public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
/** * The default initial capacity - MUST be a power of two. */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/** * The next size value at which to resize (capacity * load factor). * @serial */ // If table == EMPTY_TABLE then this is the initial capacity at which the // table will be created when inflated. int threshold;
/** * The load factor used when none specified in constructor. */ static final float DEFAULT_LOAD_FACTOR = 0.75f;
/** * The number of key-value mappings contained in this map. */ transient int size;
transient int modCount;
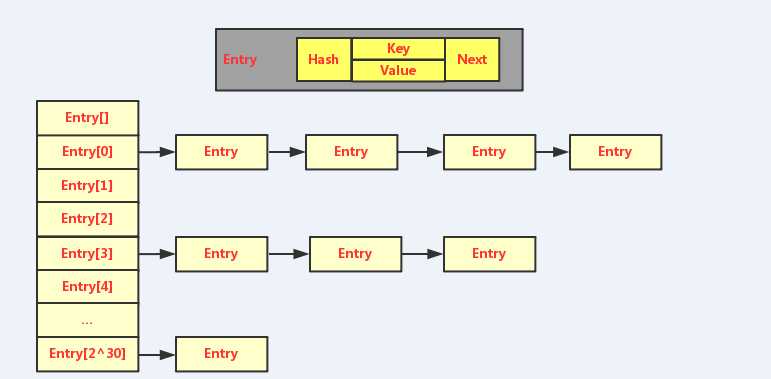
static final Entry<?,?>[] EMPTY_TABLE = {}; /** * The table, resized as necessary. Length MUST Always be a power of two. * 这里也强调扩容时,长度必须是2的指数次幂 */ transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash; }
public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; threshold = initialCapacity; // 供子类实现 init(); }
