RDD的缓存一般就是用cache和persist,那二者之间有什么关系,又有什么区别呢?
关系:
persist()内部调用了persist(StorageLevel.MEMORY_ONLY)
cache()调用了persist()
区别:
persist有一个 StorageLevel 类型的参数,这个表示的是RDD的缓存级别。
cache只有一个默认的缓存级别MEMORY_ONLY ,而persist可以根据情况设置其它的缓存级别。
StorageLevel部分源码
object StorageLevel { val NONE = new StorageLevel(false, false, false, false) val DISK_ONLY = new StorageLevel(true, false, false, false) val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2) val MEMORY_ONLY = new StorageLevel(false, true, false, true) val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2) val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false) val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2) val MEMORY_AND_DISK = new StorageLevel(true, true, false, true) val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2) val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false) val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2) val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
。。。。。。
}
我们介绍6种常用的
MEMORY_ONLY
|
使用未序列化的Java对象格式,将数据保存在内存中。如果内存不够存放的所有数据,则数据可能就不会进行持久化。那么下次对这个RDD执行算子操作时,那些没有被持久化的数据,需要从源头上重新计算一遍。这是默认的持久化策略。使用cache()方法时,实际就是使用这种持久化策略 |
MEMORY_ONLY_SER |
基本上含义同MEMORY_ONLY一样。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个patition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多的内存导致频繁的GC |
MEMORY_AND_DISK |
用未序列化的java对象格式,优先尝试将数据保存在内存中。如果内存不够存放数据,会将数据写入磁盘文件中,下次对这个RDD执行算子时,持久化在磁盘文件中的数据会被读取出来使用 |
MEMORY_AND_DISK_SER
|
基本含义同MEMORY_AND_DISK。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
DISK_ONLY
|
使用未序列化的Java对象格式,将数据全部写入磁盘文件中。 |
MEMORY_ONLY_2,MEMORY_AND_DISK_2
等 |
对于上述任意一种持久化策略,如果加上后缀_2,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。这种基于副本的持久化机制主要用于进行容错。假如某个节点挂掉,节点的内存或磁盘中的持久化数据丢失了,那么后续对RDD计算时还可以使用该数据在其他节点上的副本。如果没有副本的话,就只能将这些数据从源头处重新计算一遍了。 |
持久化级别的选择
持久化级别测试
1.MEMORY_ONLY
没有注册没有序列化
