1:编写Spout
package wc;
import java.util.Map;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
/**
* @author Dawn
* @date 2019年6月5日15:59:04
* @version 1.0
* 需求:单词计数 hello dawn hello dawn indicate
* 实现接口:IRichSpout IRichBolt
* 继承抽象类:BaseRichSpout BaseRichSpout 常用
*/
public class WordCountSpout extends BaseRichSpout{
//定义收集器
private SpoutOutputCollector collector;
//发送数据
@Override
public void nextTuple() {
//1:发送数据到blot
collector.emit(new Values("hello dawn hello dawn indicate"));
//2.设置延迟
try {
Thread.sleep(500);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
//创建收集器
@Override
public void open(Map arg0, TopologyContext arg1, SpoutOutputCollector collector) {
this.collector=collector;
}
//声明
@Override
public void declareOutputFields(OutputFieldsDeclarer declare) {
//起别名
declare.declare(new Fields("dawn"));
}
}
2:编写分词bolt
package wc;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
/**
* @author Dawn
* @date 2019年6月5日16:09:58
* @version 1.0
* 单词切分Bolt组件
*/
public class WordCountSplitBolt extends BaseRichBolt{
//数据继续发送到下一个bolt
private OutputCollector collector;
@Override
public void execute(Tuple in) {
//1.获取数据
String line = in.getStringByField("dawn");
//2.切分数据
String[] fields = line.split(" ");
//3.<单词,1> 发送出去 下一个bolt(累加求和)
for(String w:fields) {
collector.emit(new Values(w,1));
}
}
//初始化
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector) {
this.collector=collector;
}
//声明描述
@Override
public void declareOutputFields(OutputFieldsDeclarer declare) {
declare.declare(new Fields("word","sum"));
}
}
3:编写计数bolt
package wc;
import java.util.HashMap;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
/**
* @author Dawn
* @date 2019年6月5日16:17:45
* @version 1.0
* 计数bolt
*/
public class WordCount extends BaseRichBolt{
private Map<String, Integer> map=new HashMap<>();
//累加求和
@Override
