若是商业用途,请事先联系作者。
https://blog.csdn.net/zhangxiangDavaid/article/details/29844821
选择排序(Selection Sort)
? ? 经过一趟排序,能够从n-i+1(i=1,2...)个记录中选取keyword最小的记录作为有序序列中第i个记录。
也就是说。每一趟排序。都会排好一个元素的终于位置。
最简单的是
? ? 简单选择排序(Simple Selection Sort,也叫直接选择排序)
? ? 简单选择排序的思想:在每一趟排序中,通过n-i次keyword的比較,从n-i+1个记录中选出keyword最小的记录,并和第i个记录交换。以此确定第i个记录的终于位置。简单说,逐个找出第i小的记录,并将其放到数组的第i个位置。
比較简单。直接看代码;
void SimpleSelectSort(int a[], int n) //简单选择排序
{
if(a && n>1)
{
int index;
for(int i=0; i<n; i++)
{
index=i;
for(int j=i+1; j<n; j++)
{
if(a[j]<a[index])
index=j;
}
if(i!=index)
{ //交换数据。方法多种
a[i]^=a[index];
a[index]^=a[i];
a[i]^=a[index];
}
}
}
}看下代码,两个for循环,每个都与n有关,粗略预计时间复杂度是O(n^2)。
以下细致计算一下:
? ? 若初始序列是有序的,则无需移动元素。
若是逆序的。则需移动3(n-1)(这个数字有问题!
)。每确定一个元素的终于位置,swap()方法中一般3次移动,但确定了最小的。也同一时候确定了最大的。
所以这个3(n-1)不可信。
但不管怎样,它都是线性的。
不管初始序列的情况怎样,都必须进行 (n-1)+(n-2)+...2+1=n(n-1)/2 次比較。
综上所述,它的时间复杂度是O(n^2)。
与我们的预计一样。
? ? 简单选择有能够改进的地方。选择排序的主要操作在keyword的比較上。比方,在n个元素中选出最小的,要进行n-1次比較。而选出次最小的要进行n-2次比較...。为何下一趟排序,不能利用上一趟排序的比較信息呢?若是能够做到。则极大的降低下一趟排序的比較次数。
以下介绍的树形选择排序(Tree Select Sort)就是针对这样的情况进行改善的。
树形选择排序又叫锦标赛排序(Tournament Sort)。它相似于比赛的过程。
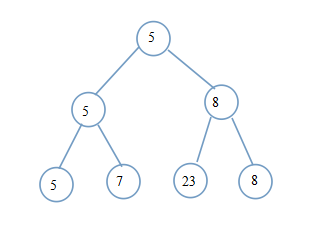
例如以下图:
? ? 叶子节点即是全部的參赛者。两两比較,胜出者參与下一轮。也就是说胜出者上升到父节点。
若是參赛者为奇数个。则最后一个參赛者直接晋级。我们按从小到大排序,故小的胜出。上图树顶根节点即最后的胜出者。
? ? 貌似我们仅仅能得到最大或最小。是这样,这仅仅是一趟排序的结果嘛。
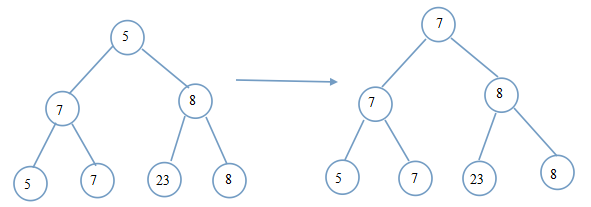
下一趟排序该怎样进行呢?做法:把胜出者的兄弟节点上升到父节点位置。
从此位置向上调整树。步骤例如以下图:
? ? 第二个胜出者是7(亚军)。显然这一趟排序,我们利用了上一趟的排序信息:8与23比較,8胜出。这一趟排序我们没有重复比較,这在元素较多时,效果更加明显。后面的以此类推。是否感觉到非常easy呢?事实上还有非常多的细节(包含一些满二叉树的知识:内节点个数和外节点个数的关系,每一层多少节点……)。
它的代码非常不好写。假设没有弄明确过程。也非常难看懂!