package com.ruozedata.spark1 import org.apache.spark.storage.StorageLevel import org.apache.spark.{SparkConf, SparkContext} /** * 使用kryo序列化数据对象, * 1、生产山spark.serializer这个配置直接写到spark-default配置文件中即可 */ object KryoApp { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("KyroApp").setMaster("local[2]") // conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") // conf.registerKryoClasses(Array(classOf[Logger])) val sc = new SparkContext(conf) val logRDD = sc.textFile("C:\\Users\\小十七\\Desktop/CDN_click.log") .map(x => { val logFields = x.split(",") Logger(logFields(0), logFields(1), logFields(2), logFields(3), logFields(4), logFields(5), logFields(6), logFields(7)) }) val pesisitRDD = logRDD.persist(StorageLevel.MEMORY_ONLY) //val pesisitRDD = logRDD.persist(StorageLevel.MEMORY_ONLY_SER) println("总条数" + pesisitRDD.count()) Thread.sleep(2000000) sc.stop() } case class Logger(filed1: String, filed2: String, filed3: String, filed4: String, filed5: String, filed6: String, filed7: String, filed8: String) }

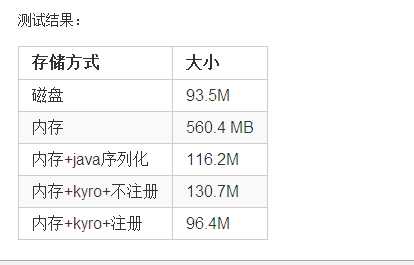
从图中可以看出读入的时候是93.6M
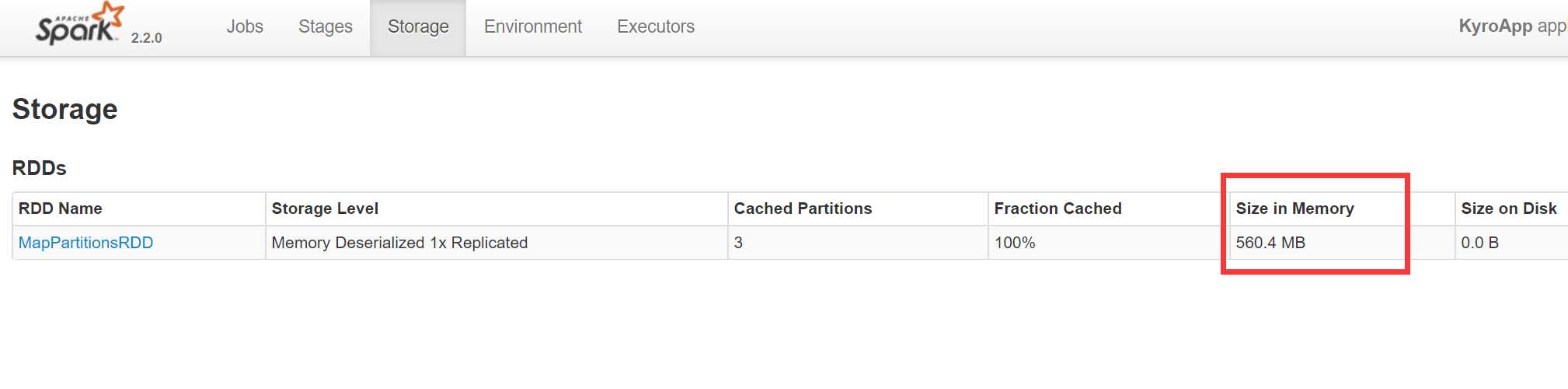
缓存以后就是560.4M,是原来的6倍
2.MEMORY_ONLY_SER
package com.ruozedata.spark1 import org.apache.spark.storage.StorageLevel import org.apache.spark.{SparkConf, SparkContext} /** * 使用kryo序列化数据对象, * 1、生产山spark.serializer这个配置直接写到spark-default配置文件中即可 */ object KryoApp { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("KyroApp").setMaster("local[2]") // conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") // conf.registerKryoClasses(Array(classOf[Logger])) val sc = new SparkContext(conf) val logRDD = sc.textFile("C:\\Users\\小十七\\Desktop/CDN_click.log") .map(x => { val logFields = x.split(",") Logger(logFields(0), logFields(1), logFields(2), logFields(3), logFields(4), logFields(5), logFields(6), logFields(7)) }) // val pesisitRDD = logRDD.persist(StorageLevel.MEMORY_ONLY) val pesisitRDD = logRDD.persist(StorageLevel.MEMORY_ONLY_SER) println("总条数" + pesisitRDD.count()) Thread.sleep(2000000) sc.stop() } case class Logger(filed1: String, filed2: String, filed3: String, filed4: String, filed5: String, filed6: String, filed7: String, filed8: String) }
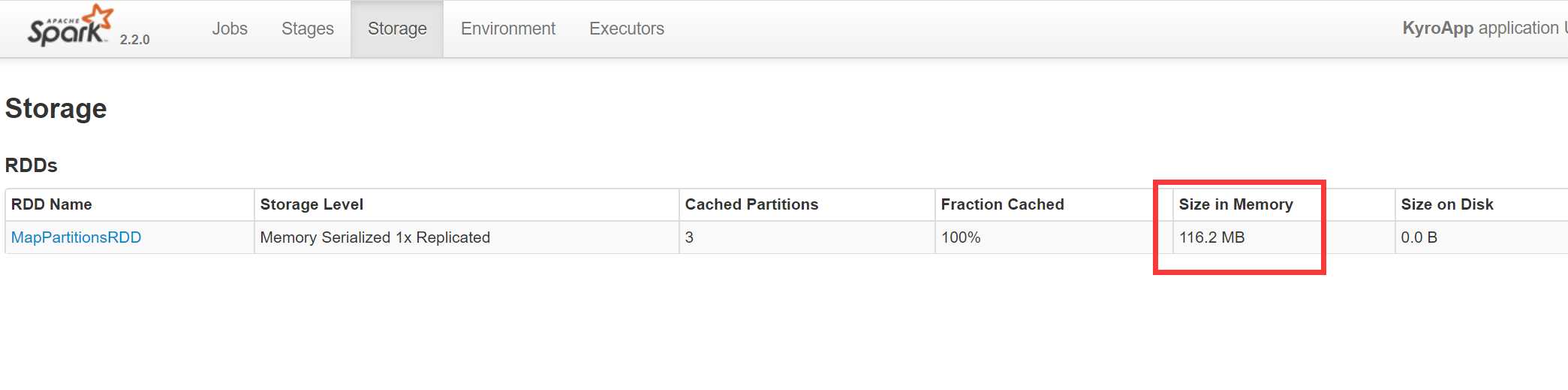
由上图可以看出序列化以后,缓存减小到了116M
3.使用Kryo但不注册不序列化
package com.ruozedata.spark1
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
/**
* 使用kryo序列化数据对象,
* 1、生产山spark.serializer这个配置直接写到spark-default配置文件中即可