public void execute(Tuple in) {
//1.获取数据
String word = in.getStringByField("word");
Integer sum = in.getIntegerByField("sum");
//2.业务处理
if(map.containsKey(word)) {
//之前出现几次
Integer count = map.get(word);
//已有的
map.put(word, count+sum);
}else {
map.put(word, sum);
}
//3.打印控制台
System.err.println(Thread.currentThread().getName() + "\t 单词为:" + word + "\t 当前已出现次数为:" + map.get(word));
}
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector) {
}
//没有下一个阶段就不用写
@Override
public void declareOutputFields(OutputFieldsDeclarer declare) {
}
}
4:编写driver驱动类
package wc;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
/**
* @author Dawn
* @date 2019年6月5日16:18:52
* @version 1.0
* 驱动类,以及使用不同的分组策略演示(字段,随机,全局)
*/
public class WordCountDriver {
public static void main(String[] args) {
//1.hadoop->Job storm->topology 创建拓扑
TopologyBuilder builder = new TopologyBuilder();
//2.指定设置
//设置任务的spout组件
builder.setSpout("WordCountSpout", new WordCountSpout(),2);//拓扑名,数据源,并行度
//设置任务的单词拆分的bolt组件,是字段分组 并行度为2,总任务数 4
builder.setBolt("WordCountSplitBolt", new WordCountSplitBolt(),2).setNumTasks(4).fieldsGrouping("WordCountSpout", new Fields("dawn"));
//设置任务的单词计数的bolt组件,是字段分组 ,并行度为2
builder.setBolt("WordCount", new WordCount(),4).fieldsGrouping("WordCountSplitBolt", new Fields("word","sum"));
//============================================================================================================》
// //设置任务的单词拆分的bolt组件,是随机分组 并行度为2,总任务数 4
// builder.setBolt("WordCountSplitBolt", new WordCountSplitBolt(),2).setNumTasks(4).shuffleGrouping("WordCountSpout");
//
// //设置任务的单词计数的bolt组件,是随机分组 ,并行度为2
// builder.setBolt("WordCount", new WordCount(),4).shuffleGrouping("WordCountSplitBolt");
//============================================================================================================》
// //设置任务的单词拆分的bolt组件,是全局分组 并行度为2,总任务数 4
