Unicode 编码系统可分为编码方式和实现方式两个层次。
Unicode字符平面映射定义了所有的Unicode字符集。
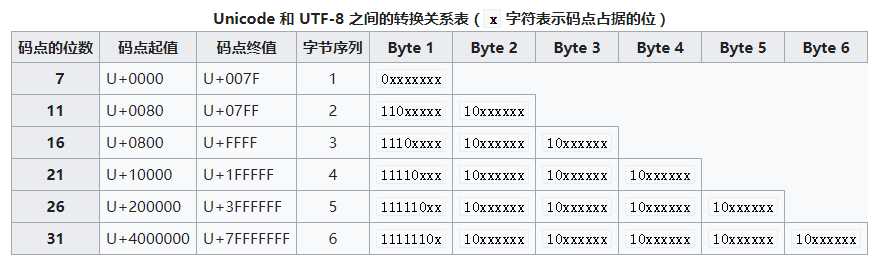
UTF-8使用一至六个字节为每个字符编码(尽管如此,2003年11月UTF-8被RFC 3629重新规范,只能使用原来Unicode定义的区域,U+0000到U+10FFFF,也就是说最多四个字节):
因此,对UTF-8编码中的任意字节,根据第一位,可判断是否为ASCII字符;根据前二位,可判断该字节是否为一个字符编码的第一个字节;根据前四位(如果前两位均为1),可确定该字节为字符编码的第一个字节,并且可判断对应的字符由几个字节表示;根据前五位(如果前四位为1),可判断编码是否有错误或数据传输过程中是否有错误。
110的是2字节序列,而1110的是三字节序列,如此类推。10。

UTF-16比起UTF-8,好处在于大部分字符都以固定长度的字节(2字节)存储,但UTF-16却无法兼容于ASCII编码。
在UTF-8+BOM格式文件的开首,很多时都放置一个U+FEFF字符(UTF-8以EF,BB,BF代表),以显示这个文本文件是以UTF-8编码。
不知道你有没有注意到,在UTF16下的这张图,地址第0,第1位是"FF FE"

对应的UTF8如下:

这就是BOM,通过FF FE或者FE FF来告诉解释器是那种字节序。
那么你也许会问,为什么UTF8没有字节序呢?那是因为UTF8是以字节为单位,一个一个字节读取。UTF16是以字为单位,一个一个字符(2个字节或者4个字节)读取,这样就会涉及先读取第一个或者第二个字节的情况。
希望这篇文章从存储字节角度看UTF8和UTF16会为给你带来不一样的感觉。

确实是一致的,但是这个UTF8的码是如何算出来的呢?
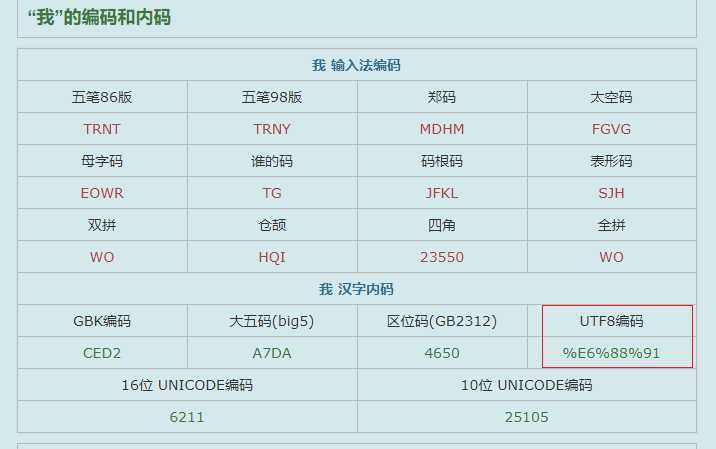
通过计算器可以看到,25105确实按照上表的方式编码为了UTF8
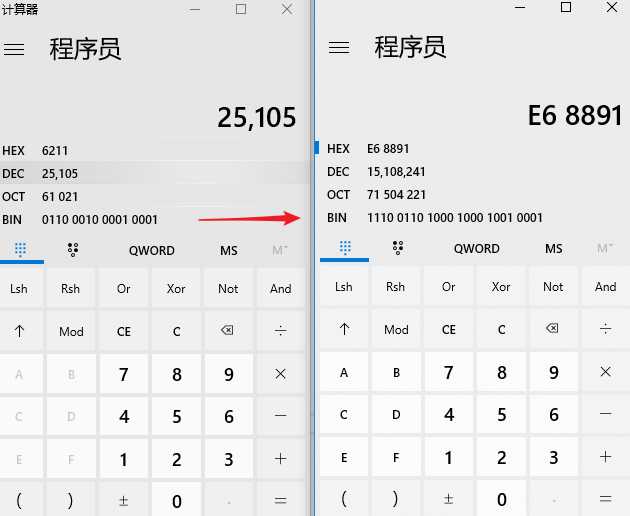
但是如果让我来写底层实现这个转换的代码?应该如何写呢?
多字节是指使用多个字节(1-3)表示一个字符。比如gbk使用英文占一个字节,中文占2个,这个就是多字节了。utf-8是使用1-3个字节表示字符。还有big5等等。
宽字节一般是固定使用2个字节表示一个字符,utf-16(一般就是指unicode)。
1、MultiByteToWideChar 多字节转宽字节
2、WideCharToMultiByte 宽字节转多字节
3、和utf8有关的字符转换,代码页CodePage=CP_UTF8。
4、代码页CodePage=CP_ACP,一般使用系统当前使用的代码页。比如在简体中文(中国等)区域下,CP_ACP表示gbk编码的936代码页。在繁体中文(台湾),CP_ACP表示big5编码的950代码页。

