用户认证是通过取表单数据根数据库对应表存储的值做比对,比对成功就返回一个页面,不成功就重定向到登录页面。我们自己写的话当然也是可以的,只不过多写了几个视图,冗余代码多,当然我们也可以封装成函数,简单代码。不过推荐使用Django提供的一套用户认证组件,原理其实类似,只不过功能更强大。
在进行用户登录验证的时候,如果是自己写代码,就必须要先查询数据库,看用户输入的用户名是否存在于数据库中;如果用户存在于数据库中,然后在验证用户输入的密码,这样一来,自己就需要编写大量的代码。
事实上,Django已经提供了内置的用户认证功能,在使用“python manage.py makemigrations” 和 “python manage.py migrate” 迁移完成数据库之后,根据配置文件settings.py中的数据库段生成的数据表中已经包含了6张进行认证的数据表,分别是:
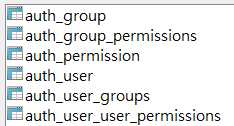
而要进行用户认证的数据表示auth_user。
要使用Django自带的认证功能,首先导入auth模块:
# auth主认证模块 from django.contrib.auth.models import auth # 对应数据库,可以创建添加记录 from django.contrib.auth.models import User
django.contrib.auth中提供了许多方法,这里主要介绍其中三个:
提供了用户认证,即验证用户名以及密码是否正确,一般需要username,password 两个关键字参数。
如果认证信息有效,会返回一个user对象。authenticate()会在User对象上设置一个属性标识那种认证后端认证了该用户,且该信息在后面的登录过程中是需要的。当我们试图登录一个从数据库中直接取出来不经过authenticate()的User对象会报错的!
user=authenticate(username="uaername",password="password")
login(HttpResponse,user)
这个函数接受一个HTTPRequest对象,以及一个通过authenticate() 函数认证的User对象。
该函数接受一个HttpRequest对象 ,以及一个认证了的User对象,此函数使用django的session框架给某个已认证的用户附加上session id等信息。
from django.shortcuts import redirect, HttpResponse
from django.contrib.auth import authenticate, login
def auth_view(request):
username = request.POST[‘username‘]
password = request.POST[‘password‘]
user = authenticate(username=username, password=password)
if user is not None:
login(request, user)
# Redirect to a success page.
return redirect("/index/")
else:
# Return an ‘invalid login‘ error message.
return HttpResponse("username or password is incorrect")
该函数实现一个用户登录的功能。它本质上会在后端为该用户生成相关session数据。
from django.contrib.auth import logout def logout_view(request): logout(request) # Redirect to a success page.
该函数接受一个HttpRequest对象,无返回值。当调用该函数时,当前请求的session信息会全部清除。该用户即使没有登录,使用该函数也不会报错。
虽然使用的logout()函数,但是其本质上还是使用的是fulsh() 。我们可以查看 auth.logout()函数的源码

