首先分析虎扑页面数据

如图我们所有需要的数据都在其中

所以我们获取需要的内容直接利用beaitifulsoupui4
``` soup.find_all(‘a‘,class_="truetit")
for p in soup.find_all(‘a‘,class_="truetit"):
# 获取a标签的内容
print("帖子的内容如下: ")
print(p.get_text())
```
就可以获取到帖子的内容
。
接下来获取帖子的热门回帖数已经用户信息,首先获取热门回帖数,我的第一想法是用p.next_sibling.next_sibling 来获取(这里要用两次sibing具体原因看官网),结果这样的话发现有很多报错如图所示!!是因为很多帖子没有热门回帖,所以导致这里没有数据! 这里需要判断下, 但是后续需要获取其他的数据的时候就会出问题,不能再次使用next_sibling了,欣慰兄弟标签就不一定了 !!所以还是使用找到父标签,然后再来处理比较合适。
接下来获取用户的主页信息
方法是获取帖子内容标签的祖父标签也就是如图所示的li标签,然后
grandPaInfo.find("div",class_="author box").a[‘href‘]这样就可以获取用户的主页信息
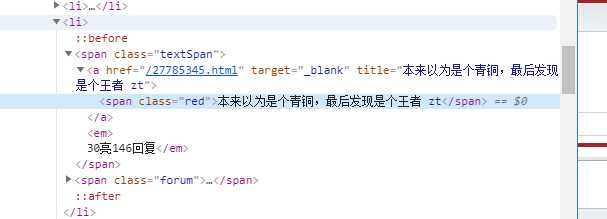
接下来需要获取用户性别
上一步获取到了用户主页信息,接下来我们需要进入这个主页进行分析
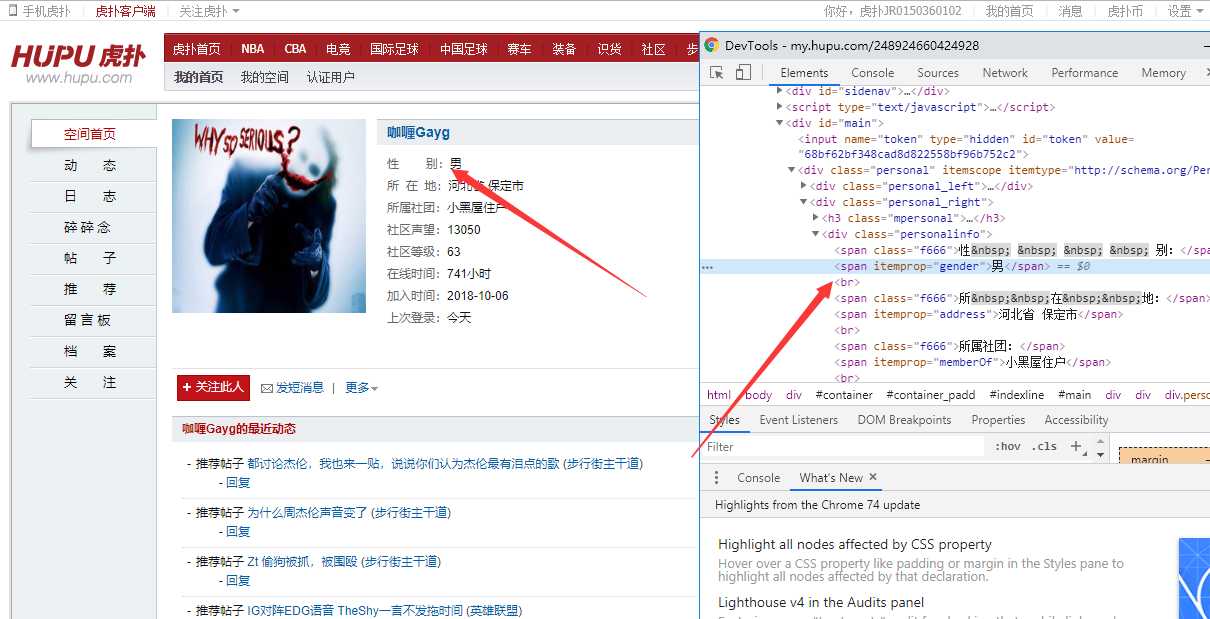
如果所示,我们可以使用如下代码获取 用户的性别信息
if soup.find(‘span‘, itemprop="gender"):
userSex = soup.find(‘span‘, itemprop="gender").get_text()
else:
userSex = "NULL"
github地址 https://github.com/zfno111/spider_hupu/tree/zhangfan
原文:https://www.cnblogs.com/ZFBG/p/10982596.html