public V put(K key, V value) { // 1 如果table为空则需要初始化 if (table == EMPTY_TABLE) { inflateTable(threshold); } // 2 如果key为空,则单独处理 if (key == null) return putForNullKey(value); // 3 根据key获取hash值 int hash = hash(key); // 4 根据hash值和长度求取索引值。 int i = indexFor(hash, table.length); // 5 根据索引值获取数组下的链表进行遍历,判断元素是否存在相同的key for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { // 如果相等,则将新值替换旧值 V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } // 6 如果不存在重复的key, 则需要创建新的Entry,然后添加至链表中。 // 先将修改次数加一 modCount++; addEntry(hash, key, value, i); return null; }
private void inflateTable(int toSize) { // Find a power of 2 >= toSize int capacity = roundUpToPowerOf2(toSize); // 其中阈值=容量*加载因子,然后再初始化数组。 threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); table = new Entry[capacity]; initHashSeedAsNeeded(capacity); }
private static int roundUpToPowerOf2(int number) { // assert number >= 0 : "number must be non-negative"; return number >= MAXIMUM_CAPACITY ? MAXIMUM_CAPACITY : (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1; }
private V putForNullKey(V value) { // 取数组下标为0的链表 for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; // 注意:索引值依然指定是0 addEntry(0, null, value, 0); return null; }
final int hash(Object k) { int h = hashSeed; if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); } h ^= k.hashCode(); // This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }
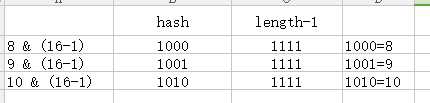
static int indexFor(int h, int length) { // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; return h & (length-1); }
void addEntry(int hash, K key, V value, int bucketIndex) { // 如果长度大于阈值,则需要进行扩容 if ((size >= threshold) && (null != table[bucketIndex])) { // 进行2倍扩容 resize(2 * table.length); hash = (null != key) ? hash(key) : 0; // 扩容之后因为长度变化了,需要重新计算下索引值。 