数据解析原理 定位标签 提取标签中存储的数据
xpath解析原理 实例化一个etree的对象且将解析的页面源码数据加载到该对象中 通过xpath方法(返回值:列表)结合着xpath表达式进行数据解析 //tagName //tagName[@attr=‘value‘] //定位所有的tagName //tagName[index] /text() 返回1个 //text() 返回多个列表 /@attrName
bs4解析原理 实例化一个bs的对象且将解析的页面源码数据加载到该对象中 通过相关的方法和属性进行数据解析 soup.tagName soup.find(‘tagName‘,attrName="value") / find_all() #属性定位 select(‘选择器‘):标签,类,id,层级 #选择器 string,text,get_text() tag[‘attrName‘] 面试题:如何解析一个页面中携带html标签的局部内容? bs4:解析的过程中,定位的标签可以打印,再次调用才可以取出,xpath需要做额外的处理
爬取简历的过程中可能出现的问题?解决方案
(1)#http连接池,短时间内的高频请求
HTTPConnectionPool(host:XX)Max retries exceeded with url (2)及时断开连接:headers = {‘Connection‘:‘close‘,‘User-Agent‘:‘xxx‘} 更换请求对应的ip
换用自己的ip
(3)每次请求之间使用sleep进行等待间隔
代理操作 - 什么是代理? - 就是代理服务器 - 代理的网站: - 快代理(免费和付费的) - 西祠代理 - goubanjia - 代理知识:https://help.kuaidaili.com/wiki/ - 匿名度: - 透明:对方服务器可以知道你使用了代理,并且也知道你的真实IP - 匿名:对方服务器可以知道你使用了代理,但不知道你的真实IP - 高匿:对方服务器不知道你使用了代理,更不知道你的真实IP。
-goubanjia:(最新10个代理IP)
http://www.goubanjia.com/
地址加端口号
- 类型: - http:该类型的代理ip只可以发起http协议头对应的请求 - https:该类型的代理ip只可以发起https协议头对应的请求
一个代理ip也就是5-6分钟,成功率不是很高的,有时候测试不成功
https 116.62.64.196:443 117.80.92.250:3128 122.226.68.6:63000 112.84.178.21:8888 112.87.70.233:9999 http 101.132.131.158:8118 120.210.219.101:8080 106.75.212.2:8080 115.159.116.98:8118 112.65.52.28:9000 112.80.41.79:8888 112.85.170.107:9999
(1)操作:打开浏览器,搜索百度,再搜索ip,可以显示出本机的IP
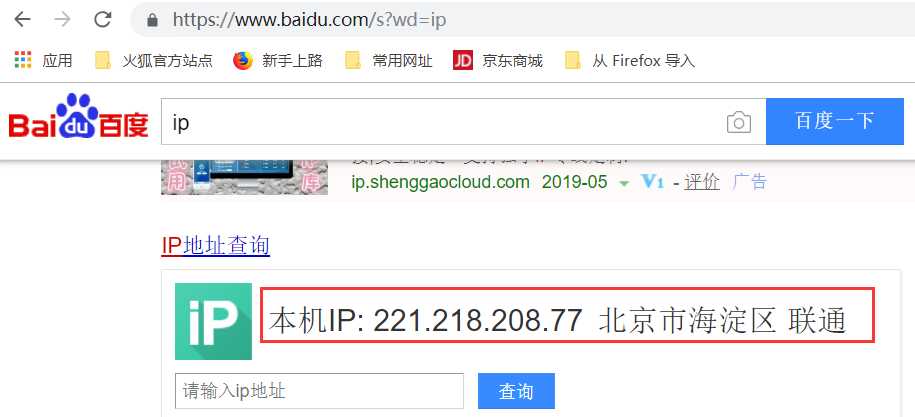
(2)
import requests headers = { ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36‘ } url=‘https://www.baidu.com/s?wd=ip‘ page_text=requests.get(url=url,headers=headers).text with open(‘./ip.html‘,‘w‘,encoding=‘utf-8‘)as fp: fp.write(page_text)
将信息写到一个界面中,注意这个界面写入到统计目录下的ip.html文件
下面我们加上代理:,也就是在get中加上代理(这个地方不一定能实验成功)
import requests headers = { ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36‘ } url=‘https://www.baidu.com/s?wd=ip‘ page_text=requests.get(url=url,headers=headers,proxies={‘https‘:‘120.234.63.196:3128‘}).text with open(‘./ip.html‘,‘w‘,encoding=‘utf-8‘)as fp: fp.write(page_text)
上边的成功可能因为代理的问题出现超时错误
西祠代理地址:https://www.xicidaili.com/?tdsourcetag=s_pctim_aiomsg
如何写一个代理池呢?不知道请求的是什么http还是https?
