一.数据类型 5种
1.character 字符
2.numeric 数值
3.integer 整数 一般数字的存储会默认为数值类型,如果要强调是整数,需要在变量值后面加上 L。 x <- 5L class(x)
4.complex 复数 1+2i
5.logical 逻辑 TRUE&FALSE
class()查看数据类型
R语言对大小写敏感
二。数据结构
属性:名称、维度、类型、向量结构
向量(vector):只能包含同一类型的对象。
创建向量方法1:x1 <- vector("integer",length = 4)
方法2:x2 <- 1:4
方法3:x3 <- c(1,2,3,4)
向量的其他特点,如果往向量里传的数据类型不一样,向量会强制转成同一种类型。x <- c(TRUE,10,"a") 结果都会转换成字符型元素。
向量数据类型的转换:as.xxx()
向量还可以给参量命名:
names(向量名) <- c(跟参量数量一致的名字)
向量名
矩阵和数组|matrix&array
矩阵可以看做 向量+维度属性(整数向量:nrow,ncol)
x<-matrix(1:4,nrow=2,ncol=2)
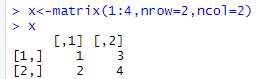
矩阵的填充方式是按列填充。
矩阵的相关函数:dim(x) 查看矩阵行列信息。
attributes()可以查询矩阵属性。
其他创建矩阵的办法(矩阵其实就是向量+维度信息)
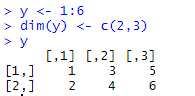
矩阵的拼接:
按行拼接
按列拼接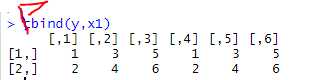
数组 array
数组与矩阵非常相似,只是维度可以大于2


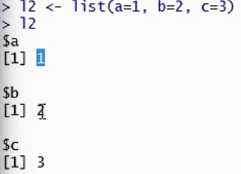
列表(是r中非常重要的数据结构
)
跟前面数据结构最大不同是可以包涵不同类型对象;可以直接给列表里的元素命名。
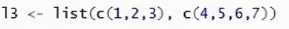
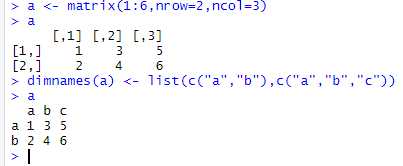
如何给矩阵的每行、每列命名?
用dimnames()
因子
分类数据,可分成有序和无序(按能否比大小来区分)
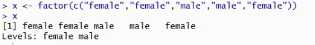

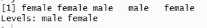
缺失值
NA&NaN
NA不属于NaN,NaN属于NA
NaN用来表示非法运算导致的缺失值,NA用来表示的范围更广。
相关函数,判断是否是na或nan is.na()
缺失值的处理,用平均数或者众数去补全。
数据框(data.frame())
用来存储表格数据,跟列表、矩阵关系都很密切。

日期与时间结构
时间分成两个类型,POSIXct/POSIXlt
表示距离1970-01-01过去了多少秒。前者存储的数据是整数,常寸在数据框中
POSIXlt是列表,包含年月日星期等

一个数据矩阵的每一行数据叫作一次观测,每一列叫作一个变量。
原文:https://www.cnblogs.com/Grayling/p/10967477.html