这三个 Project 的代码由于不知名的原因无法生成测试文件,改用其他代码进行生成。
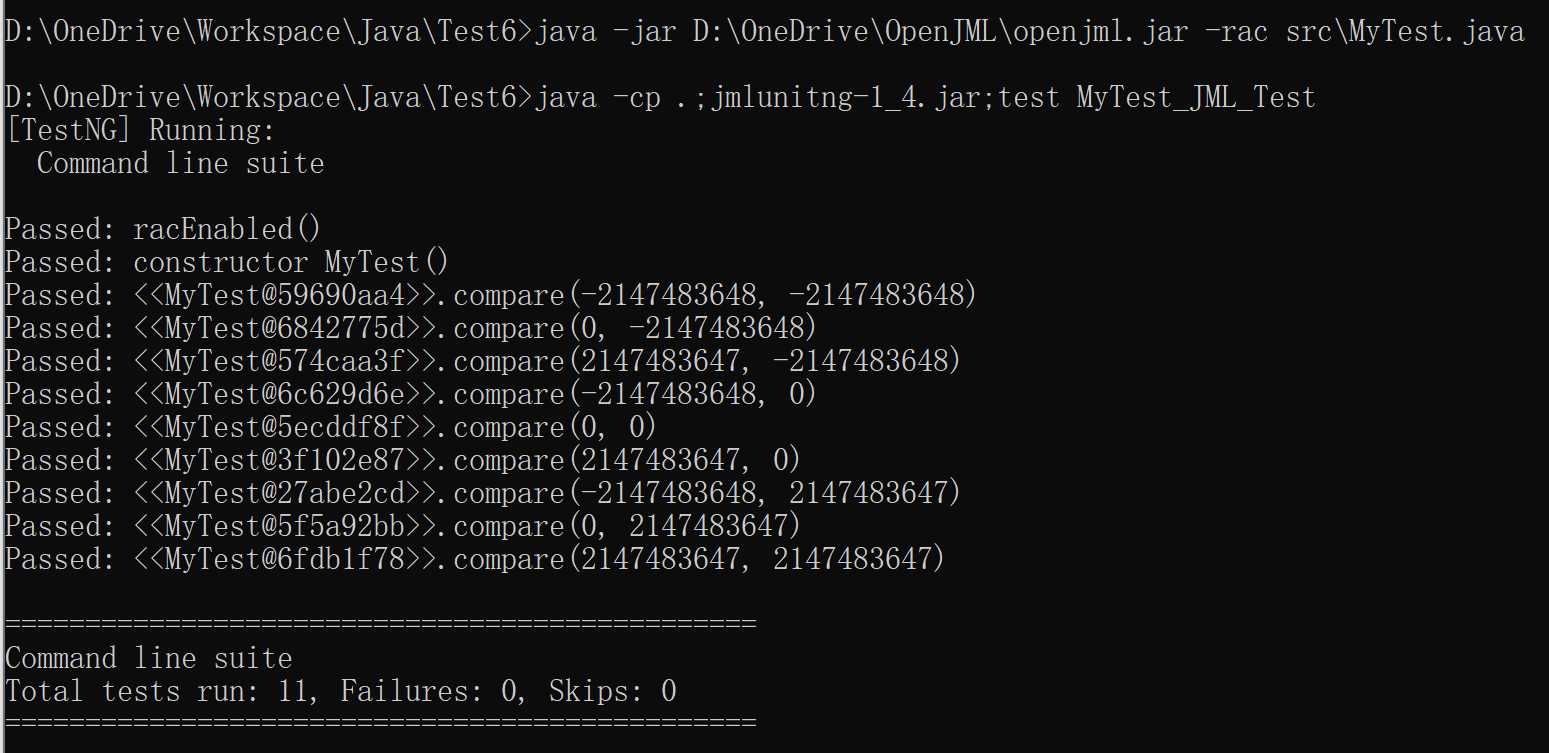
改用自己写的代码进行测试:
public class MyTest {
//@ ensures a > b ==> \result > 0;
//@ ensures a < b ==> \result < 0;
//@ ensures a == b ==> \result == 0;
public int compare(int a, int b) {
return Integer.compare(a, b);
}
}测试结果截图:
由于三次作业架构上变化并不是很大,因此我只放出第三次作业的 UML 类图,避免文章过于冗长。
Path是否存在于PathContainer中,因此直接使用ArrayList之类的查询时间为\(O(n)\)容器是肯定会超时的,在此我使用了TreeMap作为存储Path的容器,避免超时。getDistinctNodeCount()这个查询不同点的方法,如果每次查询都需要遍历一次容器也肯定会超时,在此我使用了缓存的思想:每次添加、删减Path的时候都更新distinctNodeCount,避免每次查询都需要遍历。UndGraph(非下发的Graph接口),支持:增加、删减边;计算所有点对的最短路径;获取两点间的最短路;检查是否包含边;检查是否包含路径等操作。Model\Graph接口的MyGraph接口通过组合UndGraph对象实现与图论相关的需求。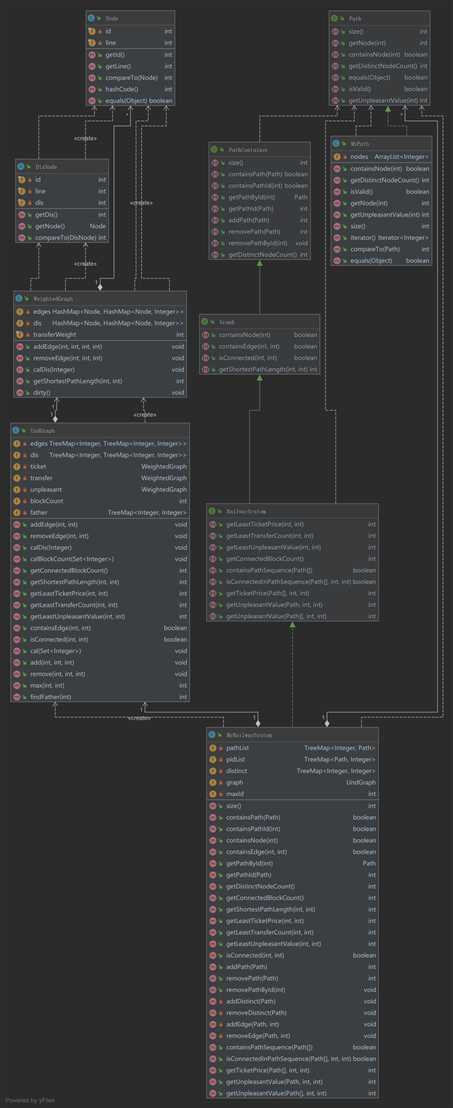
fromNode == toNode的情况,是写代码的时候不够细心导致的。TreeMap来存储数据,导致时间复杂度中的常数过大,自己测试的时候发现超时了。从撰写规格的原因就可以看出来,撰写的规格必须具备两个特性:通俗易懂和无二义性。通俗易懂能够避免解读规格所需的时间,提高程序员实现的效率。无二义性能够避免规格被错误解读,避免程序的实现与设想不符。
同时,规格只约束了方法的功能、变量的取值空间,却没有限制方法、变量的具体实现,这就给实现者留下了一定的灵活性,能让他们按照自己的习惯实现程序,在效率和可读性、可维护性上进行有考虑地折中。
原文:https://www.cnblogs.com/Nemory/p/10903171.html