目的:减少代理ip被封掉的风险
https = [ {‘https‘:‘223.19.212.30:8380‘}, {‘https‘:‘221.19.212.30:8380‘} ] http = [ {‘http‘:‘223.19.212.30:8380‘}, {‘http‘:‘221.19.212.30:8380‘} ]
import random import requests headers = { ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36‘ } url = ‘https://www.baidu.com/s?wd=ip‘ if url.split(‘:‘)[0] == ‘https‘: page_text = requests.get(url=url,headers=headers,proxies=random.choice(https)).text else: page_text = requests.get(url=url,headers=headers,proxies=random.choice(http)).text with open(‘./ip.html‘,‘w‘,encoding=‘utf-8‘) as fp: fp.write(page_text)
requests的get和post方法常用的参数: url headers data/params proxies
为了实现模拟登陆,用requests模块实现.
肉眼识别&&机器识别
(1)验证码识别
云打码,打码兔,超级鹰
云打码使用流程 http://www.yundama.com/demo.html 注册:(充值1块钱) 普通用户 开发者用户 登录: 登录普通用户: 查询剩余题分 登录开发者用户: 创建一个软件:我的软件-》创建一个新软件(软件名称,秘钥不可以修改),使用软件的id和秘钥 下载示例代码:开发文档-》点此下载:云打码接口DLL-》PythonHTTP示例下载
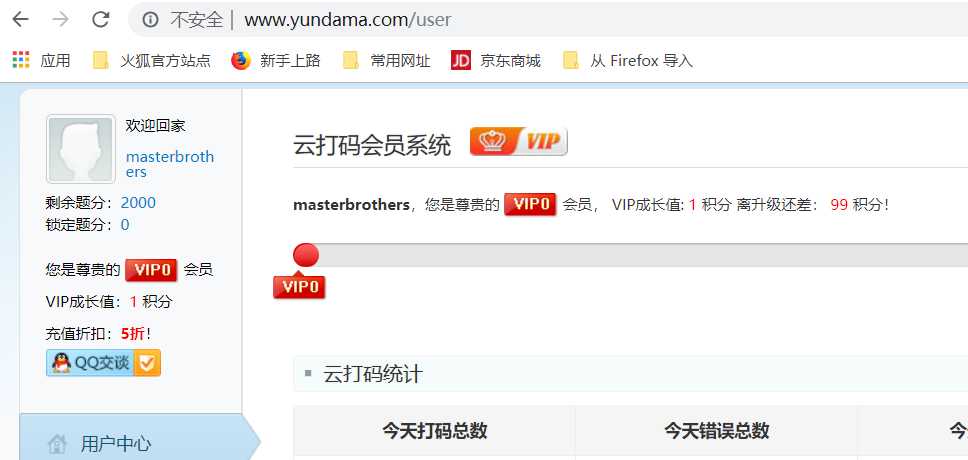