5、CodePage代码页一般填写的是多字节代码页。
在程序中,一般最好使用unicode字符集显示字符,Windows的内核就是用unicode编码的,unicode字符集包含了世上大多数字符。unicode在windows下的不同本地环境下都能是正常显示。
但是在使用字符串和其他程序进程(本地进程或者远端进程)进行交互时,最好使用utf8编码字符。
原因是:utf8可以表示最多的字符,所有系统通用,且不像宽字节一样每个字符都要两个字节表示,数字和字母等都是使用一个字节表示,有时可以节省大量字符串流。
Tips: Vs显示Debug窗口显示字符的时候,应该是使用系统代码页进行解码,所有UTF8无法正常展示
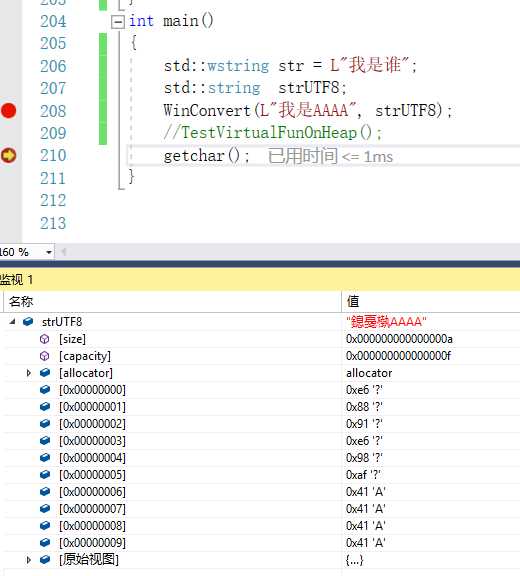
“我是谁“存储的就是字符的Unicode的16位编码。
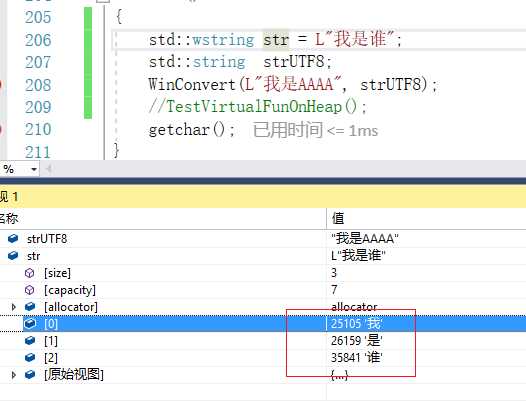