从源码中发现,验证完之后,还是使用 request.session.flush() 进行删除session信息。
User对象属性:username,password(必填项) password用哈希算法保存到数据库。
django Auth模块自带User模型所包含字段
username:用户名 email: 电子邮件 password:密码 first_name:名 last_name:姓 is_active: 是否为活跃用户。默认是True is_staff: 是否为员工。默认是False is_superuser: 是否为管理员。默认是False date_joined: 加入日期。系统自动生成。
如果是真正的User对象,返回值恒为True,用于检查用户是否已经通过了认证。通过认证并不意味着用户认证拥有任何权限,甚至也不检查该用户是否处于激活状态,这只是表明用户成功的通过了认证。这个方法很重要,在后台用request.user.is_authenticated()判断用户是否已经登录,如果true则可以向前台展示request.user.name。
要求:
方法一:
def my_view(request):
if not request.user.is_authenticated():
return redirect("%s?next=%s"%(settings.LOGIN_URL, request.path))
方法二:
django已经为我们设计好了一个用于此种情况的装饰器:login_required()
login_required():用来快捷的给某个视图添加登录校验的装饰器工具。
from django.contrib.auth.decorators import login_required
@login_required
def my_view(request):
...
若用户没有登录,则会跳转到django默认的登录URL ‘/accounts/login/’并传递当前访问url的绝对路径(登录成功后,会重定向到该路径)。
如果需要自定义登录的URL,则需要在settings.py文件中通过LOGIN_URL进行修改。
LOGIN_URL = ‘/login/‘ # 这里配置成你项目登录页面的路由
使用create_user辅助函数创建用户
from django.contrib.auth.models import User user = User.objects.create_user(username=" " , password =" ", email=" ")
使用create_superuser()创建超级用户
from django.contrib.auth.models import User user = User.objects.create_superuser(username=‘用户名‘,password=‘密码‘,email=‘邮箱‘,...)
is_authenticated()用来判断当前请求是否通过了认证。
用法:
def my_view(request):
if not request.user.is_authenticated():
return redirect(‘%s?next=%s‘ % (settings.LOGIN_URL, request.path))
使用check_password(passwd)来检查密码是否正确,密码正确的话返回True,否则返回False。
ok = user.check_password(‘密码‘)
使用set_password() 来修改密码,接受要设置的新密码作为参数。
用户需要修改密码的时候,首先让他输入原来的密码,如果给定的字符串通过了密码检查,返回True
注意:设置完一定要调用用户对象的save方法
user = User.objects.get(username = ‘ ‘ ) user.set_password(password =‘‘) user.save
修改密码示例:
from django.contrib.auth.models import User
from django.shortcuts import HttpResponse
def register(request):
# 创建用户
user_obj = User.objects.create_user(username=‘james‘, password=‘123‘)
# 检查密码(一般用于修改密码前验证)
ret = user_obj.check_password(‘123‘)
print(ret) # 返回False
# 修改密码
user_obj.set_password(‘1234‘)
# 修改后保存
user_obj.save()
# 修改后检查
ret = user_obj.check_password(‘1234‘)
print(ret) # 返回True
return HttpResponse("OK")
from django.shortcuts import render,redirect,HttpResponse
from django.contrib.auth.models import User
def create_user(request):
msg=None
if request.method=="POST":
username=request.POST.get("username"," ") # 获取用户名,默认为空字符串
password=request.POST.get("password"," ") # 获取密码,默认为空字符串
confirm=request.POST.get("confirm_password"," ") # 获取确认密码,默认为空字符串
if password == "" or confirm=="" or username=="": # 如果用户名,密码或确认密码为空
msg="用户名或密码不能为空"
elif password !=confirm: # 如果密码与确认密码不一致
msg="两次输入的密码不一致"
elif User.objects.filter(username=username): # 如果数据库中已经存在这个用户名
msg="该用户名已存在"
else:
new_user=User.objects.create_user(username=username,password=password)
#创建新用户
new_user.save()
return redirect("/index/")
return render(request,"login.html",{"msg":msg})
from django.shortcuts import render, redirect, HttpResponse
from django.contrib.auth import authenticate, login, logout
from django.contrib.auth.decorators import login_required
from django.contrib.auth.models import User
@login_required
def change_passwd(request):
user = request.user # 获取用户名
msg = None
if request.method == ‘POST‘:
old_password = request.POST.get("old_password", "") # 获取原来的密码,默认为空字符串
new_password = request.POST.get("new_password", "") # 获取新密码,默认为空字符串
confirm = request.POST.get("confirm_password", "") # 获取确认密码,默认为空字符串
if user.check_password(old_password): # 到数据库中验证旧密码通过
if new_password or confirm: # 新密码或确认密码为空
msg = "新密码不能为空"
elif new_password != confirm: # 新密码与确认密码不一样
msg = "两次密码不一致"
else:
user.set_password(new_password) # 修改密码
user.save()
return redirect("/index/")
else:
msg = "旧密码输入错误"
return render(request, "change_passwd.html", {"msg": msg})
功能就是用session记录登录验证状态,但是前提是要使用Django自带的auth_user,所以我们需要创建超级用户。下面都会说到。其用户认证组件最大的优点就是 request.user 是一个全局变量,在任何视图和模板中都能直接使用。
重点是下面:
if not:
auth.logout(request, user)
#此时返回的对象 request.user == AnonymousUser()
else:
request.user == 登录对象
下面我们完成一个登陆验证信息存储功能,我们使用的就是上面讲到的auth模块的authenticate()函数。上面也说到了,authenticate()提供了用户认证,即验证用户名和密码是否正确,如果认证信息有效的话,会返回一个user对象。
由于User表不是我们创建的,而且人家密码是加密的,如何加密我们并不知道。所以提取认证方式只能使用人家设置的认证方式。
我们要的是,创建一个超级用户,然后写一个登录验证函数,如果验证成功,进入索引界面。如果验证失败,则继续留在验证页面。
首先,我们创建一个超级用户:
python manage.py createsuperuser
名称为 james, 密码为 123。我们在数据库的 auth_user中查看:

然后我们完成登录验证函数和简单的索引函数。
from django.shortcuts import render, HttpResponse, redirect
# Create your views here.
from django.contrib import auth
from django.contrib.auth.models import User
from auth_demo import models
def login(request):
if request.method == ‘POST‘:
user = request.POST.get(‘user‘)
pwd = request.POST.get(‘pwd‘)
# if 验证成功返回 user 对象,否则返回None
user = auth.authenticate(username=user, password=pwd)
if user:
# request.user : 当前登录对象
auth.login(request, user)
# return HttpResponse("OK")
return redirect(‘/auth/index‘)
return render(request, ‘auth/login.html‘)
def index(request):
print(‘request.user‘, request.user.username)
print(‘request.user‘, request.user.id)
# 下面是判断是是否是匿名
print(‘request.user‘, request.user.is_anonymous)
if request.user.is_anonymous:
# if not request.user.authenticated():
return redirect(‘/auth/login‘)
username = request.user.username
return render(request, ‘auth/index.html‘, locals())
下面写一个简单的login页面 和 index页面。
login.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>login page</h1>
<form action="" method="post">
{% csrf_token %}
<p>username:<input type="text" name="user" ></p>
<p>password:<input type="password" name="pwd"></p>
<p><input type="submit" value="提交"></p>
</form>
</body>
</html>
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>this is index page</h1>
<p>{{ username }}</p>
</body>
</html>
下面进入登录界面,如果登录成功,则进入索引界面,我们输入正确的账号和密码。

点击提交如下:

上面我们也说了,用户注销的话,我们可以使用request.session.fulsh()。但是Django自带了auth.logout()函数,为什么使用这个呢?其实我们前面也看了源码。在进行验证后,使用request.session.fulsh(),但是他最后使用了匿名函数 AnonymousUser()。
下面我们写一个注销函数:
def logout(request):
auth.logout(request)
return redirect(request, ‘/auth/login/‘)
其实非常简单,注销后,将页面重定向到登录页面。我们在前台索引页面,加上一个注销的功能:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>this is index page</h1>
<p>{{ username }}</p>
<a href="/auth/login">注销</a>
</body>
</html>
点进去索引界面如下:
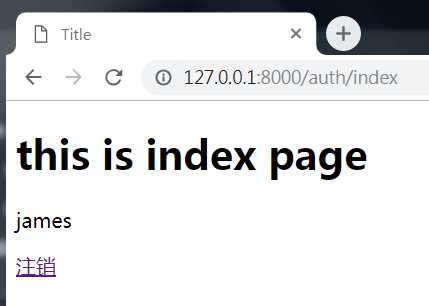
我们点击注销,则返回到登录页面,如下:

