一直以来,由于cpu、内存、I/O存在着巨大的速度差异,cpu>内存>I/O。为了平衡这三者的差异,计算机结构、操作系统、编译器都做出了巨大的贡献,主要体现为:
1. 增加cpu缓存,以均衡与内存的速度差异
2. 编译器优化指令执行次序,使得缓存能够更加合理利用
3. 操作系统增加进程、线程,以分时复用cpu,进而均衡cpu与I/O的速度差异
以上的优化确实提高了cpu的使用率,提升了整体程序的性能,但是也给我们的并发程序带来了一些问题
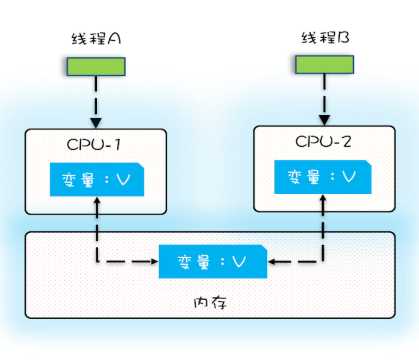
1. cpu缓存导致的可见性问题
在单核时候,只有一个cpu以及一个cpu缓存,不同的线程对应的是同一个缓存,则不存在可见性问题。在多核时代,每颗cpu都有自己的缓存,不同的线程可能操作的是不同的缓存。例如线程 A操作的是cpu1的缓存,而线程B则操作的是cpu2的缓存,很明显这个时候线程A对变量v的操作,对于线程B而言则是不可见的
2. 编译优化带来的有序性问题
编译器为了优化性能,有时候会改变语句的先后顺序,这样不但可以更加合理的利用cpu缓存,同时可以减少cpu不必要的停顿。然后编译器的优化只能保证串行语义的一致,无法保证多线程的语义也一致。在java中一个经典案例就是利用双锁检查创建单例对象。
public class Singleton { static Singleton instance; static Singleton getInstance(){ if (instance == null) { synchronized(Singleton.class) { if (instance == null) instance = new Singleton(); } } return instance; } }
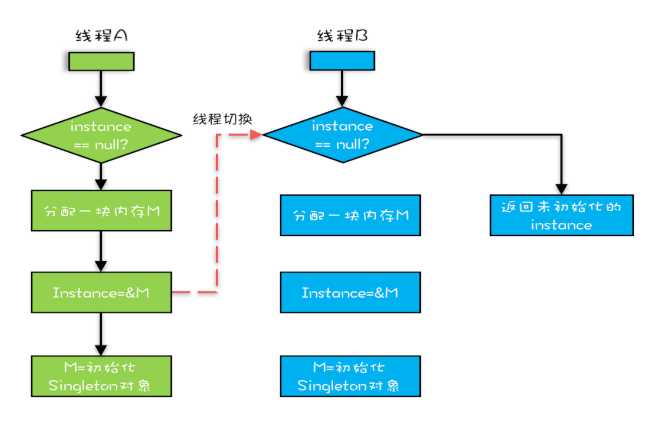
问题出在new操作上,new操作经过优化后,执行指令的顺序为:
1. 分配一块内存M
2. 将M的地址赋值给instance变量
3. 在内存M上初始化instance变量
我么假设A线程执行getInstance方法,执行完指令2后,B线程开始执行,这时B发现第一个instance==null 为false,直接返回了instance实例,然而此时instance实例还没有初始化完成,这个时候B线程访问instance的成员变量就可能触发空指针异常
3. 线程切换带来的原子性问题
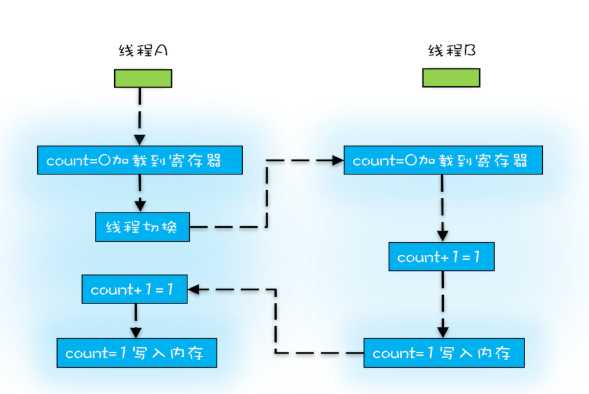
线程的切换是由操作系统来处理的,而操作系统走切换是能够发生在任何一条cpu执行完成的。而很多高级语言的一条语句对应cpu指令,count++这个操作则需要三条指令
当线程A执行完指令1后,切换到线程B则发生原子性问题

原文:https://www.cnblogs.com/hello---word/p/10989801.html