// //分配给task id值最小的 根据线程id判断,只分噢诶给线程id最小的
// builder.setBolt("WordCountSplitBolt", new WordCountSplitBolt(),2).setNumTasks(4).globalGrouping("WordCountSpout");
//
// //设置任务的单词计数的bolt组件,是全局分组 ,并行度为2
// builder.setBolt("WordCount", new WordCount(),4).globalGrouping("WordCountSplitBolt");
//
//3.创建配置信息
Config conf = new Config();
//conf.setNumWorkers(10);可以设置work数
// //集群模式运行
// try {
// StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
// } catch (AlreadyAliveException e) {
// // TODO Auto-generated catch block
// e.printStackTrace();
// } catch (InvalidTopologyException e) {
// // TODO Auto-generated catch block
// e.printStackTrace();
// } catch (AuthorizationException e) {
// // TODO Auto-generated catch block
// e.printStackTrace();
// }
//4.提交任务(本地模式)
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("wordcounttopology", conf, builder.createTopology());
}
}


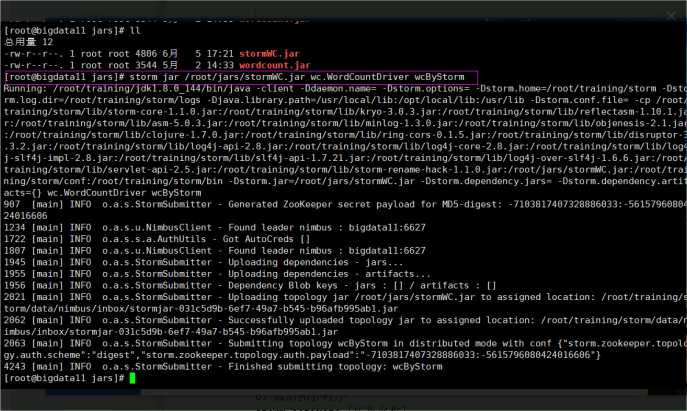

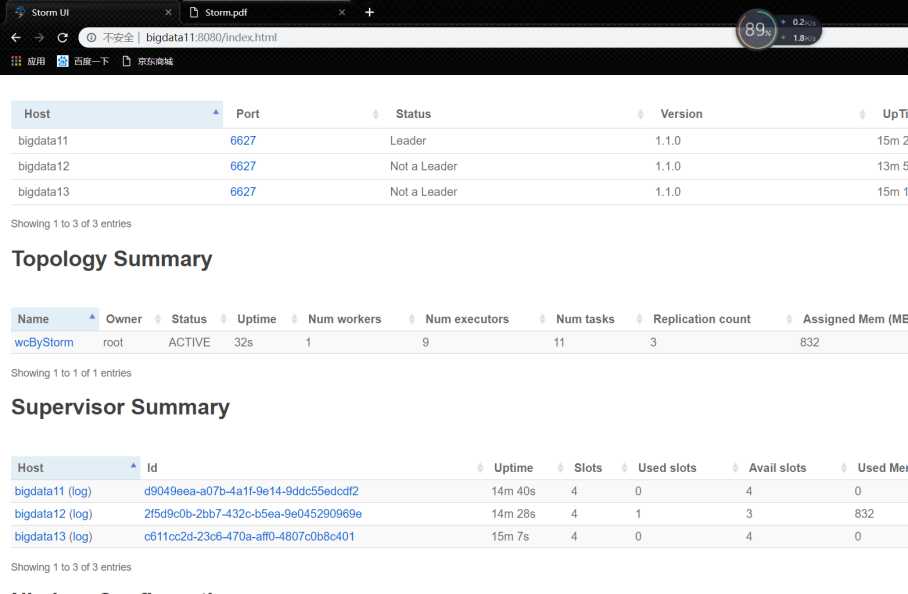
使用上面word count程序来学习分组策略
总图:参照这个来看
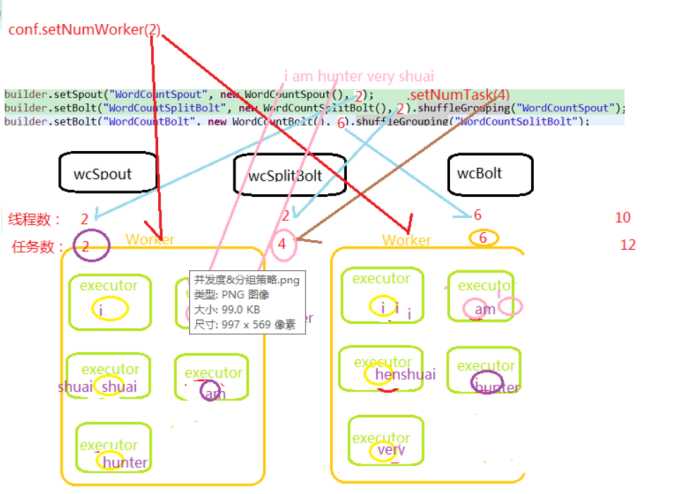
一个executor就是一个线程数
一个task就是一个任务数
按照字段分组。相同字段发送到一个task中。

运行结果:
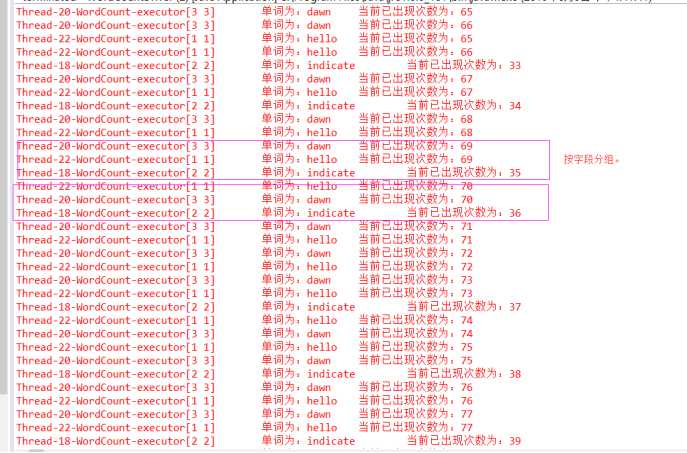
可以看出都是进行字段进行分组的,为什么了?应为我这里字段(hello dawn hello dawn indicate)也就只有3个,而且我这里并行度设置的是4(就理解为线程数)。从结果中只有3个线程在使用!!!也就是相同的字段放入一个task中。。。
随机分组。轮询。平均分配。随机分发tuple,保证每个bolt中的tuple数量相同。
运行结果:
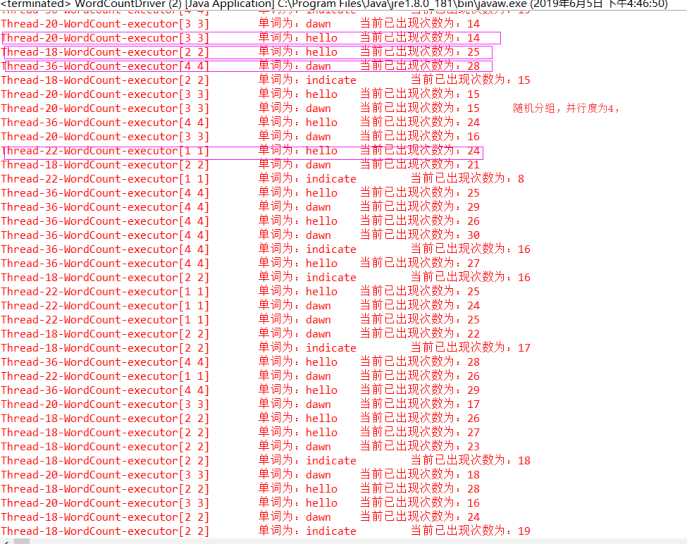
可以看出明显不是字段分组。因为这里并行度为4,并且这4个线程都用上了。平均分配。随机分发tuple,保证每个bolt中的tuple数量相同。而且这里次数出现的都有点问题。个人觉得有点像线程中的那个同步问题。(个人觉得哈!!只是助于理解,具体是不是我也不知道)
不分组
采用这种策略每个bolt中接收的单词不同。
广播发送
全局分组
分配给task id值最小的
根据线程id判断,只分噢诶给线程id最小的

运行结果:
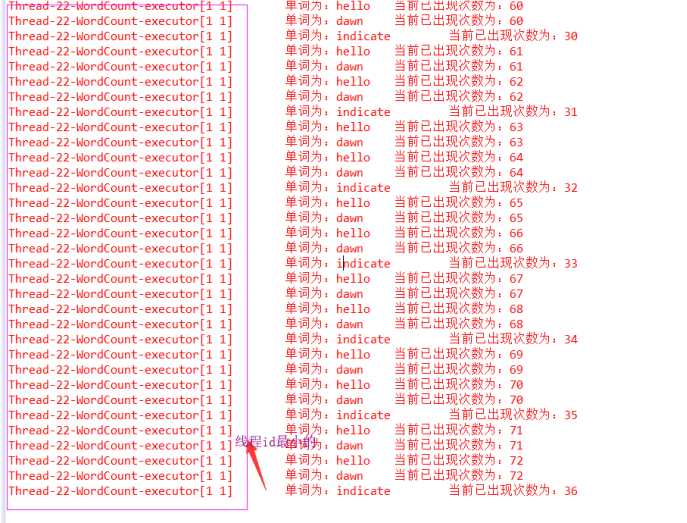
可以看出虽然我们设置了4个线程。但是这个全局分组分配给task id值(线程id)最小的。根据线程id判断,只分给线程id最小的。只用到了一个线程id最小的线程
总结:一般来说,就字段分组和随机分组用的多点。其他用的都很少
大数据学习之storm-wordcount 实时版开发以及分组策略34
原文:https://www.cnblogs.com/hidamowang/p/10981304.html