JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。JML是一种行为接口规格语言(Behavior Interface Specification Language,BISL),基于Larch方法构建。BISL提供了对方法和类型的规格定义手段。有了JML,我们就可以描述方法的预期功能,无需考虑实现。通过这种方法,JML将延迟过程设想的面向对象原则扩展到了方法设计阶段。以下梳理JML语言的使用方法。
行注释的表示方式为 //@annotation ,块注释的方式为 /* @ annotation @*/ 。
\result表达式:表示一个非void类型的方法执行所获得的结果,即方法执行后的返回值。
\old(expr)表达式:用来表示一个表达式expr在相应方法执行前的取值。
\forall表达式:全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束。
\exists表达式:存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束。
子类型关系操作符: E1<:E2 ,如果类型E1是类型E2的子类型(sub type),则该表达式的结果为真,否则为假。
等价关系操作符: b_expr1<==>b_expr2 或者 b_expr1<=!=>b_expr2 ,其中b_expr1和b_expr2都是布尔表达式,这两个表达式的意思是 b_expr1==b_expr2 或者 b_expr1!=b_expr2 。
推理操作符: b_expr1==>b_expr2 或者 b_expr2<==b_expr1 。对于表达式b_expr1==>b_expr2而言,当b_expr1==false,或者b_expr1==true且b_expr2==true时,整个表达式的值为true。
前置条件(requires):描述方法输入数据的要求。
后置条件(ensures):方法执行结果满足的约束。
作用范围(assignable):方法能够修改的类成员属性。
不变式:不变式是要求在所有可见状态下都必须满足的特性,语法上定义 invariant P ,其中 invariant 为关键词, P 为谓词。
状态变化约束:描述数据状态变化应该满足的要求,这种约束本质上也是一种不变式。
JML 编译器(jmlc),是对Java 编译器将带有 JML 规范注释的 Java 程序编译成 Java 字节码。 编译的字节码包括检查的运行时断言检查指令。
文件产生器文档(jmldoc),生成包含 Javadoc 注释和任何 JML 规范的 HTML。 这便于将JML 规范公布在网上。
OpenJML: 检查JML规范性。
JMLUnitNG,将Jml 编译器与 JUnit(一个流行的单元测试工具)结合,能实现自动测试。