点击注销后,我们可以去数据库查看 django_session 的内容,会发现,注销后,一条记录就没有了。
在上面用户登录的时候,我们会发现有一行代码,是
user = auth.authenticate(username=user, password=pwd)
也就是说,数据库已经存在了数据,那么要是没数据的话,我们怎么办?
下面我们演示一个注册用户的功能。
我们将数据从前台拿过来,我们下面就是插入数据到User表中,这里注意的是,我们不能直接插入,比如下面:
user = User.objects.create(username=user, password=pwd)
上面插入时是明文插入,但是我们不能这样,我们需要插入的是加密后的密码,所以使用下面代码:
user = User.objects.create_user(username=user, password=pwd)
OK,说完注意点,我们写注册视图函数:
def register(request):
if request.method == ‘POST‘:
user = request.POST.get(‘user‘)
pwd = request.POST.get(‘pwd‘)
user = User.objects.create_user(username=user, password=pwd)
return HttpResponse("OK")
return render(request, ‘auth/register.html‘)
当我们注册成功后,显示OK即可(简单方便)。
注册页面和登录类似,我们展示如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>register page</h1>
<form action="" method="post">
{% csrf_token %}
<p>username:<input type="text" name="user" ></p>
<p>password:<input type="password" name="pwd"></p>
<p><input type="submit" value="提交"></p>
</form>
</body>
</html>
注册页面如下:

我们注册一个 durant,我们在 auth_user 数据库中查看结果:
注册成功如下:

auth_user 数据表如下:

这表明我们注册成功了。
为什么要用认证装饰器呢?
在以后的代码中,我们肯定需要很多认证登录,如果验证成功,则进入登录页面,如果验证不成功,则返回到登录页面。那么为了避免代码的冗余,我们可以写一个装饰器的东西,不过Django已经为我们准备好了,我们只需要用就行。
验证装饰器:看那些页面需要登录才能访问,如果没有登录跳转设置的页面去。
注意:在settings.py中设置如下:
# 用于auth模块 装饰器校验返回页面 LOGIN_URL = ‘/login/‘
在django项目中,经常看有下面的代码:
from django.contrib.auth.decorators import login_required
from django.contrib.auth.models import User
@login_required
def my_view(request):
pass
里面有一个@login_required标签。其作用就是告诉程序,使用这个方法是要求用户登录的。
下面举个例子:
def index(request):
username = request.user.username
return render(request, ‘auth/index.html‘, locals())
我们访问上面已经完成的 index页面,我们会发现:

当我们给 index 视图函数加上装饰器,代码如下:
from django.contrib.auth.decorators import login_required
@login_required
def index(request):
username = request.user.username
return render(request, ‘auth/index.html‘, locals())
我们再来访问:

下面说一下,URL是什么意思呢?

1,如果用户还没有登录,默认会跳转到‘/accounts/login/‘。这个值可以在settings文件中通过LOGIN_URL参数来设定。(后面还会自动加上你请求的url作为登录后跳转的地址,如:/accounts/login/?next=/auth/index/ 登录完成之后,会去请求)
# 如果不添加该行,则在未登陆状态打开页面的时候验证是否登陆的装饰器跳转到/accounts/login/下面 # 第一张方法就是修改settings.py 中的 LOGIN_URL LOGIN_URL = "/login/"
如下:

为什么会报错呢?因为我们没有设置其路径。
我们在settings.py中设置登录URL(当然这是我自己的路由地址):
# 这里配置成项目登录页面的路由 LOGIN_URL = ‘/auth/login‘
下面访问 index则如下:

没有用户没有登录的话,则直接跳转到登录页面。
我们不能讲登录视图函数的代码写死,这里改进一下,如下:
def login(request):
if request.method == ‘POST‘:
user = request.POST.get(‘user‘)
pwd = request.POST.get(‘pwd‘)
# if 验证成功返回 user 对象,否则返回None
user = auth.authenticate(username=user, password=pwd)
if user:
# request.user : 当前登录对象
auth.login(request, user)
next_url = request.GET.get(‘next‘, ‘auth/index‘)
return redirect(next_url)
return render(request, ‘auth/login.html‘)
如果验证成功,我们跳转到 next_url,如果获取不到,则跳转到index页面。
2,如果用户登录了,那么该方法就可以正常执行
如果LOGIN_URL使用默认值,那么在urls.py中还需要进行如下设置:
# 第二种解决方法是在 url 中匹配该url (r‘^accounts/login/$‘, ‘django.contrib.auth.views.login‘),
这样的话,如果未登录,程序会默认跳转到“templates/registration/login/html” 这个模板。
如果想换个路径,那就在加个template_name参数,如下:
(r‘^accounts/login/$‘, ‘django.contrib.auth.views.login‘,
{‘template_name‘: ‘myapp/login.html‘}),
这样程序就会跳转到 template/myapp/login.html 中。
我在之前的Django学习笔记(2):模板后台管理和视图的学习 中学习了视图层,并对其有了大概的理解。现在再进一层的学习视图层中request属性和HttpResponse对象的方法。
一个视图函数,简称视图,是一个简单的Python函数,它接受Web请求并返回Web响应。响应可以是一张网页的HTML内容,一个重定向,一个404错误,一个XML文档,或者一张图片...是任何东西都可以。无论视图本身包含什么逻辑,都要返回响应。为了将代码放在某处,约定是将视图放置在项目或者应用程序目录中的名为 views.py 的问卷中。
下面是一个返回当前日期和时间作为HTML 文档的视图:
from django.shortcuts import render, HttpResponse, HttpResponseRedirect, redirect
import datetime
def current_datetime(request):
now = datetime.datetime.now()
html = "<html><body>It is now %s.</body></html>" % now
return HttpResponse(html)
我们来逐行阅读上面的代码:
而视图层中,熟练掌握两个对象:请求对象(request)和响应对象(HttpResponse)
django将请求报文中的请求行,首部信息,内容主体封装成 HttpRequest 类中的属性。除了特殊说明之外,其他的均为只读。
1.HttpRequest.GET
一个类似于字典的对象,包含 HTTP GET 的所有参数。详情请参考 QueryDict 对象。
2.HttpRequest.POST
一个类似于字典的对象,如果请求中包含表单数据,则将这些数据封装成 QueryDict 对象。
POST 请求可以带有空的 POST 字典 —— 如果通过 HTTP POST 方法发送一个表单,但是
表单中没有任何的数据,QueryDict 对象依然会被创建。
因此,不应该使用 if request.POST 来检查使用的是否是POST 方法;
应该使用 if request.method == "POST"
另外:如果使用 POST 上传文件的话,文件信息将包含在 FILES 属性中。
注意:键值对的值是多个的时候,比如checkbox类型的input标签,select标签,需要用:
request.POST.getlist("hobby")
3.HttpRequest.body
一个字符串,代表请求报文的主体。在处理非 HTTP 形式的报文时非常有用,
例如:二进制图片、XML,Json等。
但是,如果要处理表单数据的时候,推荐还是使用 HttpRequest.POST 。
4.HttpRequest.path
一个字符串,表示请求的路径组件(不含域名)。
例如:"/music/bands/the_beatles/"
5.HttpRequest.method
一个字符串,表示请求使用的HTTP 方法。必须使用大写。
例如:"GET"、"POST"
6.HttpRequest.encoding
一个字符串,表示提交的数据的编码方式(如果为 None 则表示使用
DEFAULT_CHARSET 的设置,默认为 ‘utf-8‘)。
这个属性是可写的,你可以修改它来修改访问表单数据使用的编码。
接下来对属性的任何访问(例如从 GET 或 POST 中读取数据)将使用新的 encoding 值。
如果你知道表单数据的编码不是 DEFAULT_CHARSET ,则使用它。
7.HttpRequest.META
一个标准的Python 字典,包含所有的HTTP 首部。具体的头部信息取决于客户端
和服务器,下面是一些示例:
CONTENT_LENGTH —— 请求的正文的长度(是一个字符串)。
CONTENT_TYPE —— 请求的正文的MIME 类型。
HTTP_ACCEPT —— 响应可接收的Content-Type。
HTTP_ACCEPT_ENCODING —— 响应可接收的编码。
HTTP_ACCEPT_LANGUAGE —— 响应可接收的语言。
HTTP_HOST —— 客服端发送的HTTP Host 头部。
HTTP_REFERER —— Referring 页面。
HTTP_USER_AGENT —— 客户端的user-agent 字符串。
QUERY_STRING —— 单个字符串形式的查询字符串(未解析过的形式)。
REMOTE_ADDR —— 客户端的IP 地址。
REMOTE_HOST —— 客户端的主机名。
REMOTE_USER —— 服务器认证后的用户。
REQUEST_METHOD —— 一个字符串,例如"GET" 或"POST"。
SERVER_NAME —— 服务器的主机名。
SERVER_PORT —— 服务器的端口(是一个字符串)。
从上面可以看到,除 CONTENT_LENGTH 和 CONTENT_TYPE 之外,请求中的任何
HTTP 首部转换为 META 的键时,都会将所有字母大写并将连接符替换为下划线最后加上
HTTP_ 前缀。
所以,一个叫做 X-Bender 的头部将转换成 META 中的 HTTP_X_BENDER 键。
8.HttpRequest.FILES
一个类似于字典的对象,包含所有的上传文件信息。
FILES 中的每个键为<input type="file" name="" /> 中的name,值则为对应的数据。
注意,FILES 只有在请求的方法为POST 且提交的<form> 带有
enctype="multipart/form-data" 的情况下才会包含数据。否则,FILES 将为一个空的
类似于字典的对象。
9.HttpRequest.COOKIES
一个标准的Python 字典,包含所有的cookie。键和值都为字符串。
10.HttpRequest.session
一个既可读又可写的类似于字典的对象,表示当前的会话。只有当Django 启用会话的支持时才可用。
完整的细节参见会话的文档。
11.HttpRequest.user(用户认证组件下使用)
一个 AUTH_USER_MODEL 类型的对象,表示当前登录的用户。
如果用户当前没有登录,user 将设置为 django.contrib.auth.models.AnonymousUser
的一个实例。你可以通过 is_authenticated() 区分它们。
例如:
if request.user.is_authenticated():
# Do something for logged-in users.
else:
# Do something for anonymous users.
user 只有当Django 启用 AuthenticationMiddleware 中间件时才可用。
-------------------------------------------------------------------------------------
匿名用户
class models.AnonymousUser
django.contrib.auth.models.AnonymousUser 类实现了
django.contrib.auth.models.User 接口,但具有下面几个不同点:
id 永远为None。
username 永远为空字符串。
get_username() 永远返回空字符串。
is_staff 和 is_superuser 永远为False。
is_active 永远为 False。
groups 和 user_permissions 永远为空。
is_anonymous() 返回True 而不是False。
is_authenticated() 返回False 而不是True。
set_password()、check_password()、save() 和delete() 引发 NotImplementedError。
New in Django 1.8:
新增 AnonymousUser.get_username() 以更好地模拟 django.contrib.auth.models.User。
1.HttpRequest.get_full_path() 返回 path,如果可以将加上查询字符串。 例如:"/music/bands/the_beatles/?print=true" 2.HttpRequest.is_ajax() 如果请求是通过XMLHttpRequest 发起的,则返回True,方法是检查 HTTP_X_REQUESTED_WITH 相应的首部是否是字符串‘XMLHttpRequest‘。 大部分现代的 JavaScript 库都会发送这个头部。如果你编写自己的 XMLHttpRequest 调用(在浏览器端),你必须手工设置这个值来让 is_ajax() 可以工作。 如果一个响应需要根据请求是否是通过AJAX 发起的,并且你正在使用某种形 式的缓存例如Django 的 cache middleware, 你应该使用 vary_on_headers(‘HTTP_X_REQUESTED_WITH‘) 装饰你的视图 以让响应能够正确地缓存。
响应对象主要有三种形式:
HttpResponse() 括号内直接跟一个具体的字符串作为响应体,比较直接很简单,所以这里不多说。
但是需要注意的是,无论是下面的render() 还是 redirect() 最终还是调用HttpResponse,只不过在过程中使用Django的模板语法封装了内容。
我们下面展示一下render() redirect()的源码:


下面直接看着两个响应对象。
render(request, template_name[, context]) 结合一个给定的模板和一个给定的上下文字典,并返回一个渲染后的 HttpResponse 对象。
参数意义:
总之,render方法就是将一个模板页面中的模板语法进行渲染,最终渲染成一个HTML页面作为响应体。
举个例子:
def logout(request):
# del request.session[‘is_login‘]
request.session.flush()
return render(request, ‘session/a.html‘)
传递要重定向的一个硬编码的URL
def my_view(request):
...
return redirect(‘/some/url/‘)
也可以是一个完整的URL:
def my_view(request):
...
return redirect(‘http://example.com/‘)
key:两次请求
1)301和302的区别。
301和302状态码都表示重定向,就是说浏览器在拿到服务器返回的这个状态码
后会自动跳转到一个新的URL地址,这个地址可以从响应的Location首部中获取
(用户看到的效果就是他输入的地址A瞬间变成了另一个地址B)——这是它们的共同点。
他们的不同在于。301表示旧地址A的资源已经被永久地移除了(这个资源不可访问了),
搜索引擎在抓取新内容的同时也将旧的网址交换为重定向之后的网址;
302表示旧地址A的资源还在(仍然可以访问),这个重定向只是临时地从旧地址A跳转
到地址B,搜索引擎会抓取新的内容而保存旧的网址。 SEO302好于301
2)重定向原因:
(1)网站调整(如改变网页目录结构);
(2)网页被移到一个新地址;
(3)网页扩展名改变(如应用需要把.php改成.Html或.shtml)。
这种情况下,如果不做重定向,则用户收藏夹或搜索引擎数据库中旧地址只能让访问
客户得到一个404页面错误信息,访问流量白白丧失;再者某些注册了多个域名的 网站,
也需要通过重定向让访问这些域名的用户自动跳转到主站点等。
举个例子:
def order(request):
if not request.user.is_authenticated:
return redirect(‘auth/login/‘)
return render(request, ‘auth/order.html‘)
Django ORM用到三个类:Manager,QuerySet,Model。
Manager定义表级方法(表级方法就是影响一条或多条记录的方法),我们可以以model.Manager为父类,定义自己的manager,增加表级方法;
QuerySet:Manager类的一些方法会返回QuerySet实例,QuerySet是一个可遍历结构,包含一个或多个元素,每个元素都是一个Model实例,它里面的方法也是表级方法;
Model是指django.db.models模块中的Model类,我们定义表的model时,就是继承它,它的功能很强大,通过自定义model的instance可以获取外键实体等,它的方法都是基类级方法,不要在里面定义类方法,比如计算记录的总数,查看所有记录,这些应该放在自定义的manager类中。
每个Model都有一个默认的manager实例,名为objects,QuerySet有两种来源:通过manager的方法得到,通过QuerySet的方法得到。manager的方法和QuerySet的方法大部分同名,同意思,如 filter(),update()等,但是也有些不同,如 manager有 create(),get_or_create(),而QuerySet有delete() 等,看源码就可以很容易的清楚Manager类和QuerySet类的关系,Manager类的绝大部分方法是基于QuerySet的。一个QuerySet包含一个或多个model instance。QuerySet类似于Python中的list,list的一些方法QuerySet也有,比如切片,遍历。
QuerySet是查询集,就是传到服务器上的url里面的内容,Django会对查询返回的结果集QuerySet进行缓存,这是为了提高查询效率。也就是说,在创建一个QuerySet对象的时候,Django不会立即向数据库发出查询命令,只有在你需要用到这个QuerySet的时候才会去数据库查询。
object是Django实现的MCV框架中的数据层(model)M,django中的模型类都有一个object对象,他是django中定义的QuerySet类型的对象,他包含了模型对象的实例。
简单来说,object是单个对象,QuerySet是多个对象。
在内部,创建,过滤,切片和传递一个QuerySet不会真实操作数据库,在你对查询集提交之前,不会发生任何实际的数据库操作。
可以使用下列方法对QuerySet提交查询操作。
QuerySet是可迭代的,在首次迭代查询集中执行的实际数据库查询。例如,下面的语句会将数据库中所有entry的headline打印出来。
for e in Entry.objects.all():
print(e.headline)
切片:如果使用切片的”step“参数,Django 将执行数据库查询并返回一个列表。
Pickling/缓存
repr()
len():当你对QuerySet调用len()时, 将提交数据库操作。
list():对QuerySet调用list()将强制提交操作entry_list = list(Entry.objects.all())
bool()
测试布尔值,像这样:
if Entry.objects.filter(headline="Test"):
print("There is at least one Entry with the headline Test")
注:如果你需要知道是否存在至少一条记录(而不需要真实的对象),使用exists() 将更加高效。
下面对QuerySet正式定义:
class QuerySet(model=None, query=None, using=None)[source]
所谓惰性机制:Publisher.objects.all() 或者.filter()等都只是返回了一个QuerySet(查询结果集对象),它并不会马上执行sql,而是当调用QuerySet的时候才执行。
QuerySet特点:
#objs=models.Book.objects.all()#[obj1,obj2,ob3...]
#QuerySet: 可迭代
# for obj in objs:#每一obj就是一个行对象
# print("obj:",obj)
# QuerySet: 可切片
# print(objs[1])
# print(objs[1:4])
# print(objs[::-1])
<1>Django的queryset是惰性的
Django的queryset对应于数据库的若干记录(row),通过可选的查询来过滤。
例如,下面的代码会得到数据库中名字为‘Dave’的所有的人:person_set = Person.objects.filter(first_name="Dave")上面的代码并没有运行任何的数据库查询。
你可以使用person_set,给它加上一些过滤条件,或者将它传给某个函数,这些操作都不
会发送给数据库。这是对的,因为数据库查询是显著影响web应用性能的因素之一。
<2>要真正从数据库获得数据,你可以遍历queryset或者使用if queryset,总之你用到
数据时就会执行sql.为了验证这些,需要在settings里加入 LOGGING(验证方式)
obj=models.Book.objects.filter(id=3)
# for i in obj:
# print(i)
# if obj:
# print("ok")
<3>queryset是具有cache的
当你遍历queryset时,所有匹配的记录会从数据库获取,然后转换成Django的model。
这被称为执行(evaluation).这些model会保存在queryset内置的cache中,这样如果你
再次遍历这个queryset, 你不需要重复运行通用的查询。
obj=models.Book.objects.filter(id=3)
# for i in obj:
# print(i)
## models.Book.objects.filter(id=3).update(title="GO")
## obj_new=models.Book.objects.filter(id=3)
# for i in obj:
# print(i) #LOGGING只会打印一次
<4> 简单的使用if语句进行判断也会完全执行整个queryset并且把数据放入cache,虽然你并
不需要这些数据!为了避免这个,可以用exists()方法来检查是否有数据:
obj = Book.objects.filter(id=4)
# exists()的检查可以避免数据放入queryset的cache。
if obj.exists():
print("hello world!")
<5>当queryset非常巨大时,cache会成为问题
处理成千上万的记录时,将它们一次装入内存是很浪费的。更糟糕的是,巨大的queryset
可能会锁住系统 进程,让你的程序濒临崩溃。要避免在遍历数据的同时产生queryset cache,
可以使用iterator()方法 来获取数据,处理完数据就将其丢弃。
objs = Book.objects.all().iterator()
# iterator()可以一次只从数据库获取少量数据,这样可以节省内存
for obj in objs:
print(obj.name)
#BUT,再次遍历没有打印,因为迭代器已经在上一次遍历(next)到最后一次了,没得遍历了
for obj in objs:
print(obj.name)
#当然,使用iterator()方法来防止生成cache,意味着遍历同一个queryset时会重复执行
查询。所以使用iterator()的时候要当心,确保你的代码在操作一个大的queryset时没有重复执行查询
总结:
queryset的cache是用于减少程序对数据库的查询,在通常的使用下会保证只有在需要的时候
才会查询数据库。使用exists()和iterator()方法可以优化程序对内存的使用。不过,由于它们并
不会生成queryset cache,可能会造成额外的数据库查询。
以下的方法不会返回QuerySets,但是作用非常强大,尤其是粗体显示的方法,需要背下来。

