Interspeech 2014 Learning Small-Size DNN with Output-Distribution-Based Criteria
简述
为了减小离线模型(比如用于嵌入式设备)的大小,可以减小每个隐层的节点数或者减小输出层的目标节点数。
减小每个隐层的节点数
教师模型(L)与学生模型(S)之间的KL散度为:
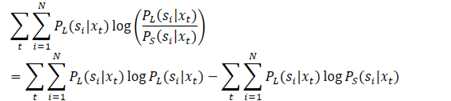
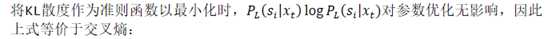
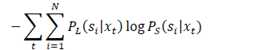
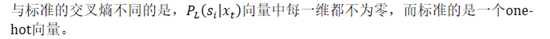
训练流程为:
? ?
与直接重训相比,上述TS训练方法在375小时数据集上取得13.59%的WER下降
减小输出层的目标节点数
传统生成三音素集方法的问题在于
? ?
本文提出先用标准方法生成较大的三音素集,然后基于DNN相关的特征对大三音素集进行聚类。
? ?
根据Equivalence of generative and log-linear models,对数线性模型等价于一个高斯模型:
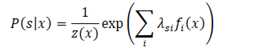
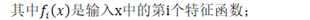
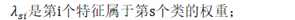

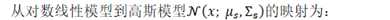
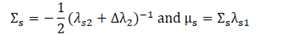
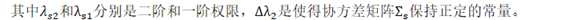
? ?
softmax函数可以看作是以下对数线性函数:
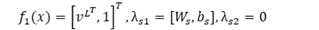

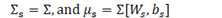
? ?
训练流程为:
实验结果与结论
与使用标准流程用决策树重新生成三音素集相比,基于高斯KL聚类的方法在375小时能取得1.33%的WER下降
原文
Li, Jinyu, Rui Zhao, Jui-Ting Huang, and Yifan Gong. "Learning small-size DNN with output-distribution-based criteria." In?Fifteenth annual conference of the international speech communication association. 2014.
原文:https://www.cnblogs.com/JarvanWang/p/10950546.html