充值1块钱,得到下面的内容,2000积分,下面是普通用户
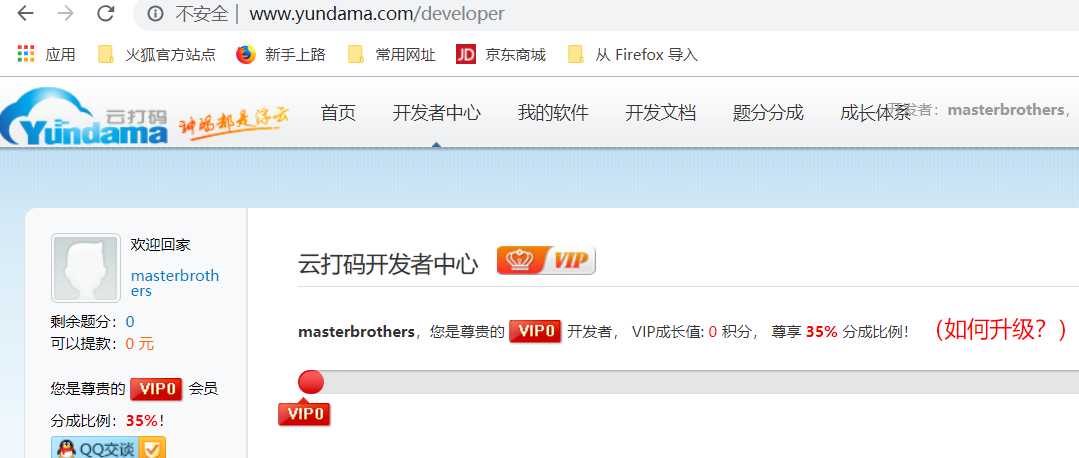
下图是"云打码开发者中心"
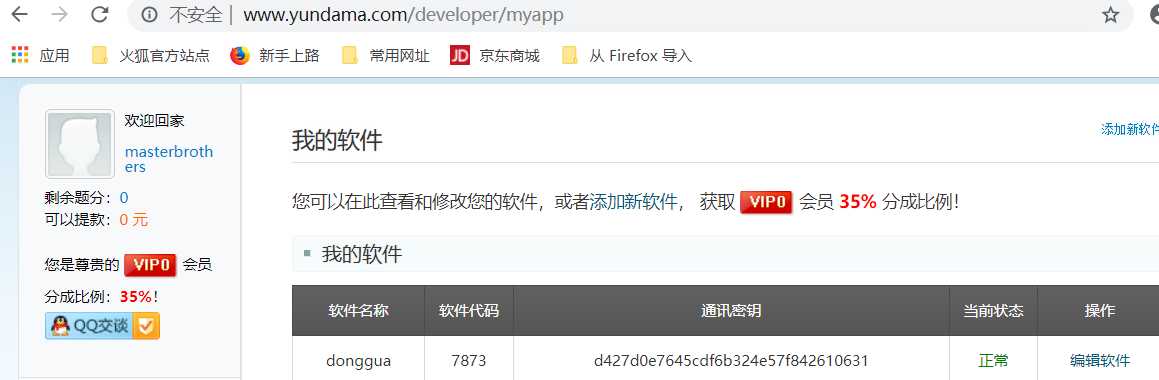
下面是我自己创建的软件,下面有三个参数
下载示例代码
第一步:

第二步:
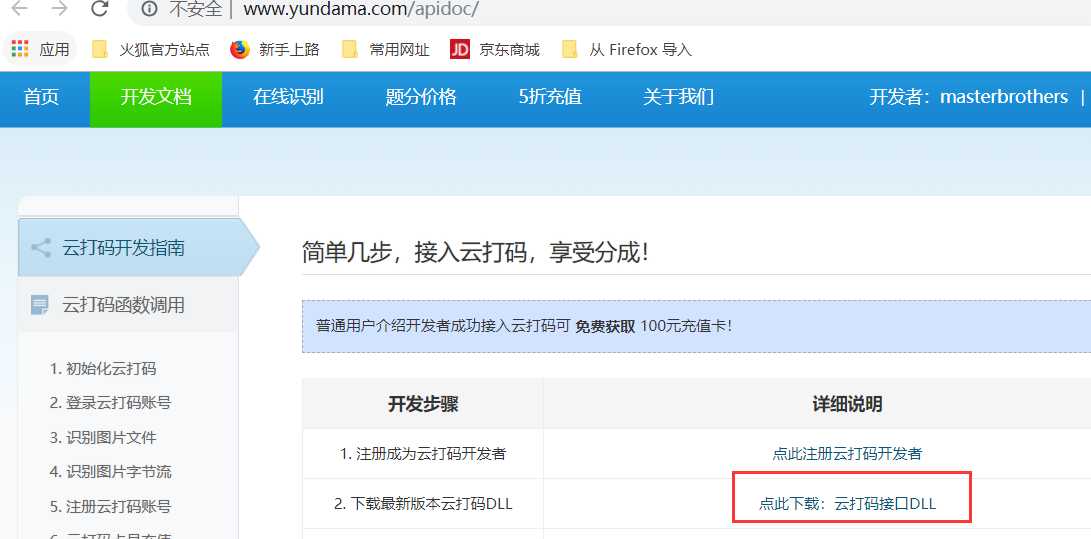
第三步:点击即可下载
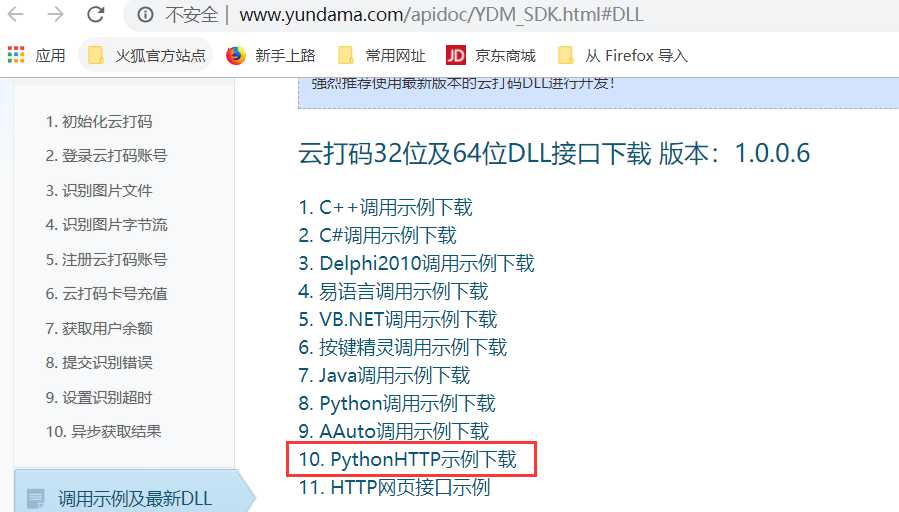
下载完成之后解压缩,放在jupyter notebook的目录下面
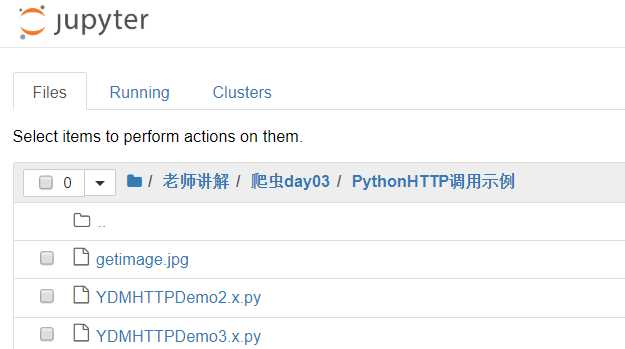
我们看到上图的文件中有三个文件.
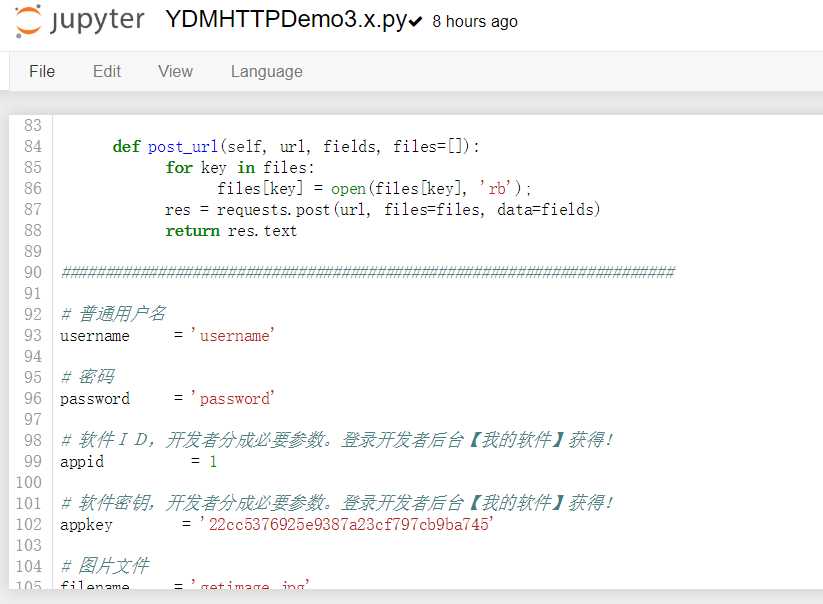
90行之前的代码我们直接用就可以了,90行下面的代码,我们需要自己进行修改.
