常见的字体反爬就是用css自定义字体来替换网页中的关键数据,使爬虫无法正常解析。这里以58同城为例:
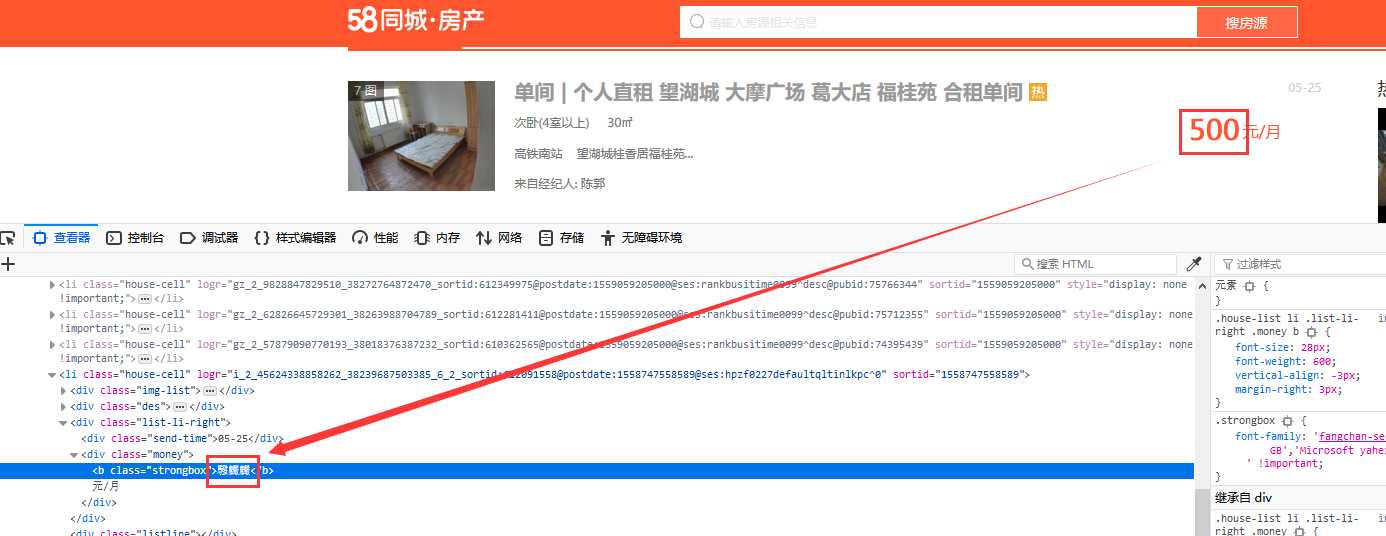
既然是字体替换,那么前端就一定要加载相关的字体文件。因此,在网页中的head标签下,我们可以找到一段base64加密的字符串:
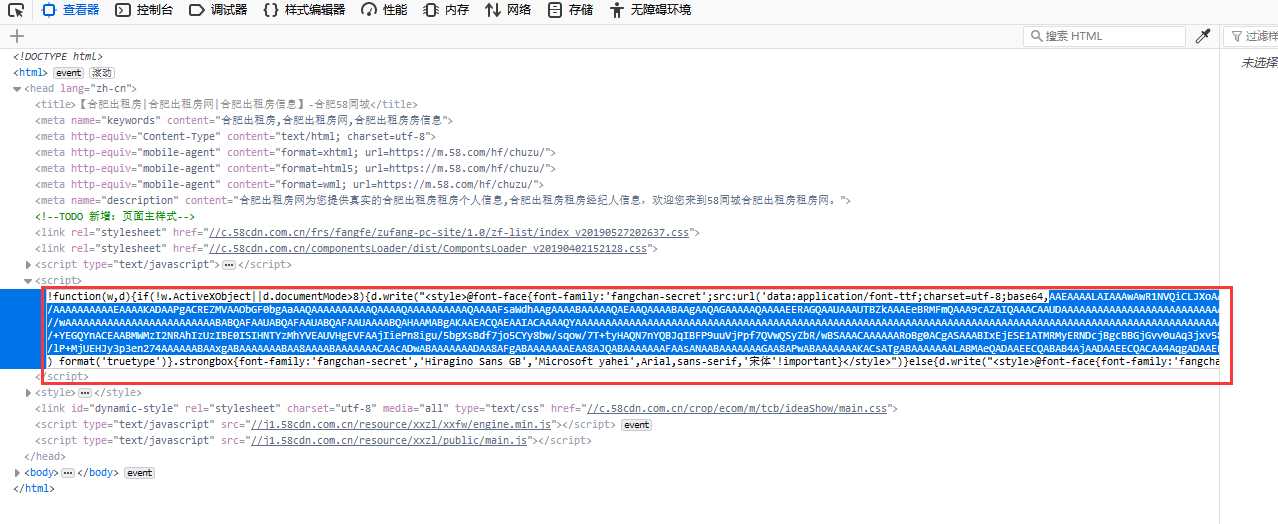
这段字符可以转化为一个ttf文件:
import base64
font_face='AAEAAAALAIAAAwAwR1NVQiCLJXoAAAE4AAAAVE9TLzL4XQjtAAABjAAAAFZjbWFwq8B/ZwAAAhAAAAIuZ2x5ZuWIN0cAAARYAAADdGhlYWQTmDvfAAAA4AAAADZoaGVhCtADIwAAALwAAAAkaG10eC7qAAAAAAHkAAAALGxvY2ED7gSyAAAEQAAAABhtYXhwARgANgAAARgAAAAgbmFtZTd6VP8AAAfMAAACanBvc3QFRAYqAAAKOAAAAEUAAQAABmb+ZgAABLEAAAAABGgAAQAAAAAAAAAAAAAAAAAAAAsAAQAAAAEAAOu1IchfDzz1AAsIAAAAAADYCHhnAAAAANgIeGcAAP/mBGgGLgAAAAgAAgAAAAAAAAABAAAACwAqAAMAAAAAAAIAAAAKAAoAAAD/AAAAAAAAAAEAAAAKADAAPgACREZMVAAObGF0bgAaAAQAAAAAAAAAAQAAAAQAAAAAAAAAAQAAAAFsaWdhAAgAAAABAAAAAQAEAAQAAAABAAgAAQAGAAAAAQAAAAEERAGQAAUAAAUTBZkAAAEeBRMFmQAAA9cAZAIQAAACAAUDAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFBmRWQAQJR2n6UGZv5mALgGZgGaAAAAAQAAAAAAAAAAAAAEsQAABLEAAASxAAAEsQAABLEAAASxAAAEsQAABLEAAASxAAAEsQAAAAAABQAAAAMAAAAsAAAABAAAAaYAAQAAAAAAoAADAAEAAAAsAAMACgAAAaYABAB0AAAAFAAQAAMABJR2lY+ZPJpLnjqeo59kn5Kfpf//AACUdpWPmTyaS546nqOfZJ+Sn6T//wAAAAAAAAAAAAAAAAAAAAAAAAABABQAFAAUABQAFAAUABQAFAAUAAAABgAIAAEABQAKAAIABwADAAQACQAAAQYAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADAAAAAAAiAAAAAAAAAAKAACUdgAAlHYAAAAGAACVjwAAlY8AAAAIAACZPAAAmTwAAAABAACaSwAAmksAAAAFAACeOgAAnjoAAAAKAACeowAAnqMAAAACAACfZAAAn2QAAAAHAACfkgAAn5IAAAADAACfpAAAn6QAAAAEAACfpQAAn6UAAAAJAAAAAAAAACgAPgBmAJoAvgDoASQBOAF+AboAAgAA/+YEWQYnAAoAEgAAExAAISAREAAjIgATECEgERAhIFsBEAECAez+6/rs/v3IATkBNP7S/sEC6AGaAaX85v54/mEBigGB/ZcCcwKJAAABAAAAAAQ1Bi4ACQAAKQE1IREFNSURIQQ1/IgBW/6cAicBWqkEmGe0oPp7AAEAAAAABCYGJwAXAAApATUBPgE1NCYjIgc1NjMyFhUUAgcBFSEEGPxSAcK6fpSMz7y389Hym9j+nwLGqgHButl0hI2wx43iv5D+69b+pwQAAQAA/+YEGQYnACEAABMWMzI2NRAhIzUzIBE0ISIHNTYzMhYVEAUVHgEVFAAjIiePn8igu/5bgXsBdf7jo5CYy8bw/sqow/7T+tyHAQN7nYQBJqIBFP9uuVjPpf7QVwQSyZbR/wBSAAACAAAAAARoBg0ACgASAAABIxEjESE1ATMRMyERNDcjBgcBBGjGvv0uAq3jxv58BAQOLf4zAZL+bgGSfwP8/CACiUVaJlH9TwABAAD/5gQhBg0AGAAANxYzMjYQJiMiBxEhFSERNjMyBBUUACEiJ7GcqaDEx71bmgL6/bxXLPUBEv7a/v3Zbu5mswEppA4DE63+SgX42uH+6kAAAAACAAD/5gRbBicAFgAiAAABJiMiAgMzNjMyEhUUACMiABEQACEyFwEUFjMyNjU0JiMiBgP6eYTJ9AIFbvHJ8P7r1+z+8wFhASClXv1Qo4eAoJeLhKQFRj7+ov7R1f762eP+3AFxAVMBmgHjLfwBmdq8lKCytAAAAAABAAAAAARNBg0ABgAACQEjASE1IQRN/aLLAkD8+gPvBcn6NwVgrQAAAwAA/+YESgYnABUAHwApAAABJDU0JDMyFhUQBRUEERQEIyIkNRAlATQmIyIGFRQXNgEEFRQWMzI2NTQBtv7rAQTKufD+3wFT/un6zf7+AUwBnIJvaJLz+P78/uGoh4OkAy+B9avXyqD+/osEev7aweXitAEohwF7aHh9YcJlZ/7qdNhwkI9r4QAAAAACAAD/5gRGBicAFwAjAAA3FjMyEhEGJwYjIgA1NAAzMgAREAAhIicTFBYzMjY1NCYjIga5