搭建redis 主从 (可以用一台主机,也可以两台主机)
环境准备:
一台服务器:192.168.206.6
操作系统:CentOS7.5
redis 版本: redis-5.0.0
开始部署:
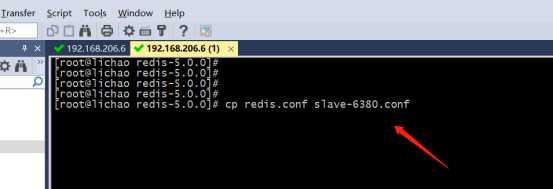
1>拷贝一份配置文件(作为从配置文件)
cp redis.conf slave-6380.conf
2>编辑从配置文件
# bind 从节点ip
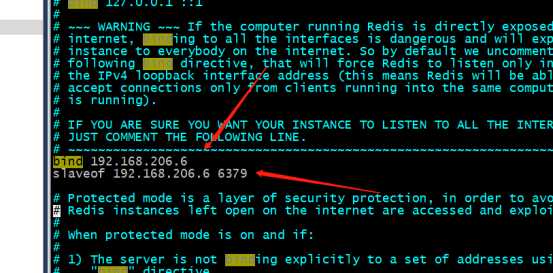
slaveof :( 谁的从) 写主的ip
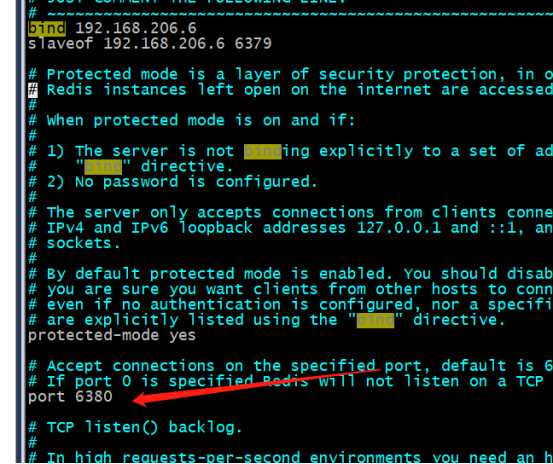
注:因为我这是在一台物理机上所有修改一个端口, 如果是两台物理机可以不做修改
3>启动配置文件使其生效
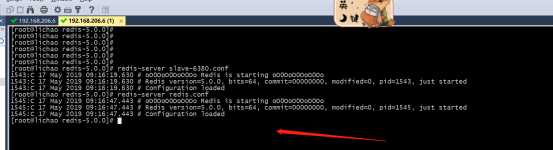
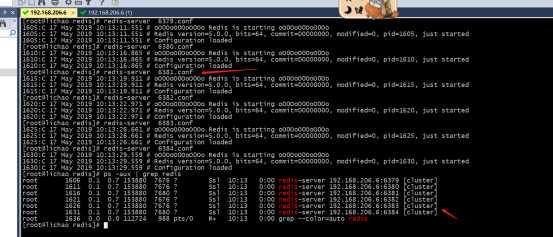
4>查看进程
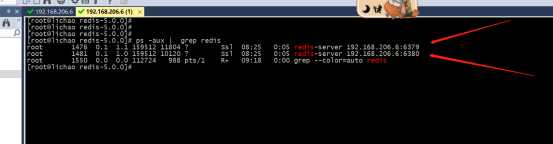
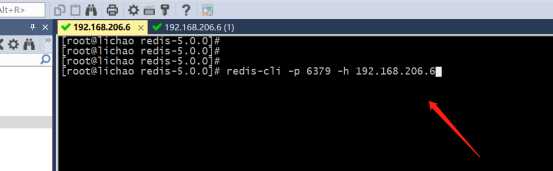
5>连接测试
#1主:
#2从
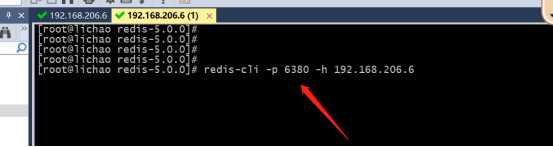
&测试

&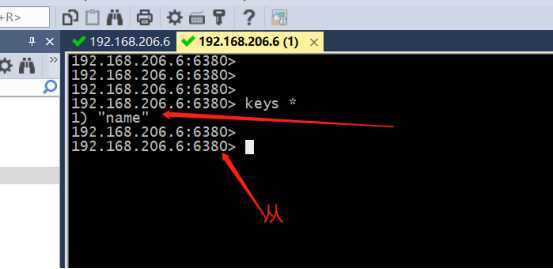
同步成功
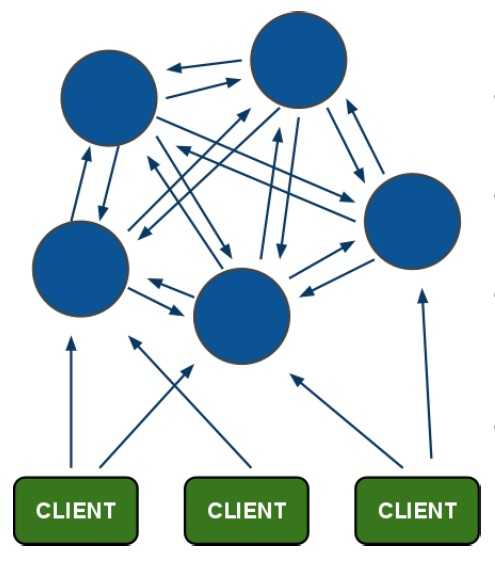
工作原理:
集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key 分到哈希槽区间的节点上。
Redis 集群会把数据存在一个 master 节点,然后在这个 master 和其对应的salve 之间进行数据同步。当读取数据时,也根据一致性哈希算法到对应的 master 节点获取数据。只有当一个master 挂掉之后,才会启动一个对应的 salve 节点,充当 master 。
需要注意的是:必须要3个或以上的主节点,否则在创建集群时会失败,并且当存活的主节点数小于总节点数的一半时,整个集群就无法提供服务了。