我们要输入的用户应该是"普通用户"的用户和密码
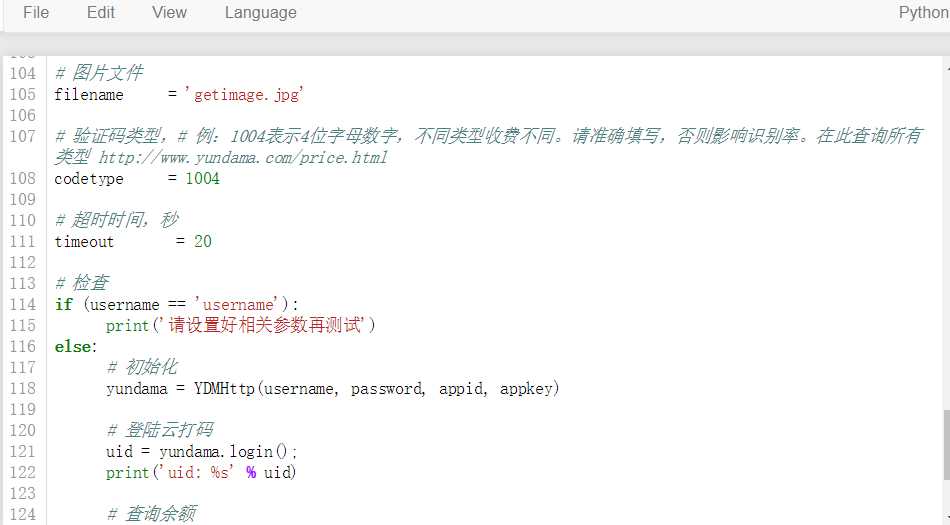

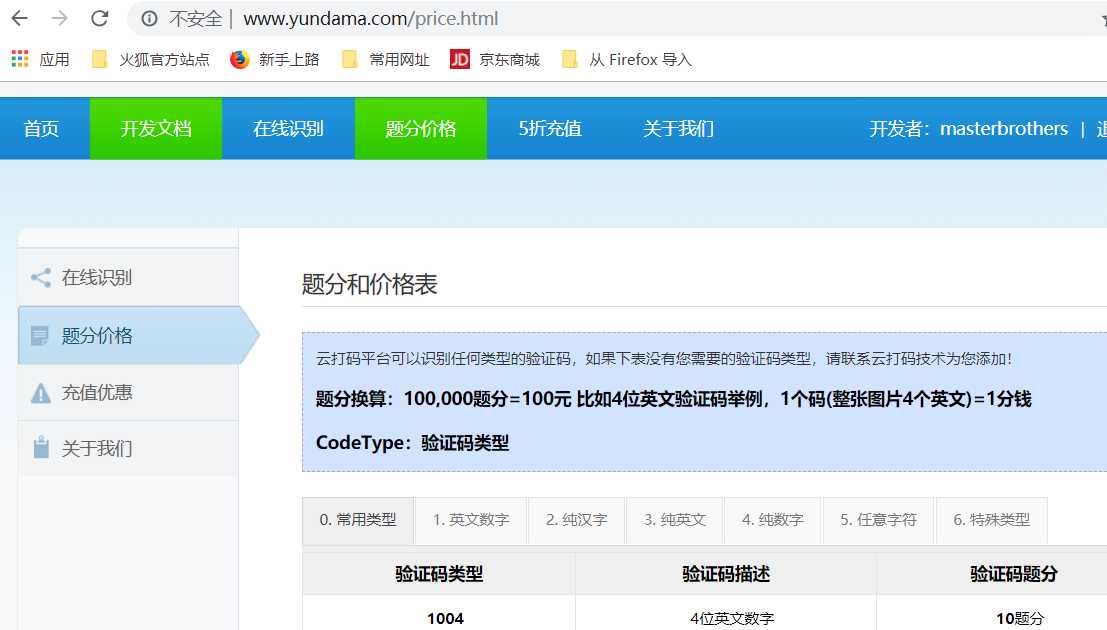
我们可以看到下面的题分价格
原文:https://www.cnblogs.com/studybrother/p/10945393.html