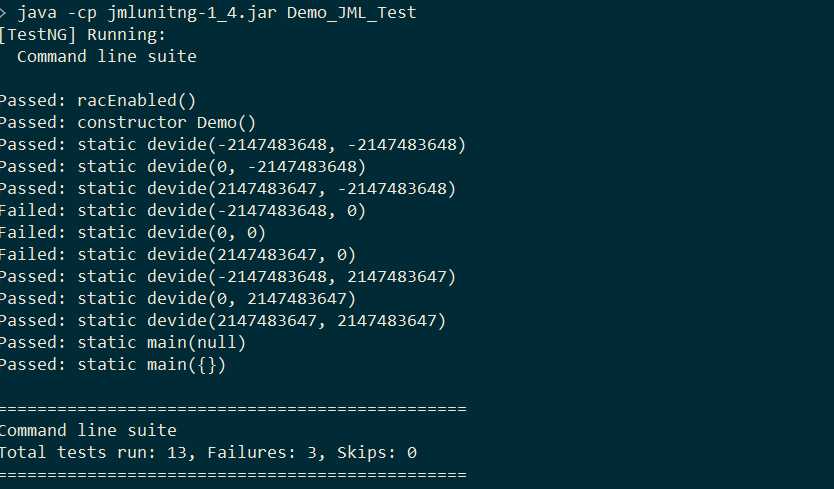
使用第二部分中的Demo,生成测试样例并测试的过程如下:
第一次要求设计PathContainer与Path。对于Path,采用ArrayList来存储单条路径,这样可以维持路径上结点的有序性,并且便于实现Iterable接口;同时在Path内设计一个HashMap来保存每个结点与其出现次数的映射关系,这样做是为了之后统计点数时分摊时间复杂度。
public class MyPath implements Path { private ArrayList<Integer> nodes; private HashMap<Integer, Integer> counter; }
在PathContainer中同样使用一个HashMap储存所有Path中的结点与数量的映射关系,这些都是为了服务这一次作业中复杂度最高的DISTINCT_NODE_COUNT指令,其它指令的复杂度都不算大。
第二次作业需要再PathContainer的基础上实现一个无向图管理结构,很容易观察到这样的图结构可以在PathContainer的基础上增加一个图的实现即可。我直接复用PathContainer的代码来实现新的功能。类图如下。
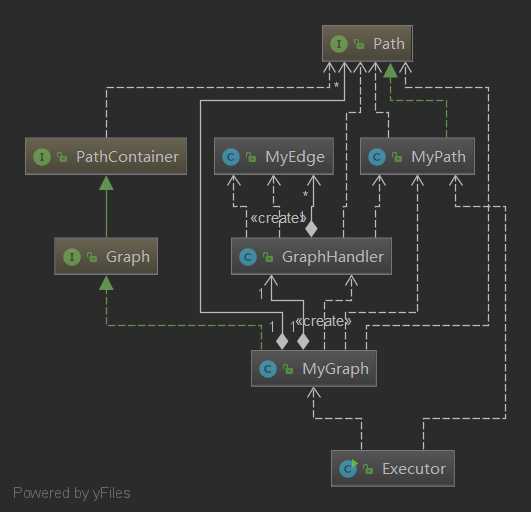
我增设了MyGraphManager类与MyEdge类,并在MyGraphManager中维护了一个HashMap保存MyEdge与数量的映射关系。在每次进行图结构变换操作时便更新这个HashMap,这样containsEdge操作便得以解决。之后,再基于这个HashMap维护一个二维数组,在每次更新edgeMap后,遍历这个HashMap的keyset更新这个数组(无向图的邻接矩阵表示)。封装一个Floyd算法,以这个邻接矩阵为输入,以计算结果矩阵为输出。之后,isConnected操作与shortestLength操作都可以通过查询结果矩阵得到结果。MyEdge构建成无向边的形式,减少存储与遍历的时间。
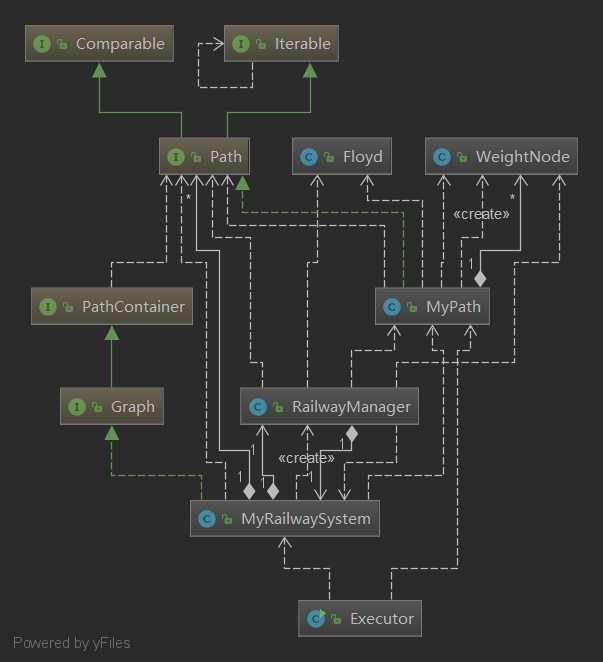
第三次作业为基于Path构建一个地铁管理系统。在本次作业中最关键的就是一个算法的构建:换乘权重的构建。算法不行的我最终参考了讨论区里的不拆点算法,具体来说,就是将各个Path中的结点序列构建为彼此可直达的无向图。然后将各个Path中的图集中到RailwayManager中的总图中。根据不同类的权重持续更新同边的最小权重。

public void renewValueInArray() { length = myRailwaySystem.getDistinctNodeCount(); setSpace(); Floyd.initialArray(length, arrForChangeLine, arrForShortestLength, arrForLeastPrice, arrForLeastUnpleasant); int cnt = 0; mapNodeToId.clear(); selfEdgeMap.clear(); for (Integer e : myRailwaySystem.getMapNodeToNum().keySet()) { mapNodeToId.put(e, cnt); cnt++; } for (Path path : myRailwaySystem.getMapIdToPath().values()) { MyPath myPath = (MyPath) path; HashSet<WeightNode> weightNodes = myPath.getWeightNodes(); for (WeightNode weightNode : weightNodes) { int startNode = weightNode.getStartNode(); int endNode = weightNode.getEndNode(); if (startNode != endNode) { int startInArr = mapNodeToId.get(startNode); int endInArr = mapNodeToId.get(endNode); int thatLength = weightNode.getShortestPathLength(); final int thatPrice = thatLength + 2; final int thatUnpleasant = weightNode.getUnpleasantValue() + 32; arrForChangeLine[startInArr][endInArr] = 