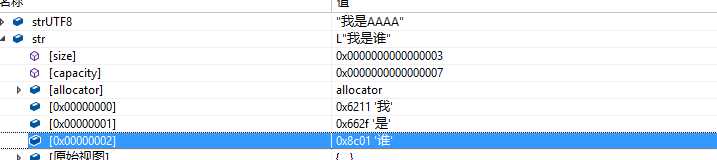
现在我将“我是谁”转换为Windows的多字节,注意这个地方展示的编码方式是CP_ACP, 也就是采用GBK编码, 可以看到Vs的监视窗口是可以展示这个字符串的。
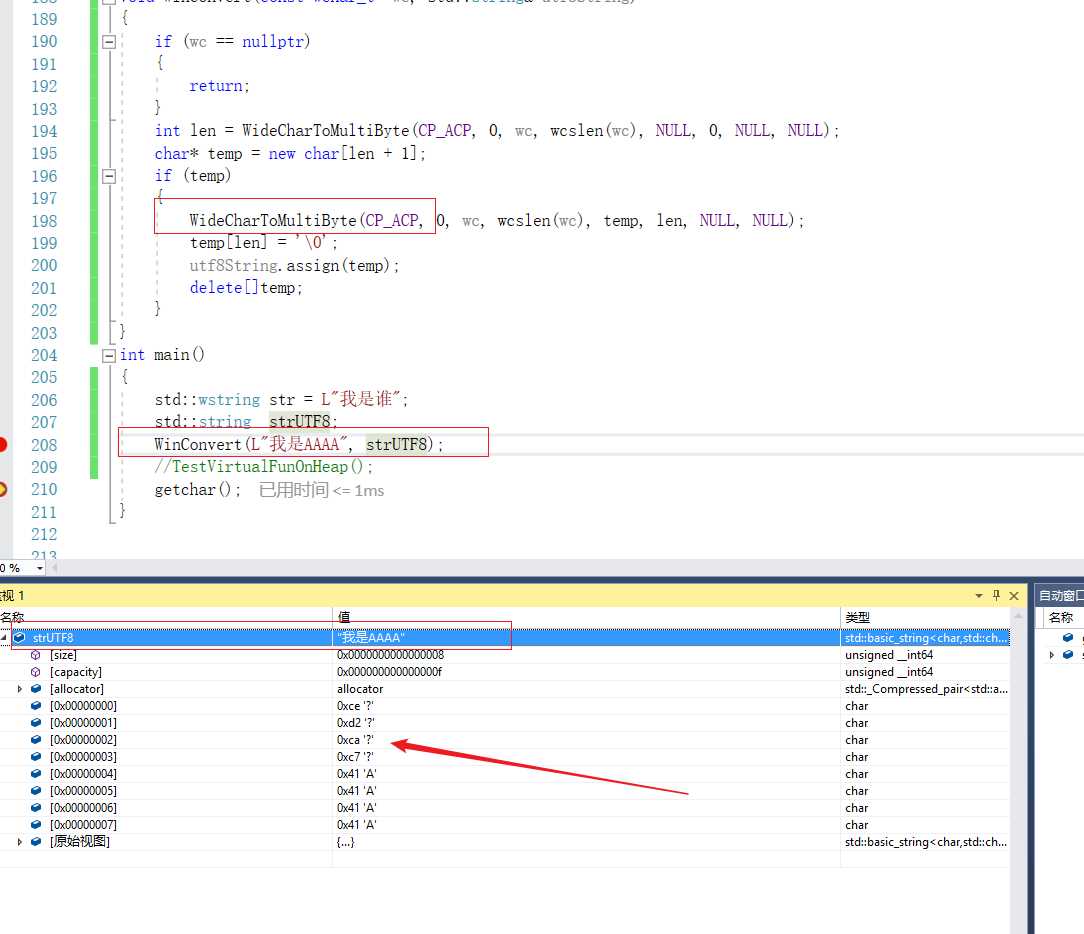
但是如果采用CP_UTF8,就无法正确显示字符。

所以问题就清楚了VS的调试器的监视窗口:
1、如果是宽字节可以正常展示;
2、如果是多字节, 编码是GBK也就是和当前系统的代码页一致,就可以显示,如果是UTF8则是乱码;
3、Notepad++也是根据编码方式获得对应的Unicode码,然后在从字符集里面取出对应的字行进行展示的;
原文:https://www.cnblogs.com/khacker/p/10902375.html