(这是一篇译文,原文链接 here ,内容及图片版权归原文所有. 水平有限,错误难免,恳请批评指正,请使用文明用语)
现代计算机系统的的内存访问速度远远跟不上不断增长的处理器运算速度,这使得处理器设计者们不得不添加高速缓存以弥补访问低速(和CPU相比)内存所带来的系统性能下降。在很多场景下,缓存的的访问速度可以达到内存访问速度的27倍,甚至更快。这种性能差异让我们有必要重新思考一下传统的(软件)优化技术。
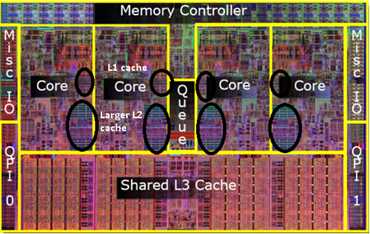
首先看一下典型处理器芯片上的CPU 核以及缓存的布局结构,下图是一个4核CPU的处理器的结构示意图:
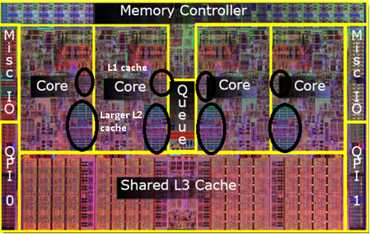
4核CPU的L1,L2,L3缓存结构图
每个CPU核包含两个层级的缓存:
除此外,所有CPU核还共享大概8MB左右的L3缓存
这里也可以看出L1缓存的访问速度大概是内存访问速度的27倍。由于这种访问速度上的不均衡,一个复杂度为O(1)的算法如果执行过程中导致多次缓存缺失(cache misses),其最终性能甚至会比一个时间复杂度为O(n)的算法还要差。下面看一下缓存结构对性能的影响,这尤其对高性能计算以及游戏开发重要。
一个缓存行(cache line)是缓存和内存间的数据传输单元,一般是64个字节。当处理器需要在内存中一个64字节区域的任意位置进行读/写时,它会把整个区域内容(64bytes)写入/读出缓存行。处理器还会尝试通过分析一个线程的访问模式(access pattern)将数据预先读入缓存行。
围绕缓存行的数据访问形式会影响应用程序的性能,例如在下面的示例中,一个应用正在访问一个二维数组,且该数组的一行数据恰好被一个缓存行所容纳。则基于行的访问方式会导致如下结果:
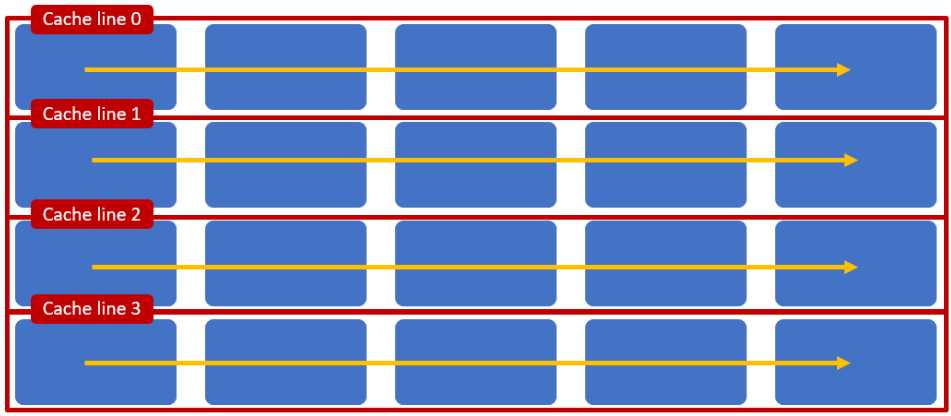
基于行的访问可以有效利用缓存结构
但是基于列的访问会导致比较糟糕的结果:
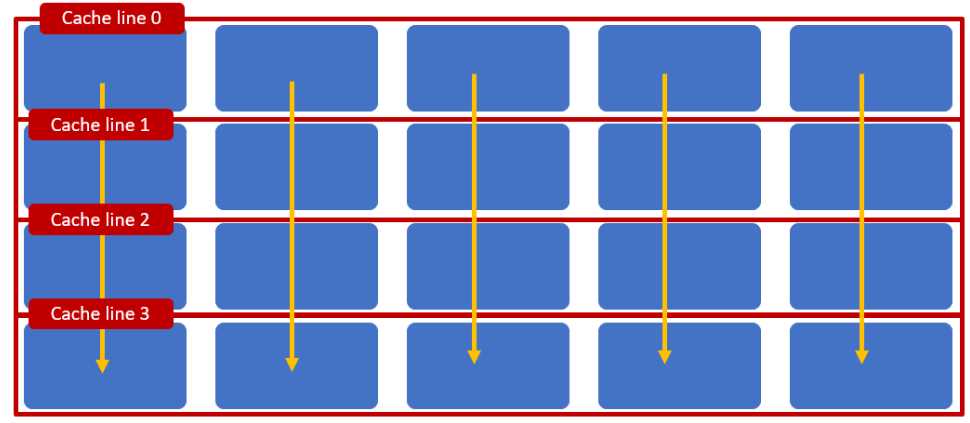