get(**kwargs)
返回按照查询参数匹配到的单个对象,参数的格式应该符合Field lookups的要求。
如果匹配到的对象个数不止一个的话,触发MultipleObjectsReturned异常
如果根据给出的参数匹配不到对象的话,触发DoesNotExist异常。例如:
Entry.objects.get(id=‘foo‘) # raises Entry.DoesNotExist
DoesNotExist异常从django.core.exceptions.ObjectDoesNotExist 继承,可以定位多个DoesNotExist异常,例如:
from django.core.exceptions import ObjectDoesNotExist
try:
e = Entry.objects.get(id=3)
b = Blog.objects.get(id=1)
except ObjectDoesNotExist:
print("Either the entry or blog doesn‘t exist.")
如果希望查询器只返回一行,则可以使用get() 而不使用任何参数来返回该行的对象:
entry = Entry.objects.filter(...).exclude(...).get()
create(**kwargs)
在一步操作中同时创建并且保存对象的便捷方法:
p = Person.objects.create(first_name="Bruce", last_name="Springsteen")
等于:
p = Person(first_name="Bruce", last_name="Springsteen") p.save(force_insert=True)
参数force_insert表示强制创建对象。如果model中有一个你手动设置的主键,并且这个值已经存在了数据库中,调用create()将会失败,并且触发IntegrityError因为主键必须是唯一的。如果你手动设置了主键,做好异常处理的准备。
get_or_create(defaults=None, **kwargs)
通过kwargs来查询对象的便捷方法(如果模型中的所有字段都有默认值,可以为空),如果该对象不存在则创建一个新对象。
该方法返回一个由(object,created)组成的元组,元组中的object是一个查询到的或者是被创建的对象,created是一个表示是否创建了新的对象的布尔值。
对于下面的代码:
try:
obj = Person.objects.get(first_name=‘John‘, last_name=‘Lennon‘)
except Person.DoesNotExist:
obj = Person(first_name=‘John‘, last_name=‘Lennon‘, birthday=date(1940, 10, 9))
obj.save()
如果模型的字段数量较大的话,这种模式就变的非常不易使用了。上面的示例可以用get_or_create()重写:
obj, created = Person.objects.get_or_create(
first_name=‘John‘,
last_name=‘Lennon‘,
defaults={‘birthday‘: date(1940, 10, 9)},
)
任何传递给get_or_create()的关键字参数,除了一个可选的defaults,都将传递给get()调用,如果查到一个对象,返回一个包含匹配到的对象以及False组成的元组。如果查到的对象超过一个以上,将引发MultipleObjectsReturned。如果查找不到对象,get_or_create() 将会实例化并保存一个新的对象,返回一个由新的对象以及True组成的元组。新的对象将会按照以下的逻辑创建:
params = {k: v for k, v in kwargs.items() if ‘__‘ not in k}
params.update({k: v() if callable(v) else v for k, v in defaults.items()})
obj = self.model(**params)
obj.save()
它表示从非‘defaults‘ 且不包含双下划线的关键字参数开始。然后将defaults的内容添加进来,覆盖必要的键,并使用结果作为关键字参数传递给模型类。
如果有一个名为defaults_exact 的字段,并且想在 get_or_create() 时用它作为精确查询,只需要使用defaults,像这样:
Foo.objects.get_or_create(defaults__exact=‘bar‘, defaults={‘defaults‘: ‘baz‘})
当你使用手动指定的主键时,get_or_create()方法与create()方法有相似的错误行为。如果需要创建一个对象而该对象的主键早已存在于数据库中,IntergrityError异常将会被触发。
这个方法假设进行的是原子操作,并且正确地配置了数据库和正确的底层数据库行为。如果数据库级别没有对get_or_create中用到的kwargs强制要求唯一性(unique和unique_together),方法容易导致竞态条件,可能会有相同参数的多行同时插入。(简单理解,kwargs必须指定的是主键或者unique属性的字段才安全。)
最后建议只在Django视图的POST请求中使用get_or_create(),因为这是一个具有修改性质的动作,不应该使用在GET请求中,那样不安全。
可以通过ManyToManyField属性和反向关联使用get_or_create()。在这种情况下,应该限制查询在关联的上下文内部。 否则,可能导致完整性问题。
例如下面的模型:
class Chapter(models.Model):
title = models.CharField(max_length=255, unique=True)
class Book(models.Model):
title = models.CharField(max_length=256)
chapters = models.ManyToManyField(Chapter)
可以通过Book的chapters字段使用get_or_create(),但是它只会获取该Book内部的上下文:
>>> book = Book.objects.create(title="Ulysses") >>> book.chapters.get_or_create(title="Telemachus") (<Chapter: Telemachus>, True) >>> book.chapters.get_or_create(title="Telemachus") (<Chapter: Telemachus>, False) >>> Chapter.objects.create(title="Chapter 1") <Chapter: Chapter 1> >>> book.chapters.get_or_create(title="Chapter 1") # Raises IntegrityError
