基于之前对HDFS文件系统存储读写的讨论,我们知道Hadoop将一个超大文件切割成一个个Block后,复制并存储于多个Datanodes中,文件系统的所有节点集合称为Cluster(集群)。 而MapReduce则是Hadoop基于Cluster的数据处理范式 (Data Processing Paradim).
网络上大多数的教程和例子,让人看得一头雾水。不如换个角度来看看,为什么MapReduce对于HDFS是可行的吧。思想类似于古老的中国战略“分而治之” (Divide-and-Conquer),好比秦灭六国,有两种选择,其一是七国之兵汇于秦地一战,其二是出兵各个击破。MapReduce就是第二种选择,所谓的Bringing Functions to Data。
而MapReduce的两个阶段Map和Reduce,要做的工作分别是‘分布式执行’以及‘合并结果’。可以理解为,各个击破,再统一管理。如下图,我们看到,数据已经被切分成了3个Blocks,分别存放于3个DataNode上。MapReduce的Mapper会优先选择在Replica存放的硬件上执行操作,如果该硬件无法执行操作,转而在同Rack的另一台硬件上就近执行。之后,Reducer将Mapper的输出作为自己的输入,二次处理后,产生最终的输出结果。
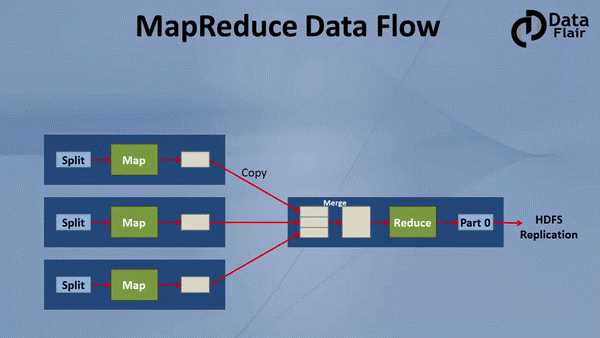
从数据流的角度来看
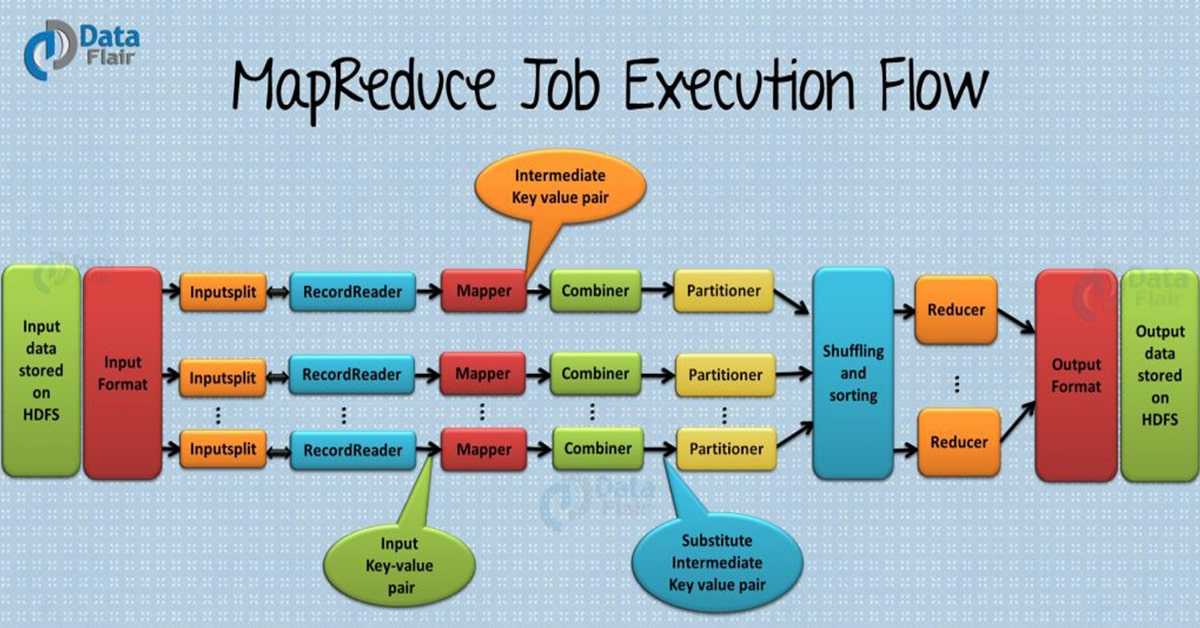
the reducer is shown on a different machine but it will run on mapper node only.
https://www.edureka.co/blog/mapreduce-tutorial/
原文:https://www.cnblogs.com/rhyswang/p/10550435.html