关系型数据的收集
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
关系型数据是常见的一种数据类型,通常存储在像MySQL,Oracle等关系型数据库中,为了能够利用大数据技术处理和存储这些关系型数据,首先需将这些数据导入到像HDFS,HBase这样的大数据存储系统中,以便使用MapReduce,Spark这样的分布式计算技术进行高效分析和处理。
从另一个角度讲,为了便于前段和数据可视化系统对接,我们通常需要将Hadoop大数据系统产生的结构(比如报表,通常数据量不会太大)导回到关系型数据库中。
为了解决上述问题,高效实现关系型数据库与Hadoop之间的数据导入到处,Hadoop生态系统提供了Sqoop(SQL to Hadoop)。
一.Sqoop概述
1>.设计动机
Sqoop从工程角度,解决了关系型数据库与Hadoop之间的数据传输问题,它构建了两者之间的“桥梁”,使得数据迁移工作变得异常简单。在实际项目中,如果遇到一下任务,可尝试使用Sqoop完成: (1)数据迁移 公司内部商用关系性数据仓库中的数据以分析为主,综合考虑扩展性,容错性和成本开销等方面。若将数据迁移到Hadoop大数据平台上,可以方便地使用Hadoop提供如Hive,SparkSQL分布式等工具进行数据分析。为了一次性将数据导入Hadoop存储系统,可使用Sqoop。 (2)可视化分析结果 Hadoop处理的输入数据规模可能是非常庞大的,比如PB级别,但最终产生的结果可能不会太大,比如报表数据等,而这类结果通常需要进行可视化,以便更直观地展示分析结果。目前绝大部分可视化工具与关系型数据库对接比较好,因此,比较主流的做法是,将Hadoop产生的结果导入关系型数据库进行可视化展示。 (3)数据增量导入
考虑到Hadoop对事务的支持比较差,因此,凡事涉及事务的应用,比如支付平台等,后端的存储均回选择关系型数据库,而事务相关的数据,比如用户支付行为等,可能在Hadoop分析过程中用到(比如广告系统,推荐系统等)。为了减少Hadoop分析过程中影响这类系统的性能,我们通常不会直接让Hadoop访问这些关系型数据库,而是单独导入一份到Hadoop存储系统中。
为了解决上述数据收集过程中遇到的问题,Apache Sqoop项目诞生了,它是一个性能高,易用,灵活的数据导入导出工具,在关系型数据库与Hadoop之间搭建了一个桥梁,如下图所示,让关系型数据库变得异常简单。

2>.Sqoop基本思想及特点
Sqoop采用插拔式Connector架构,Connector是只特定数据源相关的组件,主要负责(从特定数据源中)抽取和加载数据。用户可选择Sqoop自带的Connector,或者数据库提供商发布的native Connector,甚至根据自己的需要定制Connector,从而把Sqoop打造成一个公司级别的数据迁移管理工具。
Sqoop主要具备以下特点:
(1)性能高
Sqoop采用MapReduce完成数据的导入导出,具备了MapReduce所具有的优点,包括并发度可控,容错性高,扩展性高等。
(2)自动类型转换
Sqoop可读取数据元信息,自动完成数据类型映射,用户也可根据需要自定义类型映射关系。
(3)自动传播元信息
Sqoop在数据发送端和接收端之间传递数据的同时,也会将元信息传递过去,保证接收端和发送端的有一致的元信息。
3>.Sqoop基本架构
Sqoop目前存在两个版本,截至目前(2019-05-25)两个版本分别以版本号1.4x和1.99.x表示,通常简称为“Sqoop1”和“Sqoop2”,Sqoop2在架构和设计思路上对Sqoop1做了重大改进,因此两个版本是完全不兼容的。接下来,我们重点关注这两个版本的设计原理和架构。
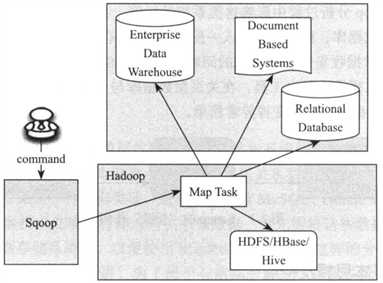
如上图所示, Sqoop1是一个客户端工具,不需要启动任何服务便可以使用,非常简单。Sqoop1是实际上是一个只有Map的MapReduce作业,它充分利用MapReduce高容错特性,扩展性等优点,将数据迁移任务转换为MapReduce作业。
当用户通过shell命令提交作业后,Sqoop回从关系型数据库读取元数据,并根据并发度和数据表大小将数据划分成若干分片,每片交给一个Map Task处理,这样,多个Map Task同时读取数据库中的数据,并将数据写入目标存储昔日,比如HDFS,HBase和Hive等。
Sqoop1允许用户通过定制各种参数控制作业,包括任务并行度,数据源,超时时间等。总体架构上讲,Sqoop1只是一个客户端工具,windows下绿色版本软件大多是对原始软件的破解,建议删去这个类比因此使用起来非常简单,但如果你的数据迁移作业很多,Sqoop1则会暴露很多缺点,包括:
(1)connector定制麻烦
Sqoop1仅支持基于JDBC的Connector了;Connecotr开发复杂,通过的功能也需要自己开发而不是提前提供好;Connector与Hadoop耦合度过高,使得开发一个Connector需要对Hadoop有充分的理解和学习。
(2)客户端软件繁多
Sqoop1需求以来的软件必须安装在客户端砂锅,包括MySQL客户端,Hadoop/HBase/Hive客户端,JDBC驱动,数据厂商的Connector等,这使得Sqoop客户端不容易部署和安装。
(3)安全性差
Sqoop1需要用户明文提供数据库的用户名和密码,但为考虑如何利用Hadoop安全机制提供可靠且安全的数据迁移工作。
为了解决Sqoop1客户端架构所带来的问题,Sqoop2对其进行了改进,如下图所示,引入了Sqoop Server,将所有管理工作放到Server段,包括Connector管理,MySQL/Hadoop相关的客户端,安全认证等,这使得Sqoop客户端变得非常轻,更易于使用。Sqoop1到Sqoop2的变迁,类似于传统软件架构到云计算架构的变迁,将所有软件运行到“云端”(Sqoop Server),而用户只需要通过命令或浏览器便可以随时随处使用Sqoop2。
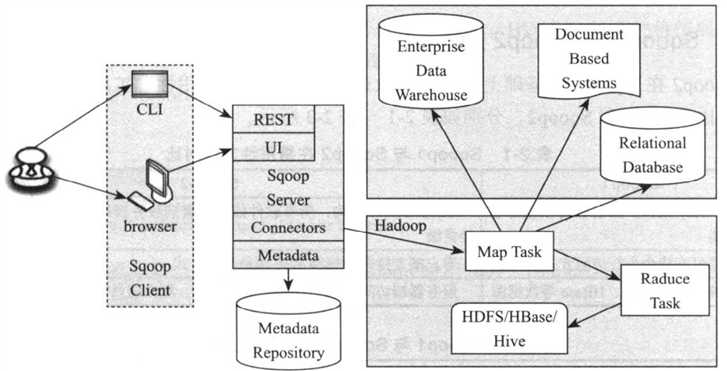
Sqoop2主要组件及功能如下:
二.
原文:https://www.cnblogs.com/yinzhengjie/p/10922849.html