发生这个错误是因为尝试通过Book “Ulysses”获取或者创建“Chapter 1”,但是它不能,因为它与这个book不关联,但因为title 字段是唯一的它仍然不能创建。
在Django1.11在defaults中增加了对可调用值的支持。
update_or_create(defaults=None, **kwargs)
类似于上面的 get_or_create()
通过给出的kwargs来更新对象的便捷方法, 如果没找到对象,则创建一个新的对象。defaults是一个由 (field, value)对组成的字典,用于更新对象。defaults中的值可以是可调用对象(也就是说函数等)。
该方法返回一个由(object, created)组成的元组,元组中的object是一个创建的或者是被更新的对象, created是一个标示是否创建了新的对象的布尔值。
update_or_create方法尝试通过给出的kwargs 去从数据库中获取匹配的对象。 如果找到匹配的对象,它将会依据defaults 字典给出的值更新字段。
像下面的代码:
defaults = {‘first_name‘: ‘Bob‘}
try:
obj = Person.objects.get(first_name=‘John‘, last_name=‘Lennon‘)
for key, value in defaults.items():
setattr(obj, key, value)
obj.save()
except Person.DoesNotExist:
new_values = {‘first_name‘: ‘John‘, ‘last_name‘: ‘Lennon‘}
new_values.update(defaults)
obj = Person(**new_values)
obj.save()
如果模型的字段数量较大的话,这种模式就变的非常不易用了。上面的示例可以用update_or_create()重写:
obj, created = Person.objects.update_or_create(
first_name=‘John‘, last_name=‘Lennon‘,
defaults={‘first_name‘: ‘Bob‘},
)
和get_or_create()一样,这个方法也容易导致竞态条件,如果数据库层级没有前置唯一性会让多行同时插入。
在Django1.11在defaults中增加了对可调用值的支持。
bulk_create(objs , batch_size = None)
以高效的方式(通常只有一个查询,无论有多少对象)将提供的对象列表插入到数据库中:
>>> Entry.objects.bulk_create([ ... Entry(headline=‘This is a test‘), ... Entry(headline=‘This is only a test‘), ... ])
注意事项:
pre_save和post_save信号。batch_size参数控制在单个查询中创建的对象数。
count()
返回在数据库中对应的QuerySet对象的个数,count()永远不会引发异常。
例如:
# 返回总个数. Entry.objects.count() # 返回包含有‘Lennon‘的对象的总数 Entry.objects.filter(headline__contains=‘Lennon‘).count()
in_bulk(id_list = None)
获取主键值的列表,并返回将每个主键值映射到具有给定ID的对象的实例的字典。 如果未提供列表,则会返回查询集中的所有对象。
例如:
>>> Blog.objects.in_bulk([1])
{1: <Blog: Beatles Blog>}
>>> Blog.objects.in_bulk([1, 2])
{1: <Blog: Beatles Blog>, 2: <Blog: Cheddar Talk>}
>>> Blog.objects.in_bulk([])
{}
>>> Blog.objects.in_bulk()
{1: <Blog: Beatles Blog>, 2: <Blog: Cheddar Talk>, 3: <Blog: Django Weblog>}
如果向in_bulk()传递一个空列表,会得到一个空的字典。
在旧版本中,id_list是必须的参数,现在是一个可选参数。
iterator()
提交数据库操作,获取QuerySet,并返回一个迭代器。
Q uerySet通常会在内部缓存其结果,以便在重复计算时不会导致额外的查询。而iterator()将直接读取结果,不在QuerySet级别执行任何缓存。对于返回大量只需要访问一次的对象的QuerySet,这可以带来更好的性能,显著减少内存使用。
请注意,在已经提交了的iterator()上使用QuerySet会强制它再次提交数据库操作,进行重复查询。此外,使用iterator()会导致先前的prefetch_related()调用被忽略,因为这两个一起优化没有意义。
latest(field_name=None)
使用日期字段field_name,按日期返回最新对象。
下例根据Entry的‘pub_date‘字段返回最新发布的entry:
Entry.objects.latest(‘pub_date‘)
如果模型的Meta指定了get_latest_by,则可以将latest()参数留给earliest()或者field_name。 默认情况下,Django将使用get_latest_by中指定的字段。
earliest()和latest()可能会返回空日期的实例,可能需要过滤掉空值:
Entry.objects.filter(pub_date__isnull=False).latest(‘pub_date‘)
earliest(field_name = None)
类同latest()
first()
返回结果集的第一个对象,当没有找到时候,返回None,如果QuerySet没有设置排序,则将自动按主键进行排序。例如:
p = Article.objects.order_by(‘title‘, ‘pub_date‘).first()
first()是一个简便方法,下面的例子和上面的代码效果是一样:
try:
p = Article.objects.order_by(‘title‘, ‘pub_date‘)[0]
except IndexError:
p = None
last()
工作方式类似于first() ,只是返回的是查询集中最后一个对象。
aggregate(*args, **kwargs)
返回汇总值的字典(平均值,总和等),通过QuerySet进行计算。每个参数指定返回的字典中将要包含的值。
