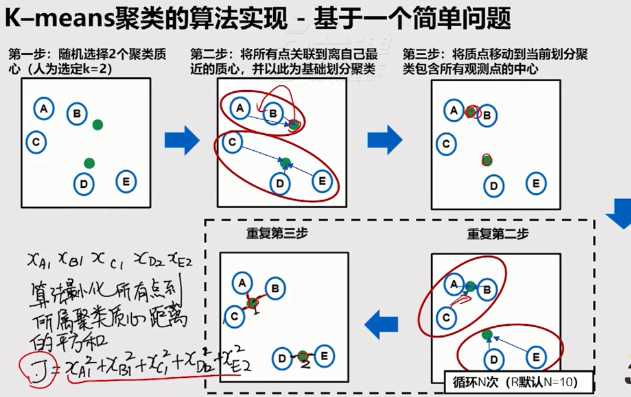
将n个观测点,按一定标准(数据点的相似度),划归到k个聚类(用户划分、产品类别划分等)中。


K-means聚类要求的变量是数值变量,方便计算距离。
R语言实现
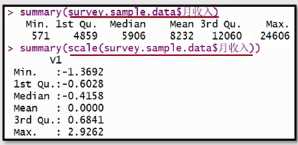
k-means算法是将数值转换为距离,然后测量距离远近进行聚类的。不归一化的会使得距离非常远。
补充:scale归一化处理的意义
两个变量之间数值差别太大,比如年龄与收入的数值差别就很大。
步骤

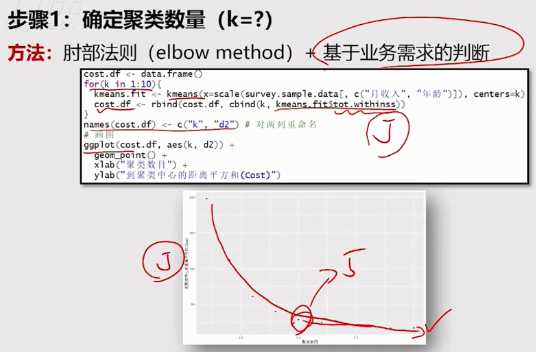
第一步,确定聚类数量,即k的值
方法:肘部法则+实际业务需求
第二步,运行K-means模型
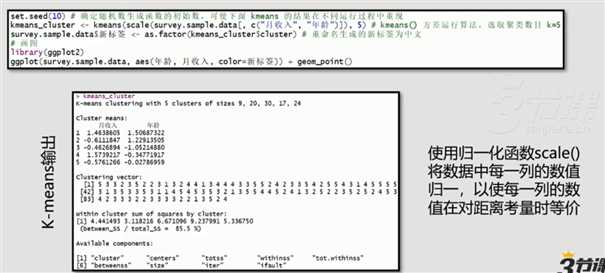
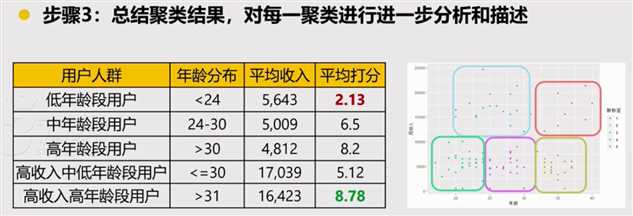
第三步,总结聚类模型结果
原文:https://www.cnblogs.com/Grayling/p/10991252.html