? ? 比方,上文的黑体字:把胜出者的兄弟节点上升到父节点位置。看到这句话时,你是否想过:假设兄弟节点已经出局了呢?上图中。7出局后,5会被升上去。而5已经先于7出局了,这样做是否有问题呢?带着这些疑问,重复细致看以下的代码(结合后面的提示):
#include<iostream>
#include<math.h>
#include<iomanip>
using namespace std;
typedef struct rec
{
int data;
int index;
bool active; //节点未出局,则是true,其他false
}Rec;
void fixUpTree(Rec* tree, int pos) //从pos位置向上调整
{
int i = pos;
if (i % 2) //i位于右子树
tree[(i - 1) / 2] = tree[i + 1]; //左孩子上升到父节点
else
tree[(i - 1) / 2] = tree[i - 1]; //右孩子上升到父节点
i = (i - 1) / 2;
int j;
while (i) //上升到根节点,则终止循环
{
i % 2 ? j = i + 1 : j = i - 1; //确定i的兄弟j的下标
if (!tree[i].active || !tree[j].active) //左右孩子有一个为空
{
if (tree[i].active)
tree[(i - 1) / 2] = tree[i];
else
tree[(i - 1) / 2] = tree[j];
}
else //左右孩子都不为空
{
if (tree[i].data <= tree[j].data)
tree[(i - 1) / 2] = tree[i];
else
tree[(i - 1) / 2] = tree[j];
}
i = (i - 1) / 2; //回到上一层
}
}
void TreeSelectSort(int a[], int n) //树形选择排序
{
int i = 0;
while (pow(double(2), i) < n)
i++;
int leaf = pow(2, i); //全然二叉树叶子节点个数
int size = 2 * leaf - 1; //树节点总数 提示3
Rec *tree = new Rec[size]; //顺序存储一棵树
for (i = 0; i < leaf; i++)
{
if (i < n)
{
//leaf-1是叶子节点的起始下标。想想是这样吗?
tree[i + leaf - 1].data = a[i];
tree[i + leaf - 1].index = i;
tree[i + leaf - 1].active = true;
}
else//叶子节点下标从 leaf-1+n開始。后面都是空的,无此參赛者
tree[i + leaf - 1].active = false;
}
i = leaf - 1; //提示3
int j;
while (i) //上升到根节点,则终止循环
{
j = i;
while (j<2 * i) //以下的提示4
{
//无右节点或右节点已出局。即使存在右节点。其值域也比左节点大
if (!tree[j + 1].active || tree[j + 1].data>tree[j].data)
tree[(j - 1) / 2] = tree[j];
else
tree[(j - 1) / 2] = tree[j + 1];
j += 2; //两两比較
}
i = (i - 1) / 2; //回到上一层
}
i = 0;
while (i < n - 1) //确定剩下的n-1个节点的次序
{
a[i] = tree[0].data;
tree[leaf - 1 + tree[0].index].active = false; //出局,不參与下一轮
//每次出局后都需调整
fixUpTree(tree, leaf - 1 + tree[0].index);
i++;
}
a[n - 1] = tree[0].data; //最后一个归位
delete[]tree;
}1、理解了标志位active的作用,就可解释上面的疑问。
2、对一棵满二叉树按层次遍历顺序存储,下标从0開始。若i是父亲,则2*i+1是其左孩子,2*i+2是其右孩子。而且。不管i是左孩子还是右孩子,(i-1)/2都是其父亲。动动小手,绘图理解哦!
3、对于满二叉树。外节点(叶子节点)数比内部节点(非叶节点)多一个。
叶子节点的起始下标是leaf-1。leaf是叶子节点个数。
不清楚就动手绘图哦!
4、对于满二叉树。每一层最后一个节点的下标是第一个节点下标的2倍。
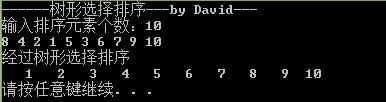
以下用主函数測试下:
int main()
{
cout << "------树形选择排序---by David---" << endl;
int n;
cout << "输入排序元素个数:";
scanf_s("%d", &n);
int *array = new int[n];
int i = 0;
while (i < n)
{
scanf_s("%d", &array[i]);
i++;
}
cout << "经过树形选择排序" << endl;
TreeSelectSort(array, n);
for (i = 0; i < n; i++)
cout << setw(4) << array[i];
cout << endl;
delete[]array;
system("pause");
return 0;
}转载请注明出处,本文地址:http://blog.csdn.net/zhangxiangdavaid/article/details/29844821
若是有所帮助。顶一个哦!
代码就是折腾。多折腾多进步!
专栏文件夹看这里:
原文:https://www.cnblogs.com/ldxsuanfa/p/10932769.html