Shuffle本意是 混洗, 洗牌的意思, 在MapReduce过程中需要各节点上同一类数据汇集到某一节点进行计算,把这些分布在不同节点的数据按照一定的规则聚集到一起的过程成为Shuffle.
在Hadoop的MapReduce框架中, Shuffle是连接Map和Reduce之间的桥梁, Map的数据要用到Reduce中必须经过Shuffle这个环节. 由于Shuffle涉及到磁盘的读写和网络的传输, 所以Shuffle的性能高低直接影响到整个程序的性能和吞吐量.
 ?
?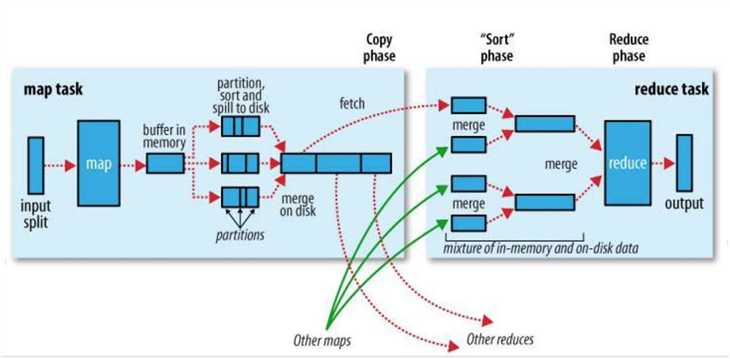
这张图是官网对Shuffle过程的描述,我们来分别看下map端和reduce端做了什么, 如何做的.
上面就是MapReduce的Shuffle过程, 其实Spark2.0之后的Shuffle过程与MapReduce的基本一致,都是基于排序的,早期spark版本中的shuffle是基于hash的,让我们来一起看下.
Spark有两种Shuffle机制. 一种是基于Hash的Shuffle, 还有一种是基于Sort的Shuffle.在Shuffle机制转变的过程中, 主要的一个优化点就是产生的小文件个数.
 ?
?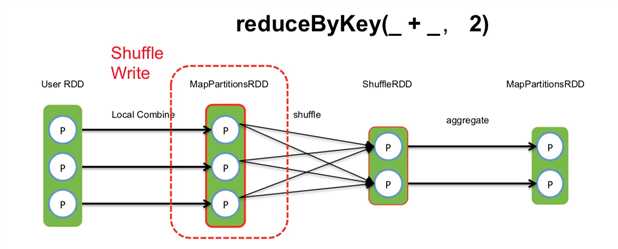
以上图为例,在Spark的算子reduceByKey(_ + _, 2)产生的shuffle中,我们先看Shuffle Write阶段.
 ?
?
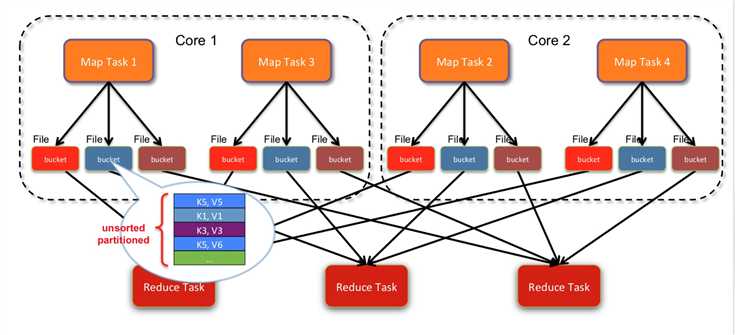
如图所示, hash-based的Shuffle, 每个map会根据reduce的个数创建对应的bucket, 那么bucket的总数量是: M * R (map的个数 * reduce的个数).
(假如分别有1k个map和reduce,将产生1百万的小文件!)
如上图所示,2个core, 4个map task, 3个reduce task 产生了4*3 = 12个小文件.(每个文件中是不排序的)
由于hash-based产生的小文件太多, 对文件系统的压力很大, 后来做了优化.
