在上一篇文章了解了主从复制,主从复制本身的容错性很差,一旦master挂掉,只能进行手动故障转移,很难完美的解决这个问题
而本文讲解的sentinel可以解决这个问题
Redis sentinel示意图:
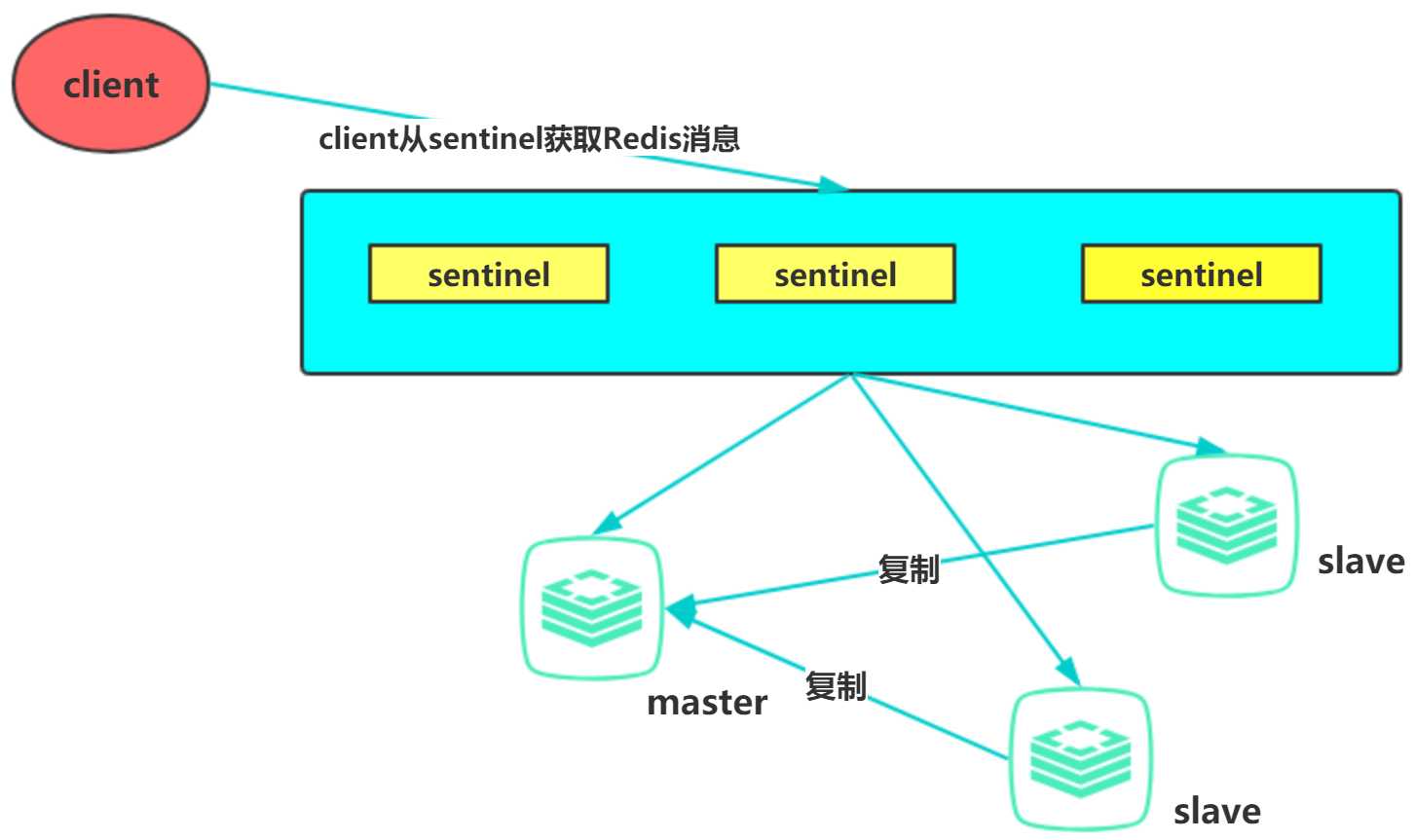
1、配置开启主从节点
2、配置开启sentinel监控主节点(sentinel是特殊的Redis)
master节点:port 6379
port 6379 daemonize yes //以守护进程的方式启动 pidfile "/var/run/redis_6379.pid" logfile "6379.log" dir "/var/local/redis/data"
两个slave节点:port 6380 6381
port 6380 daemonize yes //以守护进程的方式启动 pidfile "/var/run/redis_6380.pid" logfile "6380.log" dir "/var/local/redis/data" slaveof 127.0.0.1 6379
port 6381 daemonize yes //以守护进程的方式启动 pidfile "/var/run/redis_6381.pid" logfile "6381.log" dir "/var/local/redis/data" slaveof 127.0.0.1 6379
启动这三个Redis实例,查看6379的信息
redis-cli -a huluhulu -p 6379 info replication
role:master
connected_slaves:2
可以看到本身是master,连接了两个slave
port 26379 dir /usr/local/redis/data/ logfile 26379.log sentinel monitor mymaster 127.0.0.1 6379 2 //master名称为mymaster,2是指有两个sentinel认为master发生故障,就会发生故障转移 sentinel down-after-milliseconds mymaster 30000 //30s无法ping通master,就认为故障了 sentinel parallel-syncs mymaster 1 sentinel failover-timeout mymaster 180000
通过命令redis-sentinel sentinel-{port}.conf启动三个sentinel实例
通过info命令查看sentinel信息
sentinel可以监控多套master-slave
1、多个sentinel发现并确认master出现故障
2、选择一个sentinel作为领导
3、选取一个slave作为master
4、通知其它slave作为master的slave
5、通知客户端主从变化
6、等待老的master复活作为新的master的slave
第二步领导者选取:
原因:
只需要一个sentinel完成故障转移
过程:
通过命令询问别的sentinel节点选举自己成为领导者,只要没有投过票就会同意,只要超过quorum就可以成为领导者,如果有多个领导者,等待一段时间重新选取
第三步重新选择master的条件,依次判断,直到满足为止:
1)、通过slave-priority(如果机器配置不同,可以把高配机器priority设置更高)选择优先级高的
2)、选择offset最大的节点,和master的offset最接近,数据更加完整
3)、选择run_id最小的slave节点
对这个slave执行slaveof no one使其成为master
第六步对挂掉的master节点标记为slave,对其保持关注,一旦复活,也要成为新master的slave节点
sentinel通过三个定时任务对master进行异常判断和故障转移
1、每10s每个sentinel对master和slave执行info,以此来发现slave节点和确定主从关系
2、每2s每个sentinel通过master节点的channel和其它sentinel交换信息(pub/sub 发布订阅)
3、每1s每个sentinel对其它sentinel和redis执行ping
sentinel monitor <masterName> IP Port <quorum> quorum指法定人数,sentinel主观下线的人数达到法定人数就可以进行客观下线
主观下线:每个sentinel对Redis节点失败的"偏见"
客观下线:所有sentinel对Redis节点失败的"共识"
原文:https://www.cnblogs.com/huigelaile/p/10900008.html