*/
object KryoApp {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("KyroApp").setMaster("local[2]")
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
//conf.registerKryoClasses(Array(classOf[Logger]))
val sc = new SparkContext(conf)
val logRDD = sc.textFile("C:\\Users\\小十七\\Desktop/CDN_click.log")
.map(x => {
val logFields = x.split(",")
Logger(logFields(0), logFields(1), logFields(2), logFields(3),
logFields(4), logFields(5), logFields(6), logFields(7))
})
val pesisitRDD = logRDD.persist(StorageLevel.MEMORY_ONLY)
// val pesisitRDD = logRDD.persist(StorageLevel.MEMORY_ONLY_SER)
println("总条数" + pesisitRDD.count())
Thread.sleep(2000000)
sc.stop()
}
case class Logger(filed1: String, filed2: String, filed3: String,
filed4: String, filed5: String, filed6: String,
filed7: String, filed8: String)
}
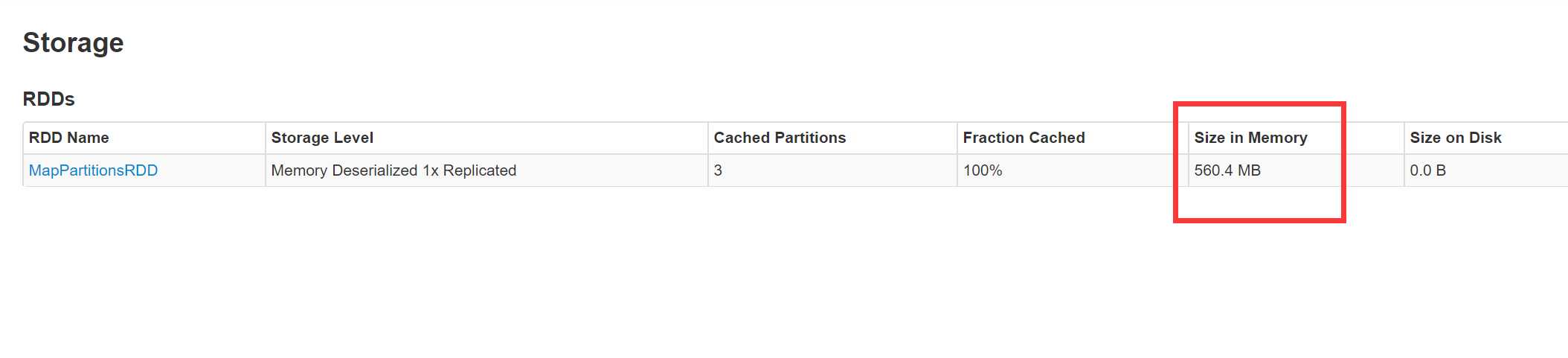
4.使用Kryo但不注册序列化
package com.ruozedata.spark1 import org.apache.spark.storage.StorageLevel import org.apache.spark.{SparkConf, SparkContext} /** * 使用kryo序列化数据对象, * 1、生产山spark.serializer这个配置直接写到spark-default配置文件中即可 */ object KryoApp { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("KyroApp").setMaster("local[2]") conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") //conf.registerKryoClasses(Array(classOf[Logger])) val sc = new SparkContext(conf) val logRDD = sc.textFile("C:\\Users\\小十七\\Desktop/CDN_click.log") .map(x => { val logFields = x.split(",") Logger(logFields(0), logFields(1), logFields(2), logFields(3), logFields(4), logFields(5), logFields(6), logFields(7)) }) // val pesisitRDD = logRDD.persist(StorageLevel.MEMORY_ONLY) val pesisitRDD = logRDD.persist(StorageLevel.MEMORY_ONLY_SER) println("总条数" + pesisitRDD.count()) Thread.sleep(2000000) sc.stop() } case class Logger(filed1: String, filed2: String, filed3: String, filed4: String, filed5: String, filed6: String, filed7: String, filed8: String) }

5.使用Kryo但注册不序列化