1; arrForChangeLine[endInArr][startInArr] = 1; if (thatLength < arrForShortestLength[startInArr][endInArr]) { arrForShortestLength[startInArr][endInArr] = thatLength; arrForShortestLength[endInArr][startInArr] = thatLength; } if (thatPrice < arrForLeastPrice[startInArr][endInArr]) { arrForLeastPrice[startInArr][endInArr] = thatPrice; arrForLeastPrice[endInArr][startInArr] = thatPrice; } if (thatUnpleasant < arrForLeastUnpleasant[startInArr][endInArr]) { arrForLeastUnpleasant[startInArr][endInArr] = thatUnpleasant; arrForLeastUnpleasant[endInArr][startInArr] = thatUnpleasant; } } else { selfEdgeMap.add(startNode); } } } }
一共有四类权重的图。为了同时服务Path与RailwaySystem中的最短路计算,封装可变参数的Floyd算法。
public static void floyd(int len, int[][]... arrs) { for (int k = 0; k < len; k++) { for (int i = 0; i < len; i++) { if (i != k) { for (int j = 0; j < i; j++) { for (int[][] arr : arrs) { int value = arr[i][k] + arr[k][j]; if (arr[i][j] > value) { arr[i][j] = value; arr[j][i] = value; } } } } } } }
在经历过这三次作业,并大概读过互测时同组成员的代码与标程后,我能感受到我在层次分离上还做的不够。确切的说,我的作业基本都只能分为两层,即为存储层和计算层。存储层中存有一个计算层对象并将Path信息在每次更新时传给计算层,计算层将这些信息整合,得到结果并设置返回方法。我认为我在架构上还需要有不少的改进。首先我应该试着通过继承来将原有的功能次次延续,其次,不同类的图,不同的权重生成方法,不同的计算方法应该分别建模,使得各个功能之间解耦更加彻底。老实说,标程的建模方法是超乎我想象的。。。看完标程后我深深的感觉相比之下我只是在用Java的数据结构做算法题罢了。。。对对象建立的把握能力还是差之甚远
第一次作业,算是十分简单的了,但是由于我在实现compareTo方法时漏写了一个break。。。导致COMPARES_PATH指令无法得到正确结果使自己直接没能进入互测。讽刺的是这第一次作业我还使用了junit做了单元测试,结果由于偷懒只对PathContainer类做了测试导致这次作业的完全失败。。。
第二次作业,在Junit的基础上,我用python写了一个生成数量足够并且相互之间有联系的指令生成程序与对拍器,用它和舍友的程序做了对拍,最终结果是测出了室友的一个bug。。最终我的公测与互测都没有出问题。
第三次作业,我在进行junit测试时发现了我的containsEdge方法在fromNodeId与toNodeId相同时会有错误,即在自边不存在时也误计了进去。修复了这个bug后,我在公测与互测上都没有被测出问题。
对这个单元的契约式编程,我的最大的感受是,在编写程序时自己有了极强的目的性与针对性。回想起前两个单元的作业,有好几次我在写代码时几近陷入抓狂的边缘,原因便是写着写着突然就会有新的想法,或者有所遗漏导致写了又删,删了又写,而且有时候自己写完了也不是很清楚这些功能是不是实现了,有时候甚至忘了自己实现了哪些功能!这样当我最后整合时心里真的是绝望的。
但是按规格撰写程序给了我一个启示,那便是在工程开始之前就大概规划好全局的版图,包括哪些类,哪些方法,它们各自需要实现怎么样的功能等等。这样在真正开始coding之时自己才能做到心里有数,而且测试的时候也能十分的有针对性。想到什么写什么的方法真的是会使一个项目崩溃的。。。
原文:https://www.cnblogs.com/Leopordcfbuaa/p/10901496.html