把同一个core上的多个map输出到同一个文件. 这样文件数就变成了 core * R个.如下图: ?
?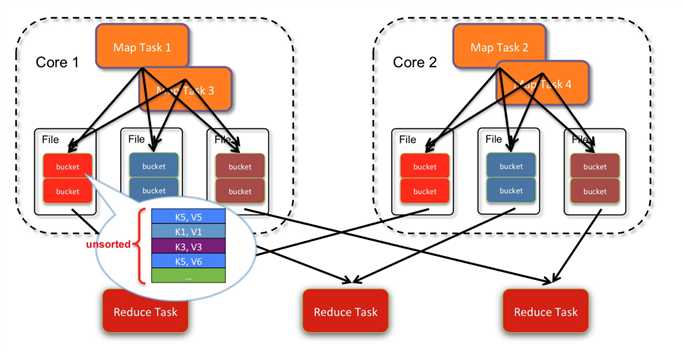
2个core, 4个map task, 3个 reduce task, 产生了2*3 = 6个文件.
(每个文件中仍然不是排序的)
由于优化后的hash-based Shuffle的文件数为: core * R, 产生的小文件仍然过大, 所以引入了 sort-based Shuffle ?
?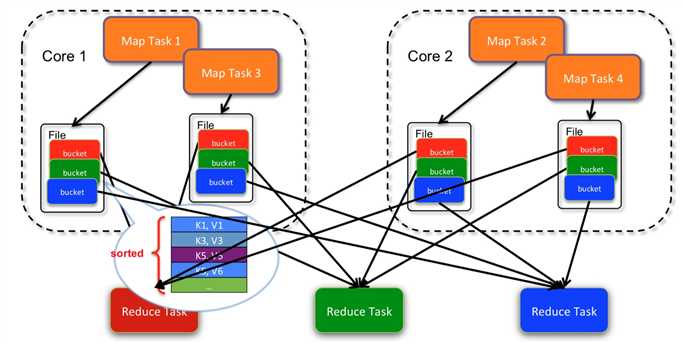
sort-based Shuffle中, 一个map task 输出一个文件.
文件在一些到磁盘之前, 会根据key进行排序. 排序后, 分批写入磁盘. task完成之后会将多次溢写的文件合并成一个文件. 由于一个task只对应一个磁盘文件, 因此还会单独写一份索引文件, 标识下游各个task的数据对应在文件中的起始和结束offset.

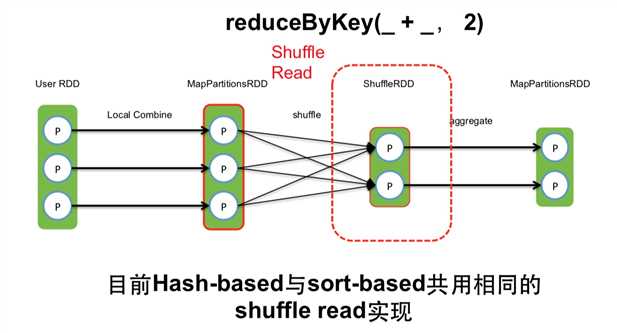
目前,hash-based 和 sort-based写方式公用相同的shuffle read.
如下图所示: 
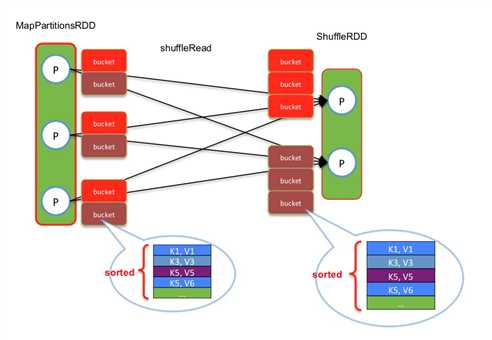
shuffle read task从多个map的输出文件中fetch自己需要的已排序好的数据.
read task 会先从索引文件中获取自己需要的数据对应的索引, 在读文件的时候跳过对应的Block数据区, 只读当前自己这个task需要的数据.