环境为IDEA+openJML,用IDEA自带的extern Tools将命令行指令写入,生成extern Tools自动测试。测试对象为第一次作业的PathContainer.java中的所有方法:
忽略警告信息,只截取错误信息,测试结果如下


说明第一次作业中课程组给出的规格\old处存在错误,我问了一些其他同学,也有相同反馈。说明openJML找出了规格编写上的错误。
写了一个乘法及其规格的简单测试,实验JMLUnitNG,代码如下:
public class test { /*@ public normal_behaviour @ ensures \result == first * second; */ public static int mul(int first, int second) { return first * second; } public static void main(String[] args) { mul(999, 999); } }
参考教程https://course.buaaoo.top/assignment/71/discussion/199,用命令行进行编译,会出现一些中间文件,如下:
其中的out文件夹内容如下:
最后执行生成的测试文件,结果如下:
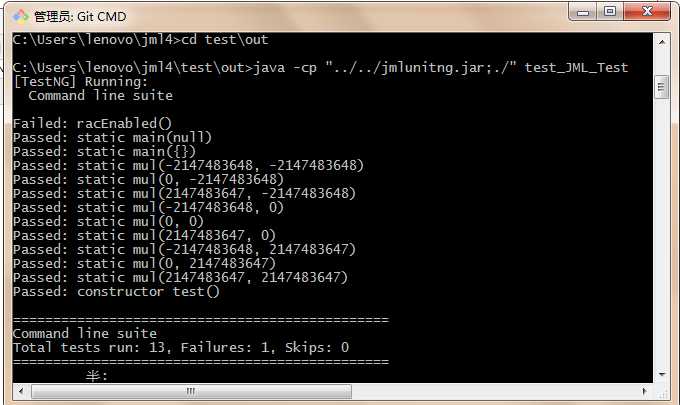
说明JMLUnitNG生成的自动测试包含null,{},0,边界数据等情况的组合,自动测试通过,说明程序的正确性得到了一定程度的检验。
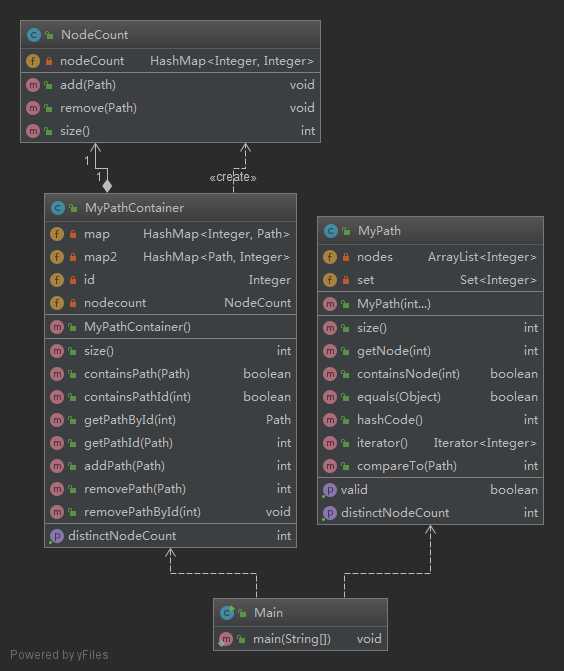
MyPath部分,存储Path中的点和点序用的是一个ArrayList成员nodes,size()返回nodes的size,hashCode()返回nodes的hashcode,另外,Path中还有S一个HashSet成员set,用于保存点集,故containsNode可以用set的contains实现,distinctNodeCount可以用set的size实现,因为采用的是哈希查找,时间复杂度要更小。
MyPathContainer部分,Path和PathId的对用采用了两个HashMap,分别用于通过Path查找PathId,通过PathId查找Path,这样在查找时的时间复杂度就会低,值得一提的是,为了实distinctNodeCount,我写了一个类NodeCount,在MyPathContainer中创建nodecount对象,用于对不同点的计数,在加路径和减路径时对nodecount进行维护,最后计算distinctNodeCount时只需要返回nodecount的size即可,时间复杂度为O(1),做到了时间复杂度的均摊。
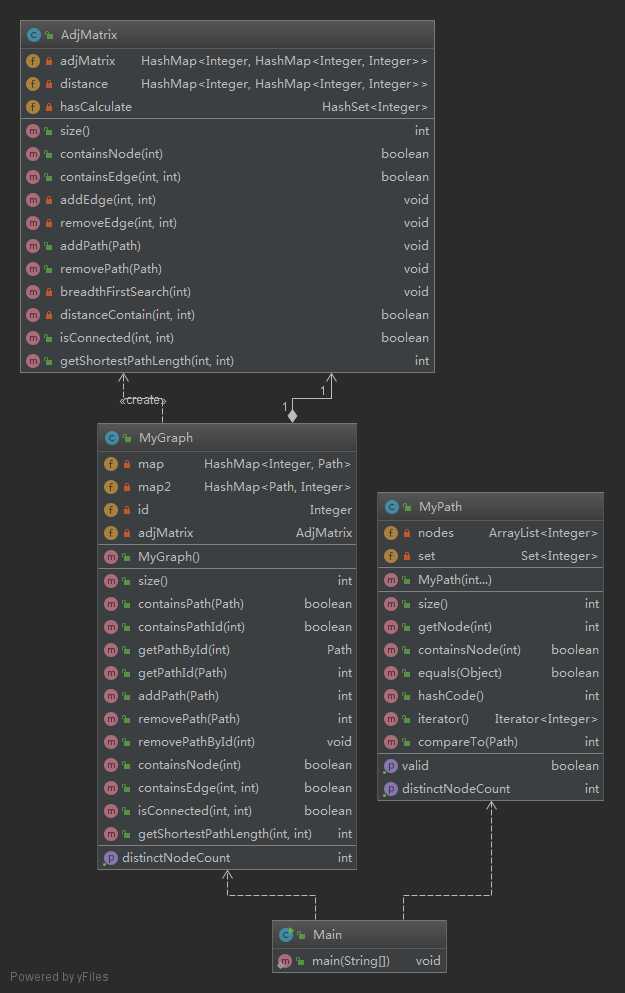
