第七章的学习主要内容是查找。
一、查找的基本概念有(1)查找表(2)关键字(3)查找(4)动态查找表和静态查找表(5)平均查找长度
二、线性表的查找
1、顺序查找
(1)从表的一端开始,依次将记录的关键字和给定值进行比较,若某个记录的关键字和给定值相等,则查找成功;反之,若扫描整个表后,仍未找到关键字和给定值相等的记录,则查找失败
(2)时间复杂度O(n)
(3)优点:算法简单,对表结构无要求,无论记录是否按关键字有序均可应用
(4)缺点:平均查找长度较大,查找效率较低
2、折半查找
(1)满足有序、顺序存储可用
(2)T(n)=O(log2(n)),S(n)=O(1)
(3)无序顺序存储:T(n)=O(nlog(n))+O(log2(n))=O(nlog2(n))
(4)关于链式存储:可以应用二分查找,但不能在log2(n)时间复杂度内,因为无法随机存取
(5)二分查找应用场景局限性(适用于静态查找):
①顺序存储
②针对有序数据
③数据量小且比较操作不耗时,不需要二分
④数据量不可太大(超出内存可用连续空间)
三、树表的查找
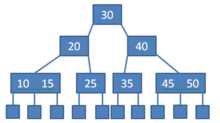
1、二叉排序树
(1)条件:
①左子树小于根节点,右子树大于根节点
②左子树是二叉排序树
③右子树是二叉排序树
(2)过程:
①查找
②插入
③创建
④删除
3、B+树
(1)B+ 树是一种树数据结构,是一个n叉树,每个节点通常有多个孩子,一颗B+树包含根节点、内部节点和叶子节点。根节点可能是一个叶子节点,也可能是一个包含两 个或 两个以上孩子节点的节点。
(2)B+ 树通常用于数据库和操作系统的文件系统中。
(3)NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系统都在使用B+树作为元数据索引。
(4)B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。
(5)B+ 树元素自底向上插入。 
所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。(而B 树的叶子节点并没有包括全部需要查找的信息)
所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。(而B 树的非终节点也包含需要查找的有效信息)
四、散列表的查找
1、主要研究问题
(1)如何构造散列函数
(2)如何处理冲突
2、好的散列函数的规则
(1)函数计算要简单,每一关键字只能由一个散列地址与之对应
(2)函数的值域须在表长的范围内,计算出的散列地址的分布应均匀,尽可能减少冲突
以上是我对第七章的学习总结,可以说大部分内容都是平时一直在接触的,查找是很重要,也很基础的,一定要掌握。
上次目标是复习提高第4、5、6章,期末将近,就不做更多的目标了,把所学知识都好好复习几次吧!
原文:https://www.cnblogs.com/lizixiang123/p/10964647.html