使用关键字参数指定的聚合将使用关键字参数的名称作为Annotation 的名称。 匿名参数的名称将基于聚合函数的名称和模型字段生成。 复杂的聚合不可以使用匿名参数,必须指定一个关键字参数作为别名。
例如,想知道Blog Entry 的数目:
>>> from django.db.models import Count
>>> q = Blog.objects.aggregate(Count(‘entry‘))
{‘entry__count‘: 16}
通过使用关键字参数来指定聚合函数,可以控制返回的聚合的值的名称:
>>> q = Blog.objects.aggregate(number_of_entries=Count(‘entry‘))
{‘number_of_entries‘: 16}
exists()
如果QuerySet包含任何结果,则返回True,否则返回False。
查找具有唯一性字段(例如primary_key)的模型是否在一个QuerySet中的最高效的方法是:
entry = Entry.objects.get(pk=123)
if some_queryset.filter(pk=entry.pk).exists():
print("Entry contained in queryset")
它将比下面的方法快很多,这个方法要求对QuerySet求值并迭代整个QuerySet:
if entry in some_queryset:
print("Entry contained in QuerySet")
若要查找一个QuerySet是否包含任何元素:
if some_queryset.exists():
print("There is at least one object in some_queryset")
将快于:
if some_queryset:
print("There is at least one object in some_queryset")
update(**kwargs)
对指定的字段执行批量更新操作,并返回匹配的行数(如果某些行已具有新值,则可能不等于已更新的行数)。
例如,要对2010年发布的所有博客条目启用评论,可以执行以下操作:
>>> Entry.objects.filter(pub_date__year=2010).update(comments_on=False)
可以同时更新多个字段 (没有多少字段的限制)。 例如同时更新comments_on和headline字段:
>> Entry.objects.filter(pub_date__year=2010).update(comments_on=False, headline=‘This is old‘)
update()方法无需save操作。唯一限制是它只能更新模型主表中的列,而不是关联的模型,例如不能这样做:
>>> Entry.objects.update(blog__name=‘foo‘) # Won‘t work!
仍然可以根据相关字段进行过滤:
>>> Entry.objects.filter(blog__id=1).update(comments_on=True)
update()方法返回受影响的行数:
>>> Entry.objects.filter(id=64).update(comments_on=True) 1 >>> Entry.objects.filter(slug=‘nonexistent-slug‘).update(comments_on=True) 0 >>> Entry.objects.filter(pub_date__year=2010).update(comments_on=False) 132
如果你只是更新一下对象,不需要为对象做别的事情,最有效的方法是调用update(),而不是将模型对象加载到内存中。 例如,不要这样做:
e = Entry.objects.get(id=10) e.comments_on = False e.save()
建议如下操作:
Entry.objects.filter(id=10).update(comments_on=False)
用update()还可以防止在加载对象和调用save()之间的短时间内数据库中某些内容可能发生更改的竞争条件。
如果想更新一个具有自定义save()方法的模型的记录,请循环遍历它们并调用save(),如下所示:
for e in Entry.objects.filter(pub_date__year=2010):
e.comments_on = False
e.save()
delete()
批量删除QuerySet中的所有对象,并返回删除的对象个数和每个对象类型的删除次数的字典。
elete()动作是立即执行的。
不能在QuerySet上调用delete()。
例如,要删除特定博客中的所有条目:
>>> b = Blog.objects.get(pk=1)
# Delete all the entries belonging to this Blog.
>>> Entry.objects.filter(blog=b).delete()
(4, {‘weblog.Entry‘: 2, ‘weblog.Entry_authors‘: 2})
默认情况下,Django的ForeignKey使用SQL约束ON DELETE CASCADE,任何具有指向要删除的对象的外键的对象将与它们一起被删除。 像这样:
>>> blogs = Blog.objects.all()
# This will delete all Blogs and all of their Entry objects.
>>> blogs.delete()
(5, {‘weblog.Blog‘: 1, ‘weblog.Entry‘: 2, ‘weblog.Entry_authors‘: 2})
这种级联的行为可以通过的ForeignKey的on_delete参数自定义。(什么时候要改变这种行为呢?比如日志数据,就不能和它关联的主体一并被删除!)
delete()会为所有已删除的对象(包括级联删除)发出pre_delete和post_delete信号。
classmethod as_manager()
一个类方法,返回Manager的实例与QuerySet的方法的副本。
详情参考django官方文档:https://django-chinese-docs-14.readthedocs.io/en/latest/ref/models/options.html
https://www.cnblogs.com/yuanchenqi/articles/8876856.html
https://www.cnblogs.com/feixuelove1009/p/8425054.html
(这里主要是做了自己的学习笔记,用来记录于此)
Django学习笔记(13)——Django的用户认证组件,视图层和QuerySet API
原文:https://www.cnblogs.com/wj-1314/p/10065929.html