gJTQ5QICZvHD/wABGN/nAQT+sP7Xo3FxoI16pqWHfaTSSgFIAS4CAsIBDNbkASX+lf6l/lP+MjUEHJy3p3en274AAAAAABAAxgABAAAAAAABAA8AAAABAAAAAAACAAcADwABAAAAAAADAA8AFgABAAAAAAAEAA8AJQABAAAAAAAFAAsANAABAAAAAAAGAA8APwABAAAAAAAKACsATgABAAAAAAALABMAeQADAAEECQABAB4AjAADAAEECQACAA4AqgADAAEECQADAB4AuAADAAEECQAEAB4A1gADAAEECQAFABYA9AADAAEECQAGAB4BCgADAAEECQAKAFYBKAADAAEECQALACYBfmZhbmdjaGFuLXNlY3JldFJlZ3VsYXJmYW5nY2hhbi1zZWNyZXRmYW5nY2hhbi1zZWNyZXRWZXJzaW9uIDEuMGZhbmdjaGFuLXNlY3JldEdlbmVyYXRlZCBieSBzdmcydHRmIGZyb20gRm9udGVsbG8gcHJvamVjdC5odHRwOi8vZm9udGVsbG8uY29tAGYAYQBuAGcAYwBoAGEAbgAtAHMAZQBjAHIAZQB0AFIAZQBnAHUAbABhAHIAZgBhAG4AZwBjAGgAYQBuAC0AcwBlAGMAcgBlAHQAZgBhAG4AZwBjAGgAYQBuAC0AcwBlAGMAcgBlAHQAVgBlAHIAcwBpAG8AbgAgADEALgAwAGYAYQBuAGcAYwBoAGEAbgAtAHMAZQBjAHIAZQB0AEcAZQBuAGUAcgBhAHQAZQBkACAAYgB5ACAAcwB2AGcAMgB0AHQAZgAgAGYAcgBvAG0AIABGAG8AbgB0AGUAbABsAG8AIABwAHIAbwBqAGUAYwB0AC4AaAB0AHQAcAA6AC8ALwBmAG8AbgB0AGUAbABsAG8ALgBjAG8AbQAAAAIAAAAAAAAAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACwECAQMBBAEFAQYBBwEIAQkBCgELAQwAAAAAAAAAAAAAAAAAAAAA'
b = base64.b64decode(font_face)
with open('58.ttf','wb') as f:
f.write(b)用FontCreator打开这个ttf文件,我们可以看到:
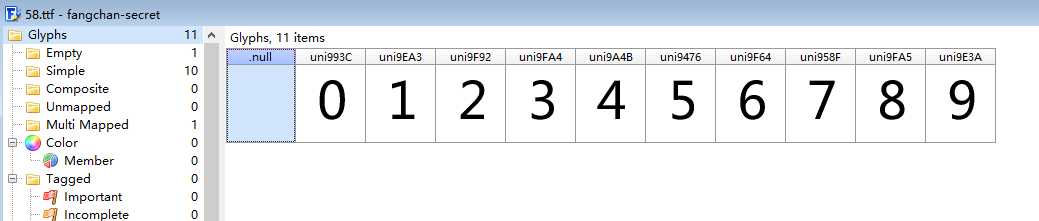
由于字符与字体间的映射关系在每次请求中都是不一样的,所以破解字体反爬的关键就是自动化地识别出字符与数据间的准确映射关系。
接下来,我们用fonttools工具库把ttf文件解析出来,转换成xml:
from fontTools.ttLib import TTFont
font = TTFont('58.ttf')
font.saveXML('58.xml')在xml文件中我们可以得到该字体相关的所有信息,包括id(GlyphOrder标签下),笔划/字形(glyf标签下)等等:
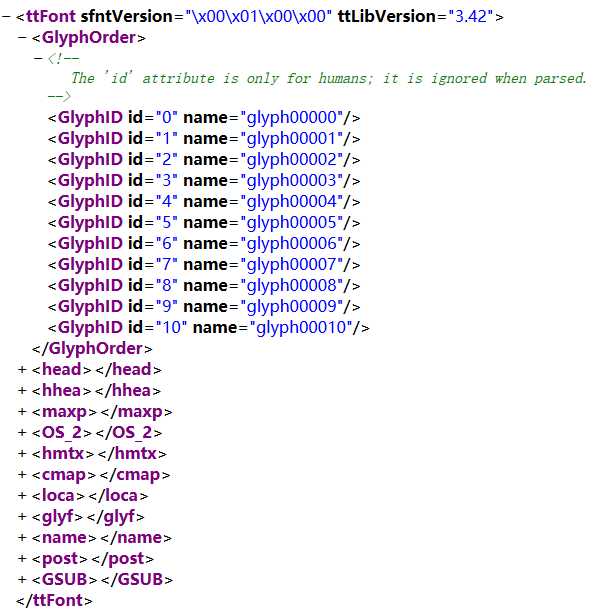
在camp标签下,我们可以看到字符和字体id间的对应关系:

结合fontCreator,我们可以观察到“字符”,“id”及“数字含义”间存在的对应关系:
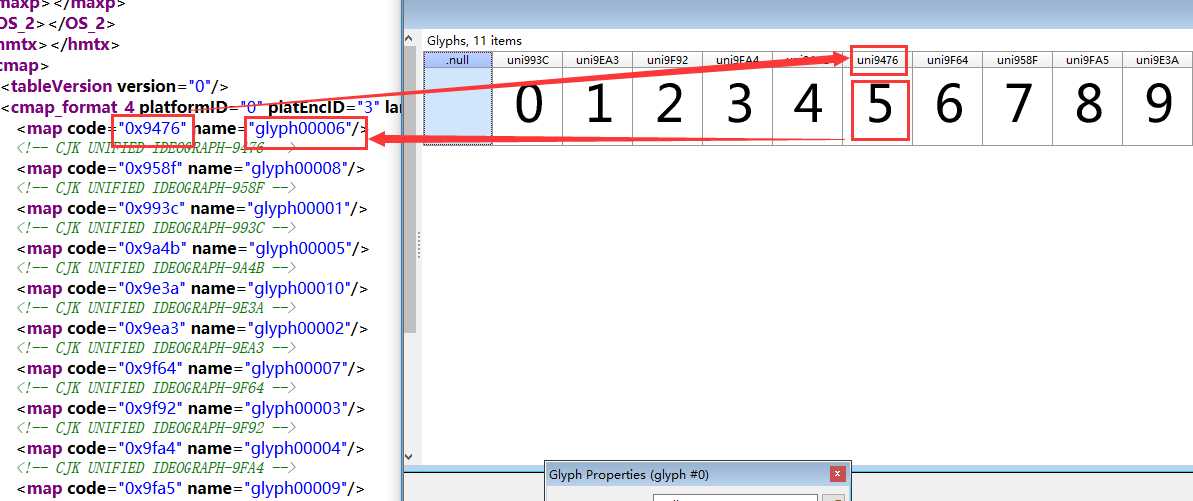
找到规律后,我们就能编写自动化解析的代码了:
import re
import base64
import io
from fontTools.ttLib import TTFont
base64_str = font_face # 提取前端中的字体加密字符串
b = base64.b64decode(base64_str) # base64解码
font = TTFont(io.BytesIO(b)) # 读取ttf数据
bestcmap = font['cmap'].getBestCmap() # 得到camp标签下的数据
"""
bestcmap: {38006: 'glyph00006', 38287: 'glyph00008', 39228: 'glyph00001', 39499: 'glyph00005', 40506: 'glyph00010', 40611: 'glyph00002', 40804: 'glyph00007', 40850: 'glyph00003', 40868: 'glyph00004', 40869: 'glyph00009'}
"""
newmap = dict()
for key in bestcmap.keys():
value = int(re.search(r'(\d+)', bestcmap[key]).group(1)) - 1 # 根据我们前面发现的规律:把标签中的数字减一,就是最后网页上显示的数字
key = hex(key) # 注意网页中的字符串是16进制的,所以这里要做一个转换
newmap[key] = value # 得到字符与数据间的真实映射关系
# 把页面上自定义字体替换成正常字体,这一步就很简单了
response_ = response.text
for key,value in newmap.items():
key_ = key.replace('0x','&#x') + ';'
if key_ in response_:
response_ = response_.replace(key_,str(value))原文:https://www.cnblogs.com/lokvahkoor/p/10953506.html