MyPath部分,和第一次作业完全一样。
MyGraph部分,这次多了三个函数,containEdge,isConnected,getShortestPathLength,而原来的NodeCount类是没有边的信息的,更不用说求最短路径了,于是需要重构。我把原来的NodeCount改成了AdjMatrix类,即邻接矩阵,AdjMatrix类的主成员是adjMatrix,类型是HashMap<Integer, HashMap<Integer, Integer>>,表示一个点的所有邻接点以及与该邻接点有多少条相连的边,通俗理解就是完整图信息的邻接矩阵。邻接矩阵在加入Path和删除Path时进行维护,有了邻接矩阵,连通性和最短距离都可以通过BFS广度优先搜索得到,值得一提的是,为了降低复杂度我运用了缓存的思想,就是在图没有改变之前,我会在AdjMatrix类中加入信号,如果新的查询结果能用过旧的查询的缓存中得到,会通过信号判断后直接返回,不会再跑一遍BFS,从而降低了时间复杂度。
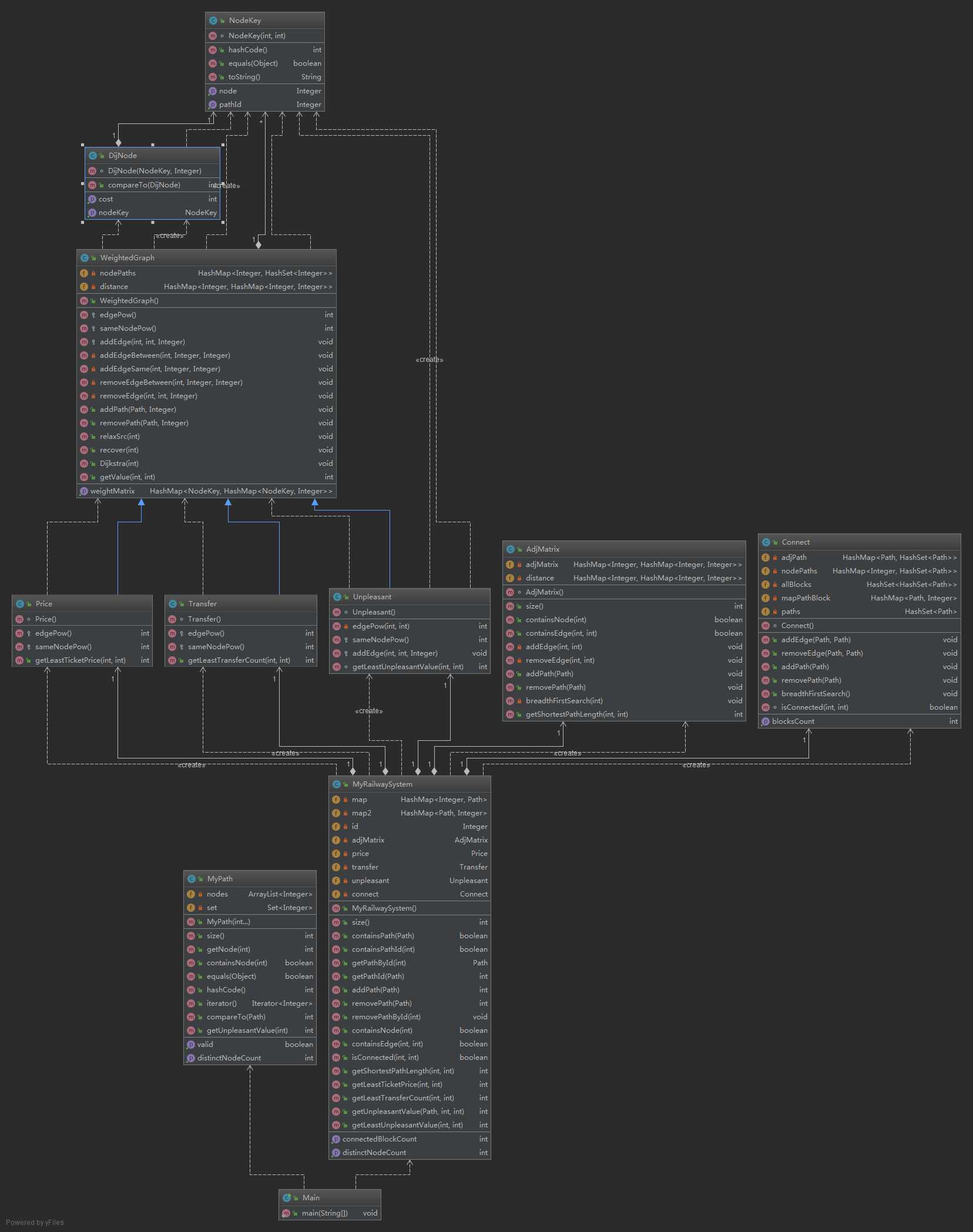
第三次作业的设计难度相较于前两次有了较大提升,MyPath部分依然没有变化,MyRailwaySysterm中多了getLeastTicketPrice,getLeastTransferConut,getLeastUnpleasantValue,connectedBlockCount四个函数,下面分析如何针对这四个问题来扩展架构。
getLeastTicketPrice,getLeastTransferConut,getLeastUnpleasantValue,这个三个函数其实是一类问题,就是有权图的最短路径问题,首先我们得有有权图的信息,所以我写了一个类叫做WeightedGraph,其中的函数包括在增删Path时对图进行维护、边权值的设定、相同点但处于不同的path之间权值的设定,求解两点间的最短距离。然后有权图两点间最短距离的计算算法是迪杰斯特拉算法。在写好有权图类之后,为了解决最小票价,最小换乘,最小不满意度,我写了三个子类,Price,Transfer,Unpleasant,他们继承自父类WeightedGraph,子类只需要重写设置边权的函数即可。
为了实现connectedBlockCount函数,我写了一个Connect类,专门处理连通性问题,主要的思想是将Path看成一个点,将有交集的Path看做有边相连,在这个新的图上跑BFS得到连通块,并且在得到连通块之后建立并查集,来减小查询两个node是否连通的复杂度,有了连通块的集合,connectedBlockCount函数只需要返回连通块的集合的size即可。