bucketIndex = indexFor(hash, table.length); } // 然后进行添加元素 createEntry(hash, key, value, bucketIndex); } void createEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; // 往表头插入 table[bucketIndex] = new Entry<>(hash, key, value, e); size++; }
void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; // 两倍容量与最大容量取最小 if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } // 创建新数组 Entry[] newTable = new Entry[newCapacity]; // 拷贝数组(重新计算索引下标) transfer(newTable, initHashSeedAsNeeded(newCapacity)); table = newTable; // 重新计算阈值 threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); }
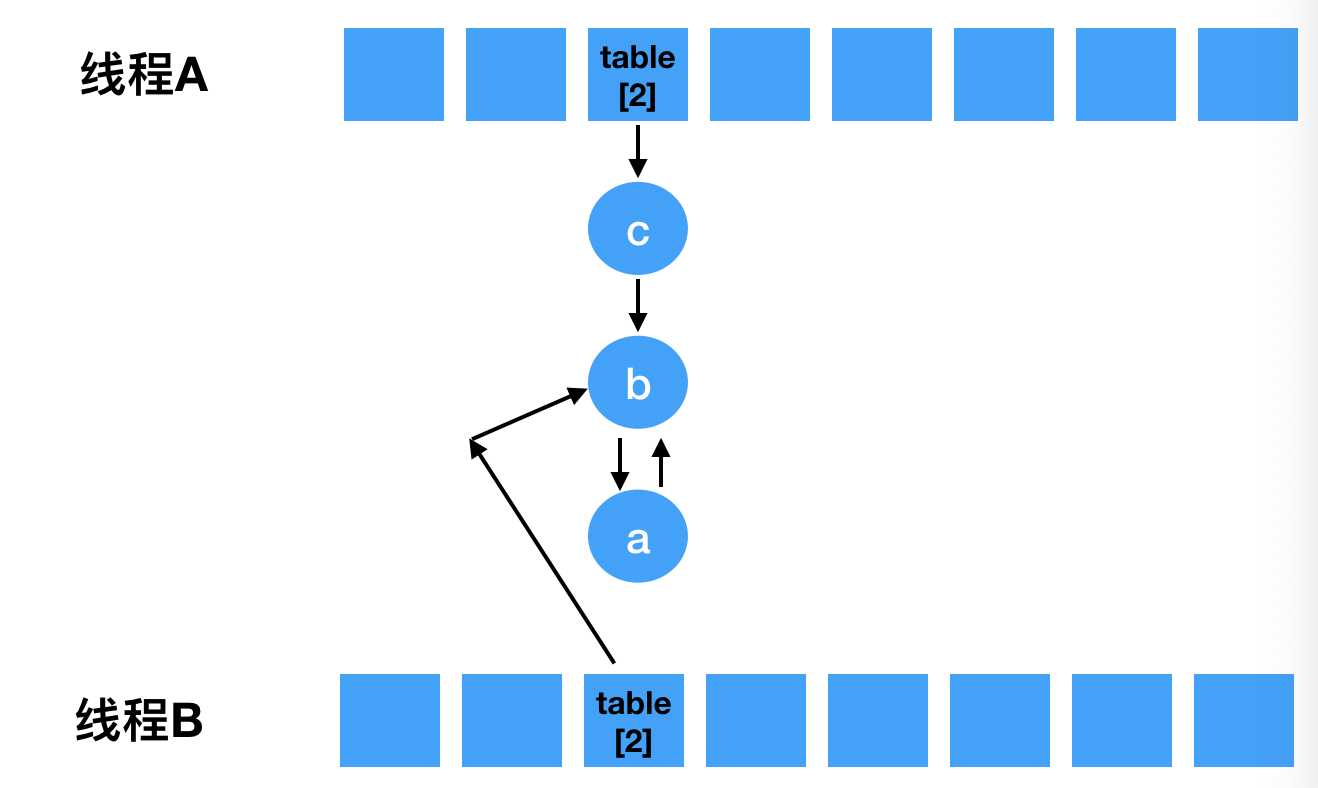
void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; for (Entry<K,V> e : table) { while(null != e) { // 定一个next Entry<K,V> next = e.next; if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } // 重新计算索引下标。 int i = indexFor(e.hash, newCapacity); // 头插法, e.next = newTable[i]; newTable[i] = e; // 接着下个节点继续遍历 e = next; } } }
通过上面分析,其实put函数还是简单的,不是很绕。那么能从其中找到开头的第二和第三个问题的答案吗?下面总结下顺便回答下这两个问题:
public V get(Object key) { if (key == null) return getForNullKey(); Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); }
第一步:如果key为空,则直接从table[0]所对应的链表中查找(应该还记得put的时候为null的key放在哪)。
private V getForNullKey() { if (size == 0) { return null; } for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) return e.value; } return null; }
final Entry<K,V> getEntry(Object key) { if (size == 0) { return null; } int hash = (key == null) ? 0 : hash(key); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }
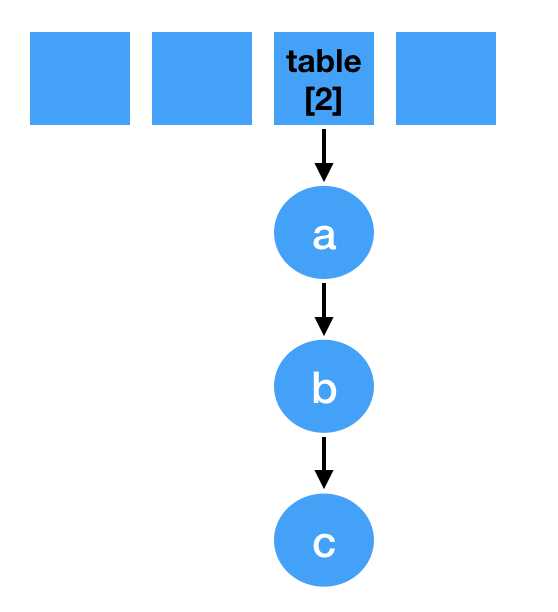
Entry<K,V> next = e.next;
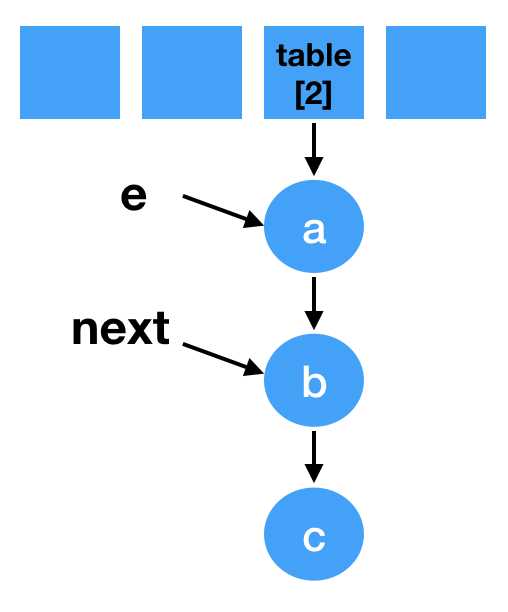
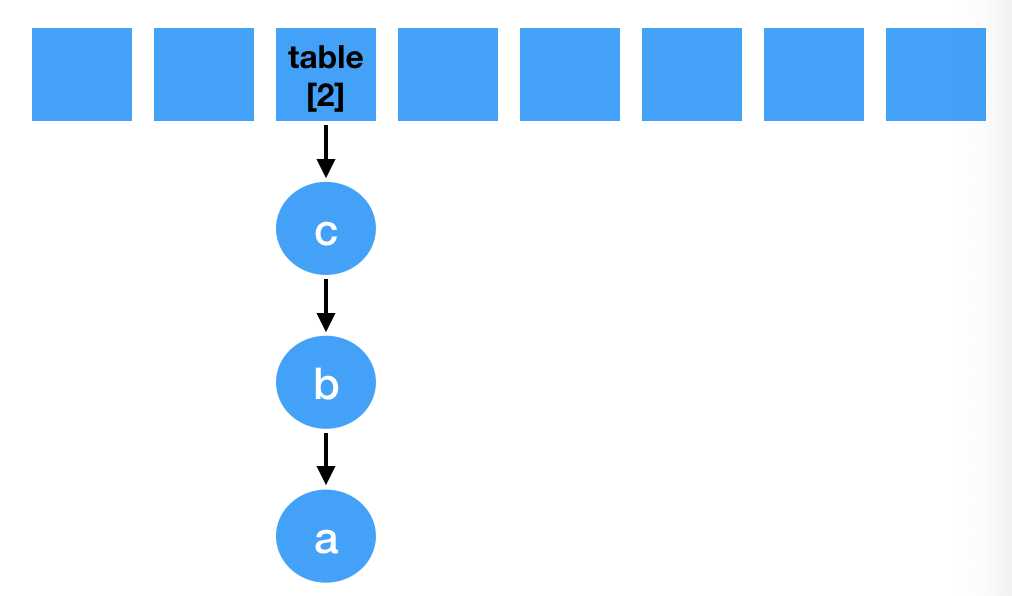
// 同理落位到2 int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; // 指向a newTable[i] = e; e = next;
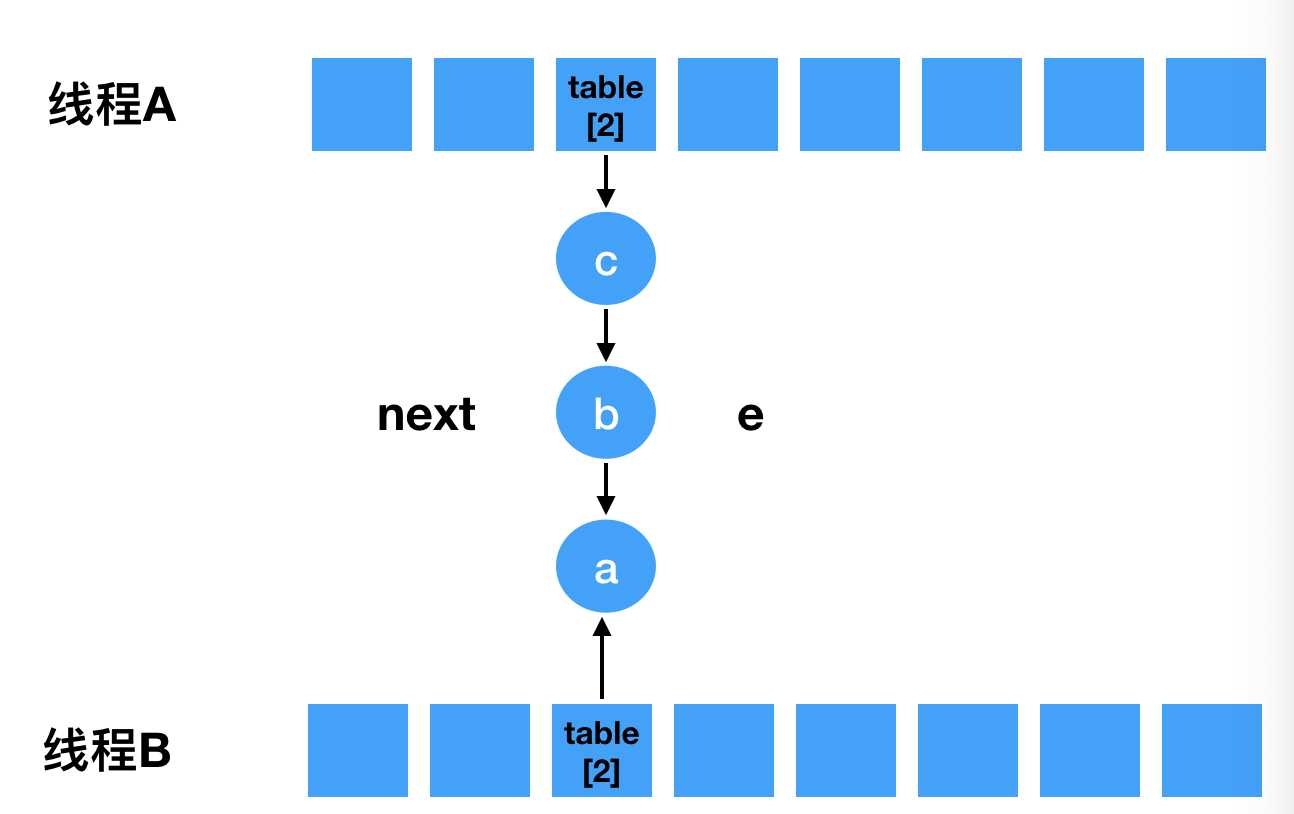
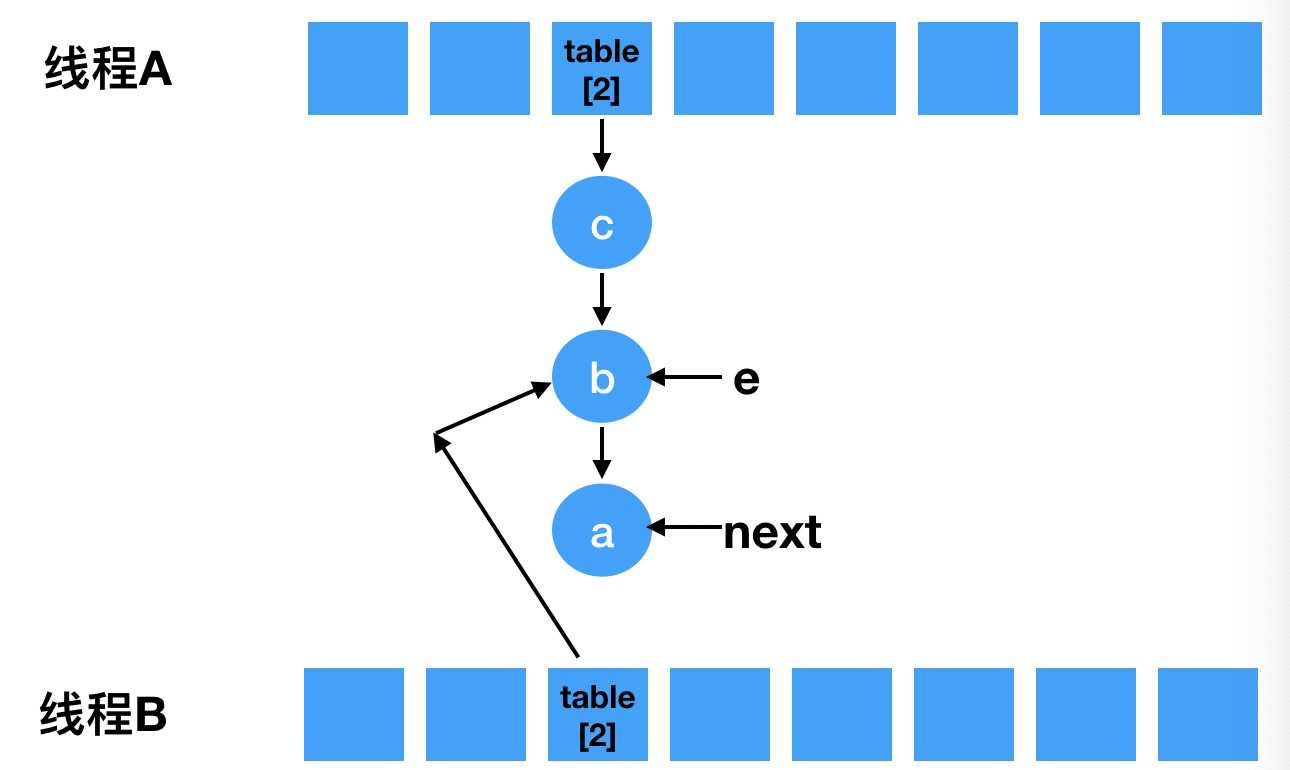
e.next = newTable[i];
原文:https://www.cnblogs.com/yuanfy008/p/10958041.html