Solr简介
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
想要知道solr的实现原理,首先得了解什么是全文检索、solr的索引创建过程和索引索搜过程。
1. 全文检索
举个例子:现在有几个文档,我想从这几个文档中查找出包含“solr工作原理”的文档,此时有两种做法:
1)顺序扫描法:对这几个文档依次查找,包含目标字段的文档就记录下来,最后查找的结果可能在这几个文档中,这种查找方式叫做顺序扫描法。
顺序扫描法在文档数量较少的情况下,查找速度还是很快的,但是文档数量很多时,查找速度就明显不行了。
2)全文检索:对文档内容进行分词,对分词后的结果创建索引,然后通过对索引进行搜索的方式叫做全文检索。
全文检索就相当于根据偏旁部首或读音去查找字典,在文档很多的情况,这种查找速度肯定比一个一个文档查找要快。
2. 索引创建和搜索过程
1)创建索引
举例:
文档一:solr是基于Lucene开发的企业级搜索引擎技术
文档二:Solr是一个独立的企业级搜索应用服务器,Solr是一个高性能,基于Lucene的全文搜索服务器
首先经过分词器分词,solr会为分词后的结果(词典)创建索引,然后将索引和文档id列表对应起来,如下图所示:
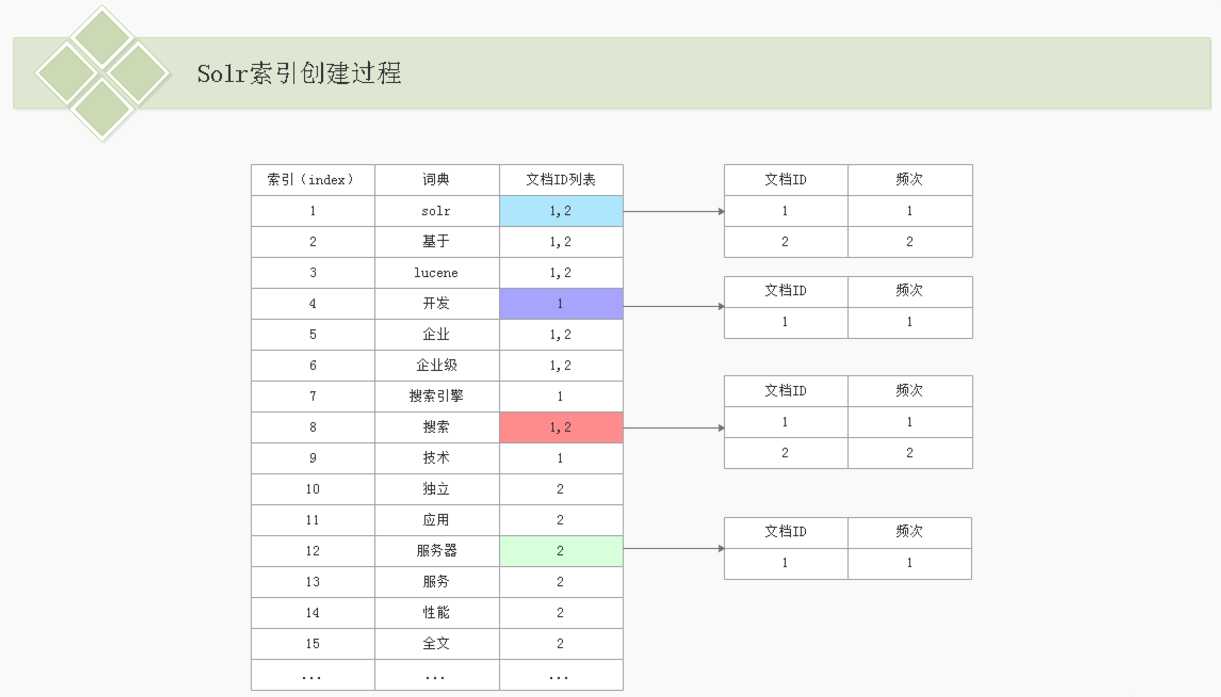
比如:solr在文档1和文档2中都有出现,所以对应的文档ID列表中既包含文档1的ID也包含文档2的ID,文档ID列表对应到具体的文档,并体现该词典在该文档中出现的频次,频次越多说明权重越大,权重越大搜索的结果就会排在前面。
solr内部会对分词的结果做如下处理:
1.去除停词和标点符号,例如英文的this,that等, 中文的”的”,”一”等没有特殊含义的词
2.会将所有的大写英文字母转换成小写,方便统一创建索引和搜索索引
3.将复数形式转为单数形式,比如students转为student,也是方便统一创建索引和搜索索引
2. 索引搜索过程
知道了创建索引的过程,那么根据索引进行搜索就变得简单了。
1.用户输入搜索条件
2.对搜索条件进行分词处理
3.对分词后的结果创建索引
4.根据索引找到文档ID列表
5.根据文档ID列表找到具体的文档,根据出现的频次等计算权重,最后将文档列表按照权重排序返回
原文:https://www.cnblogs.com/rabbitli/p/10975045.html