前情提要:
补充知识点:
ua请求头库的使用
安装: pip install fake-useragent 使用: from fake_useragent import UserAgent ua = UserAgent() 调用指定ua: ua.ie Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US) 随机ua: ua.random
scrapy 的中间件使用
一:
下载中间件的使用
-:作用:批量拦截请求头和响应
-:拦截请求:
1:串改请求头信息(User-Agent)
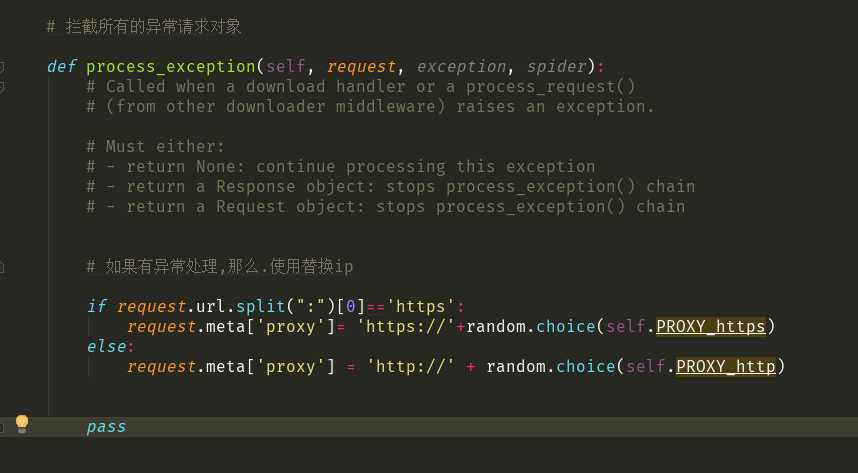
2:设置相关请求对象的代理ip(process_exception)
二:
爬虫中间件的使用
一:下载中间件的使用
1 : 中间件代码
class MiddleproDownloaderMiddleware(object): # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the downloader middleware does not modify the # passed objects. @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s #可以拦截到所有的非异常处理请求 # 参数spider 就是一个实例化的对象 # from fake_useragent import UserAgent ua = UserAgent() def process_request(self, request, spider): print(‘开始执行下载中间件‘) # 进行ua伪装 print(‘请求头是‘+self.ua.random) request.headers[‘User-Agent‘] =self.ua.random # 测试进行:代理操作看是否生效 request.meta[‘proxy‘] =‘https://218.60.8.83:3129‘ # Called for each request that goes through the downloader # middleware. # Must either: # - return None: continue processing this request # - or return a Response object # - or return a Request object # - or raise IgnoreRequest: process_exception() methods of # installed downloader middleware will be called return None # 拦截所有的响应 def process_response(self, request, response, spider): # Called with the response returned from the downloader. # Must either; # - return a Response object # - return a Request object # - or raise IgnoreRequest return response # 拦截所有的异常请求对象 def process_exception(self, request, exception, spider): # Called when a download handler or a process_request() # (from other downloader middleware) raises an exception. # Must either: # - return None: continue processing this exception # - return a Response object: stops process_exception() chain # - return a Request object: stops process_exception() chain pass #写日志 def spider_opened(self, spider): spider.logger.info(‘Spider opened: %s‘ % spider.name)
2:解析
2->1 :拦截正常的请求
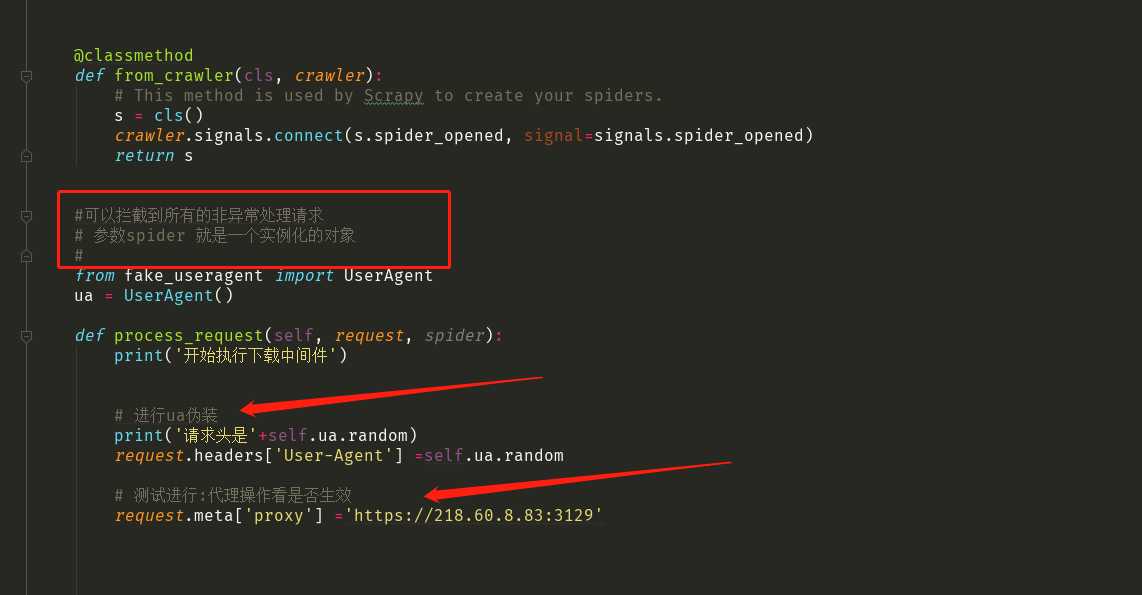
2-2>拦截异常请求
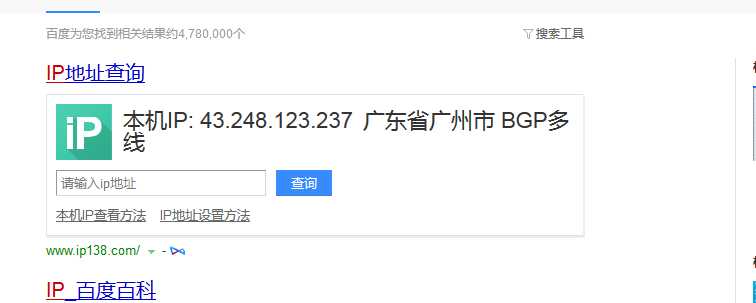
3测试结果
ip已经被替换成代理ip
且请求头已经替换成随机请求头

原文:https://www.cnblogs.com/baili-luoyun/p/10962571.html