package com.ruozedata.spark1 import org.apache.spark.storage.StorageLevel import org.apache.spark.{SparkConf, SparkContext} /** * 使用kryo序列化数据对象, * 1、生产山spark.serializer这个配置直接写到spark-default配置文件中即可 */ object KryoApp { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("KyroApp").setMaster("local[2]") conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") conf.registerKryoClasses(Array(classOf[Logger])) val sc = new SparkContext(conf) val logRDD = sc.textFile("C:\\Users\\小十七\\Desktop/CDN_click.log") .map(x => { val logFields = x.split(",") Logger(logFields(0), logFields(1), logFields(2), logFields(3), logFields(4), logFields(5), logFields(6), logFields(7)) }) val pesisitRDD = logRDD.persist(StorageLevel.MEMORY_ONLY) // val pesisitRDD = logRDD.persist(StorageLevel.MEMORY_ONLY_SER) println("总条数" + pesisitRDD.count()) Thread.sleep(2000000) sc.stop() } case class Logger(filed1: String, filed2: String, filed3: String, filed4: String, filed5: String, filed6: String, filed7: String, filed8: String) }
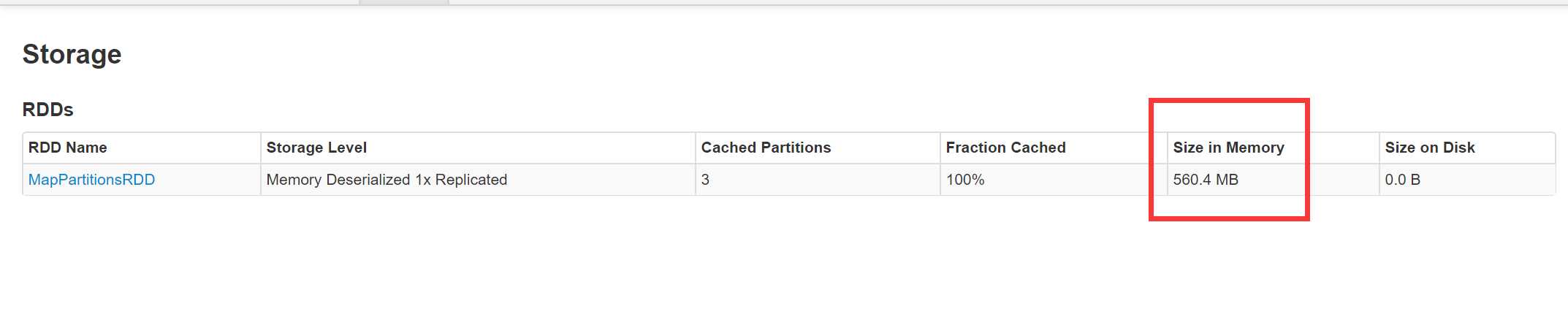
6.使用Kryo注册并序列化
package com.ruozedata.spark1 import org.apache.spark.storage.StorageLevel import org.apache.spark.{SparkConf, SparkContext} /** * 使用kryo序列化数据对象, * 1、生产山spark.serializer这个配置直接写到spark-default配置文件中即可 */ object KryoApp { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("KyroApp").setMaster("local[2]") conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") conf.registerKryoClasses(Array(classOf[Logger])) val sc = new SparkContext(conf) val logRDD = sc.textFile("C:\\Users\\小十七\\Desktop/CDN_click.log") .map(x => { val logFields = x.split(",") Logger(logFields(0), logFields(1), logFields(2), logFields(3), logFields(4), logFields(5), logFields(6), logFields(7)) }) // val pesisitRDD = logRDD.persist(StorageLevel.MEMORY_ONLY) val pesisitRDD = logRDD.persist(StorageLevel.MEMORY_ONLY_SER) println("总条数" + pesisitRDD.count()) Thread.sleep(2000000) sc.stop() } case class Logger(filed1: String, filed2: String, filed3: String, filed4: String, filed5: String, filed6: String, filed7: String, filed8: String) }
总结:上边的6种情况分别对MEMORY_ONLY,MEMORY_ONLY_SER做了是否序列化和是否使用Kryo注册的测试,从Web界面的Size in Memory这个参数可以看出凡是经过序列化的缓存以后的值不会很大,但是不序列化,无论注册与否值都是非常大的,对于序列化的使用Kryo并注册以后的的值是最理想的,和原始文件的大小非常贴近,只是使用Kryo序列化,而不注册,缓存值稍微大一点113M左右
原文:https://www.cnblogs.com/xuziyu/p/10914701.html