环境准备:
一台服务器:192.168.206.6
操作系统:CentOS7.5
redis 版本: redis-5.0.0
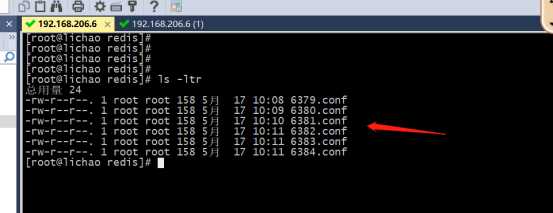
1>编辑6个配置文件
port 6379 #绑定端口
bind 192.168.206.6 #绑定对外连接提供的ip
daemonize yes #开启守护进程
pidfile 6379.pid #进程文件名
cluster-enabled yes #是否是集群
cluster-config-file 6379_node.conf #集群配置文件
cluster-node-timeout 15000 #集群连接超时时间
appendonly yes #数据持久化类型
2>启动配置文件生效
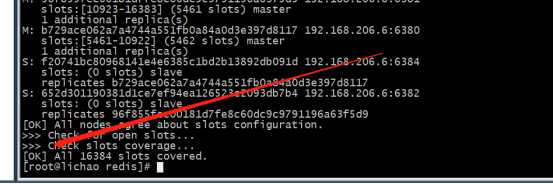
3>创建集群
redis-cli --cluster create 192.168.206.6:6379 192.168.206.6:6380 192.168.206.6:6381 192.168.206.6:6382 192.168.206.6:6383 192.168.206.6:6384 --cluster-replicas 1
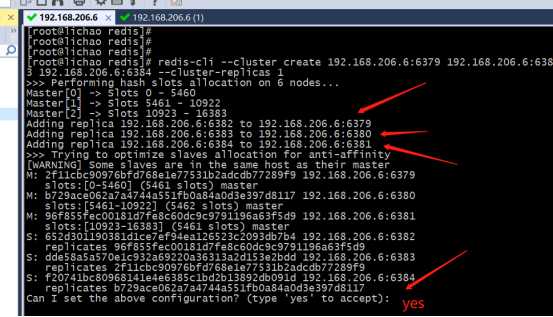
#ok
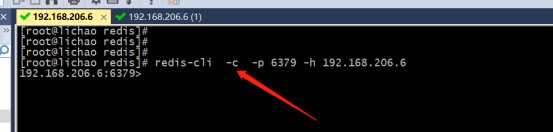
4>连接redis
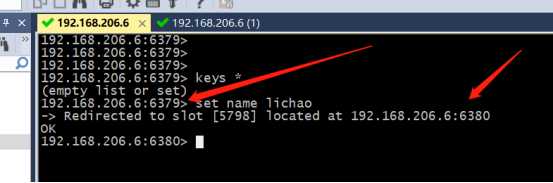
&测试
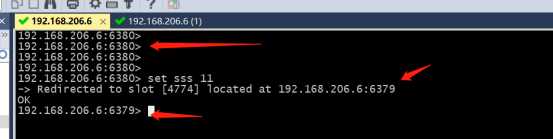
&测试2
&测试3
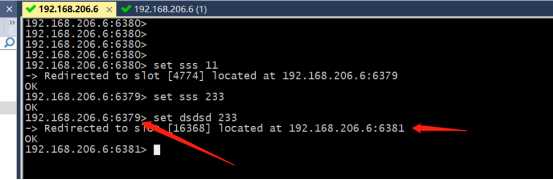
&测试宕机
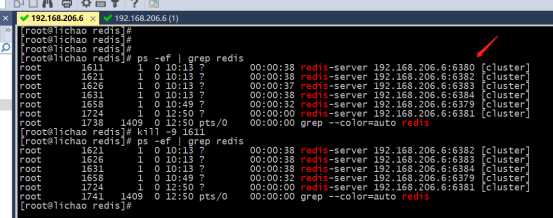
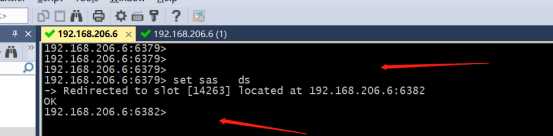
&
原文:https://www.cnblogs.com/myxxjie/p/10961058.html