我发现我的三次作业中有一个很有价值的重构点,这个重构先是单个类的重构,后是单个类到多个类的重构,下面我来解释我的这句话。为了实现两个主类,我采用的是辅助类。在第一次作业中这个辅助类是NodeCount类,即点的计数。扩充到第二次作业后我发现NodeCount类不包含边的信息,我就对辅助类进行了重构,并改名为AdjMatrix类,在原来的基础上加入了边的信息,加入了实现BFS最短路算法的函数,这就是我说的单个类的重构,即对辅助类的升级。扩充到第三次作业后我发现一个辅助类不能满足需求,价格、换乘、不满意度这些需要继承有权图类,而连通性需要无权图类和一些并查集的算法,我把这些类一一实现,即多个辅助类,然后按和前两次作业一样的方式将它们在主类中创建,这些辅助类的共性是在主类中增删Path时对辅助类中的图进行维护,这个图可能是有权图可能是无权图,当这些辅助类的功能都写正确之后,主类的这些难度较大的函数就都迎刃而解了,这就是我所说的单个类到多个类的重构。收获颇多。
我的三次作业强测都通过了,下面说一下实现过程中遇到的一些有价值的bug。
第一次作业:第一次作业最为简单,有一个较为重要的bug就是善用HashMap和HashSet,利用哈希查询复杂度的优势将复杂度降低,一开始没注意到这一点后来和别人交流时发现问题。
第二次作业:第二次作业在第一次作业上加上邻接矩阵,实现BFS算法搜索最短路径,我之前实现过程中出现的一个bug是在保存缓存时没有记录所有之前查询的缓存,只记录了上一次查询的缓存,导致出现一些问题,还是自己编程过程中的一些不良思维习惯导致的,后来在debug时发现这一问题。
第三次作业:第三次作业代码量相对前两次较大,完成代码编写后出现了许多运行时空指针异常的情况,我慢慢思考为什么会出现,我de完bug之后才发现IDEA其实在可能出现空指针的地方有提醒,所以在编程过程中就可以注意这些提醒,将bug在编程阶段抹杀。另外一个较重要的bug是,我为了实现HashMap,编写key的equals时,出现equals的返回值与我预期不一致的情况,而这种情况在Integer取值较大时才会出现,后来我反复比对发现原因是,我在一处判断Integer相等时我用的是==,原以为Integer会默认按值比较,后来查阅资料或发现Integer的==原理是这样的,在-255和255之间==是比较值,超过这个范围是比较指针,所以需要按值比较要用Integer.equals。
规格最大的好处就是能解决二义性问题,为编程人员解决很多细节问题,方便协同开发,很适合高精密性的代码(例如航空航天产业)。我觉得不足的地方在于JML语言还是有点复杂了,有些场景表达起来很繁琐,然后不同的人写的JML语言差别也是很大的,尽管他们写的都是正确的。
不过总体来说还是很有价值的,使用规格使我们的代码便于进行自动化检查和测试,大大提高了正确率,收获颇多,感谢老师和助教们的悉心指导。
原文:https://www.cnblogs.com/duyiyang/p/10907596.html