1,数据质量分析
2,缺失值分析
缺失值产生的原因
3,异常值的分析
import pandas as pd
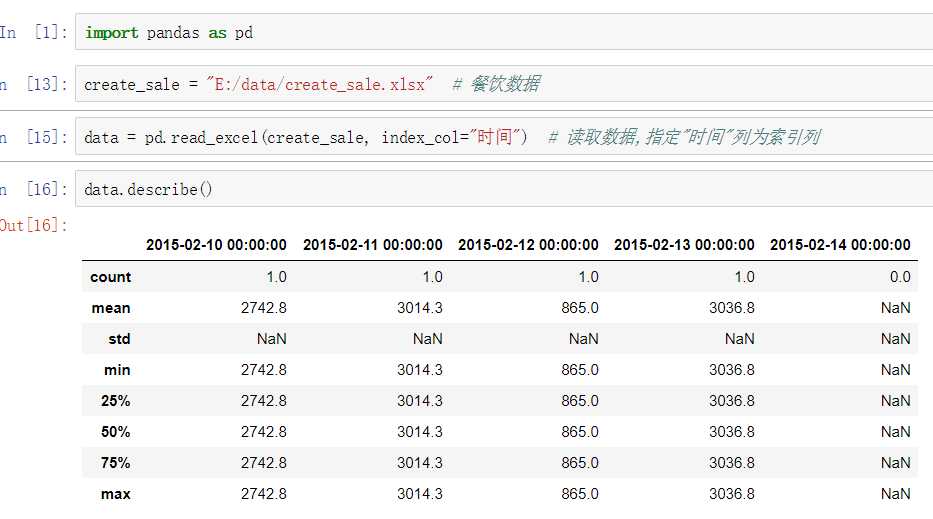
create_sale = "E:/data/create_sale.xlsx"
data = pd.read_excel(create_sale, index_col="时间")
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["SimHei"] # 用来显示正常的中文
plt.rcParams["axes.unicode_minus"] = False
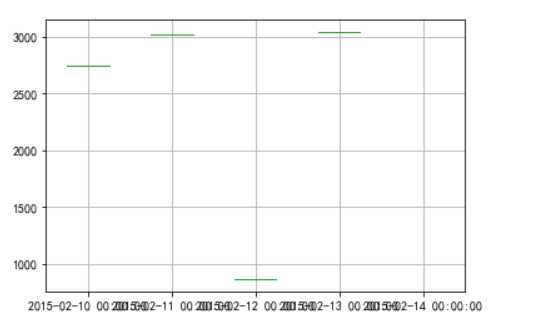
plt.figure() # 建立画像
p = data.boxplot() # 画箱线图,直接使用Dataframe的方法
print(p)
x = p["fliers"][0].get_xdata() # "filers"即为异常值的标签
y = p["fliers"][0].get_ydata()
y.sort() # 从小到大排序,该方法直接改变原对象
# 用annotate添加注释
# 其中有些相近的点,注释你会出现重叠,难以看清,需要一些技巧来控制
for i in range(len(x)):
if i > 0:
plt.annotate(y[i], xy=(x[i], y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]), y[i]))
else:
plt.annotate(y[i], xy=(x[i], y[i]), xttext=(x[i]+0.08, y[i]))
plt.show()
4,一致性分析
5,数据特征分析:
| [0,500) | [500,1000) | [1000,1500) | [1500,2000) |
| [2000,2500) | [2500,3000) | [3000,3500) | [3500,4000) |
原文:https://www.cnblogs.com/ljc-0923/p/10988394.html