当 parent stage 的所有ShuffleMapTasks结束后再fetch(这里和MapReduce不同). 理论上讲, 一个ShuffleMapTask结束后就可以fetch, 但是为了迎合 stage 的概念(即一个stage如果其parent stages没有执行完,自己是不能被提交执行的),还是选择全部ShuffleMapTasks执行完再去 etch.因为fetch来的 FileSegments要先在内存做缓冲(默认48MB缓冲界限), 所以一次fetch的 FileSegments总大小不能太大. 一个 softBuffer里面一般包含多个 FileSegment,但如果某个FileSegment特别大的话, 这一个就可以填满甚至超过 softBuffer 的界限.
边 fetch 边处理.本质上,MapReduce shuffle阶段就是边fetch边使用 combine()进行处理,只是combine()处理的是部分数据. MapReduce为了让进入 reduce()的records有序, 必须等到全部数据都shuffle-sort后再开始 reduce(). 因为Spark不要求shuffle后的数据全局有序,因此没必要等到全部数据 shuffle完成后再处理.
那么如何实现边shuffle边处理, 而且流入的records是无序的?答案是使用可以 aggregate 的数据结构, 比如 HashMap. 每从shuffle得到(从缓冲的 FileSegment中deserialize出来)一个 <key, value="">record, 直接将其放进 HashMap 里面.如果该HashMap已经存在相应的 Key. 那么直接进行 aggregate 也就是 func(hashMap.get(Key), Value).
shuffle read task拿到多个map产生的相同的key的数据后,需要对数据进行聚合,把相同key的数据放到一起,这个过程叫做aggregate. ?
?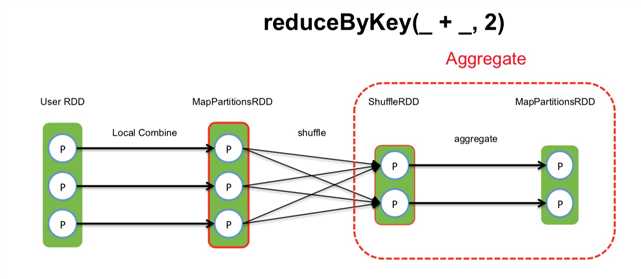
大致过程如下图:  ?
?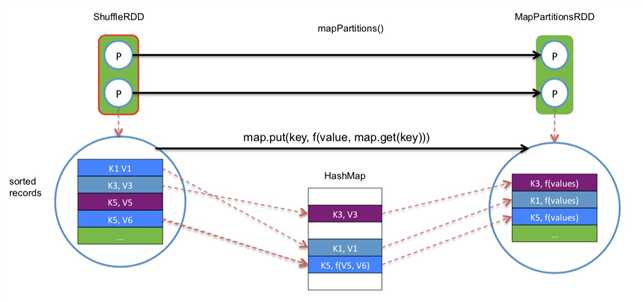
task把读来的 records 被逐个 aggreagte 到 HashMap 中,等到所有 records 都进入 HashMap,就得到最后的处理结果。
刚 fetch 来的 FileSegment 存放在 softBuffer 缓冲区,经过处理后的数据放在内存 + 磁盘上。
其实MapReduce Suffle 和 Spark的Shuffle在主要方面还是基本一致的, 比如:都是基于sort的.
细节上有一些区别, 比如 mapreduce完成一个map,就开始reduce, 而spark由于stage的概念,需要等所有ShuffleMap完成再ShuffleReduce.
大话Spark(4)-一文理解MapReduce Shuffle和Spark Shuffle
原文:https://www.cnblogs.com/wangtcc/p/10936521.html