基于列的访问不能有效利用缓存结构因为它会导致cache line换入换出
* 从具体的实验可看出,随着数组大小增长,基于行的数组访问方式明显优于基于列的访问方式,实验结果:https://github.com/stephen-wang/perf_diff_of_matrix_sum
缓存的硬件结构使得其工作于基于值存储的数组或向量时表现较好。为什么这么说?现在分别针对存储值的vector和存储指针的vector, 看一下缓存行的分配情况。
对于vector<Entity *>, 每个Entity对象在堆(heap)上分配,很有可能这些对象散落于内存中不相邻的各处,从而导致处理器访问该对象时读取整个缓存行数据,即使其中包含许多和Entity对象不相干的数据。
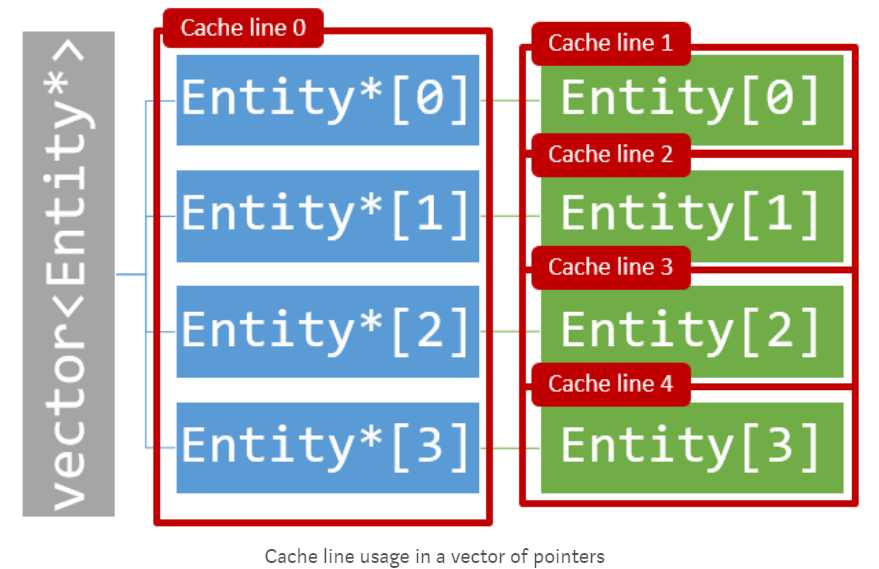
对于vector<Entity>,所有Entity对象存储在位于vector内部结构的连续空间上,这有效的降低了缓存行的的读取次数:

上面这句话看上去很绕,但通过以下示例很容易理解:下面代码依次遍历数组元组,并当该元素的某标识符为真时,进行进一步访问(读/写/改)
for (int i=0; i < 10; i++) { if (array[i].Valid) { /* Act on array entity */ ... } }
上面的for循环会把数组所有元素load进cache line (放得下的话),即使某些元素的Valid值为False:
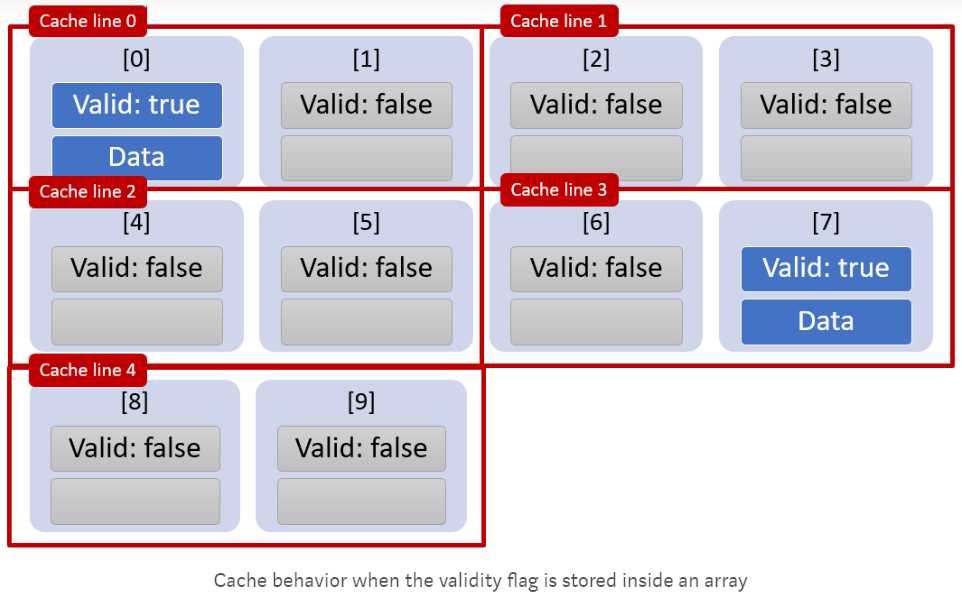
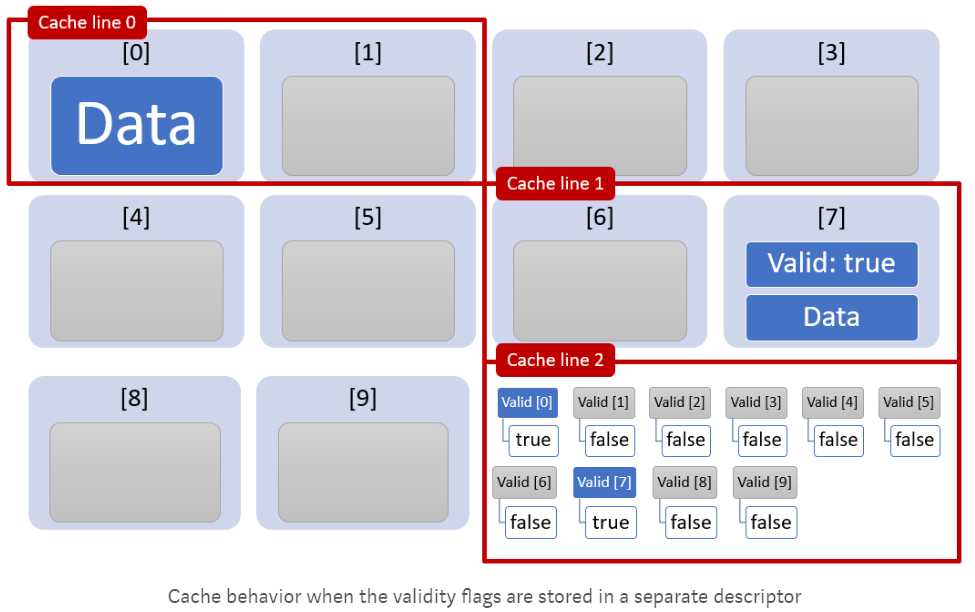
但是,如果把Valid字段单独放入一个数组,缓存性能会极大提高。这是因为该标识符数组会被读入一个单独的缓存行cache line 2, 而原数组中只有有效的元素会被读入cache line, 其他的valid标志为False的元素将被跳过:
for (int i=0; i < 10; i++) { /* The validity flags have been moved to a descriptor array */ if (array_descriptor[i].Valid) { /* Act on array entity */ ... } }
从下图看以看出,互相独立的标志符数组和数据数组可以减少数据从内存读入缓存的次数:
* 根据上述逻辑, 我实现了一个测试代码,结果显示当flag值为true个数相比总数很少(例如仅1/1000的flag值为true),数据结构大小>=1个cache line(64bytes), 总数据量为2000000时,把标识符分开存放可以提升程序性能:https://github.com/stephen-wang/perf_diff_of_flag_store
再回顾一下CPU的结构布局:我们可以发现每个CPU核都有自己的L1和L2缓存,而且所有的核共享L3缓存,这种三层体系结构会导致缓存间的一致性问题。假设最左侧的CPU核读取了一块内存数据,导致该数据载入了cache line 0, 并进一步载入了最左侧核的L1缓存。如果最右侧的CPU核此时正尝试读取某一内存数据,该数据正好也位于cache line 0. 这将触发处理器的缓存一致性过程(cache coherency procedure)从而确保cache line 0在每个核缓存中具有一致性表现。这个过程会耗费大量内存带宽,极大降低缓存性能。
L1, L2 and L3 cache
下面的例子表明一个经过缓存优化(数组中的标识符单独存放)的应用还是可能遭受缓存一致性所引起的性能衰退。设想下列数组已经被优化使得两个CPU核(蓝色和绿色, 以下称蓝核/绿核)分别访问数组中互相间隔的元素。
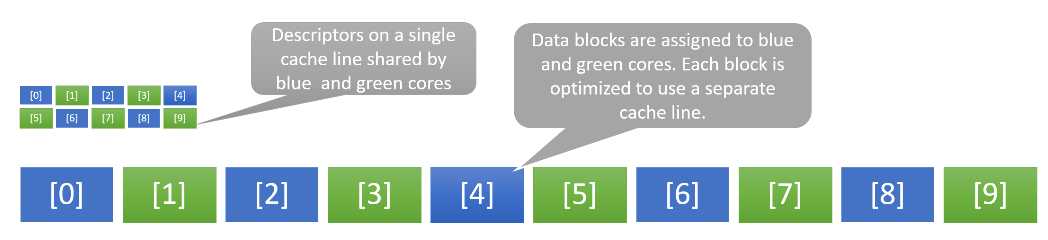
Example of false sharing due to two cores sharing a single cache line
