层次化索引是pandas的一项重要功能,他使你能在一个轴上拥有多个(两个以上)索引级别,抽象点说,它能使你以低维度形式处理高纬度数据,我们先来看一个简单的例子,创建一个Series,并用一个由列表或数组组成的列表作为索引。
date = Series(np.random.randn(10),
index = [[‘a‘,‘a‘,‘a‘,‘b‘,‘b‘,‘b‘,‘c‘,‘c‘,‘d‘,‘d‘],
[1,2,3,1,2,3,1,2,2,3]])
print(date)
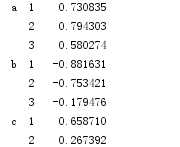
这就是带有MultiIndex索引的Series的格式化输出形式,索引之间的间隔表示直接使用上面的标签。
print (date.index)
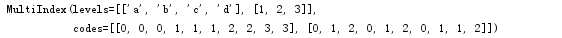
对于一个层次化索引的对象,选取数据子集很简单。
print(date[‘b‘])

print(date[‘b‘:‘c‘])
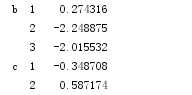
print(date.ix[[‘b‘,‘d‘]])

有时甚至可以在内层进行选取。
print(date[:,2])

层次化索引在数据重塑和基于分组的操作(如透视表生成)中扮演着重要的角色。比如说,这段数据可以通过其unstack方法被重新安排到一个DataFrame中:
print (date.unstack())

unstack的逆运算是stack:
print (date.unstack().stack())
对于一个DataFrame,每条轴都有分层索引:
frame = DataFrame(np.arange(12).reshape((4,3)),
index = [[‘a‘,‘a‘,‘b‘,‘b‘],[1,1,3,4]],
columns=[[‘OH‘,‘OH‘,‘DH‘],
[‘RE‘,‘CE‘,‘FE‘]])
print(frame)
各层都可以有名字(可以是字符串,也可以是别的Python对象)。如果指定了名称,它们就会显示在控制台输出中(不要将索引名称和轴标签混为一谈!):
frame.index.names = [‘key1‘,‘key2‘]
frame.columns.names = [‘state‘,‘color‘]
print(frame)
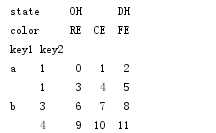
有了分部的列索引,因此可以轻松选取列分组:对于一个DataFrame,每条轴都有分层索引:
print(frame[‘OH‘])
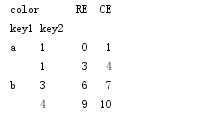
可以单独创建MultiIndex然后复用,上面那个DataFrame也可以这样创建:
MultiIndex.from.arrays([[‘OH‘,‘OH‘,‘DH‘],[‘RE‘,‘CE‘,‘FE‘]],
names = [‘state‘,‘color‘])
原文:https://www.cnblogs.com/li98/p/10991709.html