理论上,这种优化应该让应用程序运行于双核CPU时的非标识符数据吞吐率双倍于它运行于单核CPU的结果,世界结果如何呢?因为标识符数组非常小, 所以可以被单个缓冲行(cache line)所容纳,蓝核和绿核需要访问标识符数组中相互间隔的元素,因而所访问的地址是不同的,问题是他们共享一个缓冲行,这会在两个核之间引发一致性过程(cache coherency procedures), 这被称之为false sharing.
这种问题可以通过分割标识符数组,让蓝色和绿色核所访问的标志符数据分别位于不同的cache line 来解决。
上面一直在讲数据缓存,其实代码缓存对性能提高同样的重要。
for循环中的紧凑代码更容易放入L1或L2缓存,使得CPU不必重复从内容读取同样的指令,从而提高程序的运行速度。
下面示例中,foo()函数在循环中调用bar()函数:
void bar(int index) { // Code Block 1 // Code Block 2: Uses the index parameter } void foo() { for (int i=0; i < MAX_VALUE; i++) { bar(i); // More code } }
如果编译器把bar()转为内联函数,则可以节省循环调用函数的开销,从而提高代码局部性(the locality of code). 另一个好处是,如果编译器发现 //code block1 中的代码和循环无关,该代码块会被移出循环。
经过优化后的代码如下,并且此时循环体内的代码可能已经足够精简,可以放入L1缓存来运行。
void foo() { // Code Block 1 for (int i=0; i < MAX_VALUE; i++) { // Code Block 2: Uses the loop variable i // More code } }
*: 非原文内容
原文:https://www.cnblogs.com/wangwenzhi2019/p/10907116.html