为什么使用Keras?就像django中使用orm一样
Keras的程序设计:
我们将建立多层感知器模型,比如:输入层(x)共有784个神经元,隐藏层(h)共有256个神经元,输出层(y)有10个神经元,那如何使用Keras帮我们建立呢?
1,建立Sequential()模型:
sequential模型是多个神经网络层的线性堆叠
model = Sequential()
2,假如输入层与隐藏层到模型中
Keras已经内奸各种神经网络层(比如Dense层,Conv2d层等),只要我们建立模型时候加上我们选择好的神经网络层即可
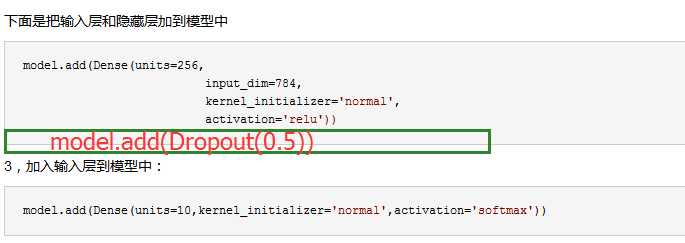
下面是把输入层和隐藏层加到模型中
model.add(Dense(units=256, input_dim=784, kernel_initializer=‘normal‘, activation=‘relu‘))
3,加入输入层到模型中:
model.add(Dense(units=10,kernel_initializer=‘normal‘,activation=‘softmax‘))
下面看一个具体的例子:
import pandas as pd import numpy as np import matplotlib.pyplot as plt import tensorflow as tf from tensorflow import keras %matplotlib
fashion_mnist = keras.datasets.fashion_mnist (train_images, train_labels), (test_images, test_labels)= fashion_mnist.load_data() # 调用load_data方法,程序会检查用户目录下是否存在MNIST的数据集,如果没有就会在屏幕上显示下载,时间长需要等待的 # 数据集下载完成之后会变成两组,分为训练集和测试集
如果是第一次使用mnist数据集的话,下载可能需要一些时间(自动下载)

train_images.shape # 看一下测试集的个数
>>>
train_labels #labels >>>array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
test_images.shape # 看一下测试集的样本

train_images[0] # 看第一张图片的样子 >>> array([[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 13, 73, 0, 0, 1, 4, 0, 0, 0, 0, 1, 1, 0], [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0, 36, 136, 127, 62, 54, 0, 0, 0, 1, 3, 4, 0, 0, 3], [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 0, 102, 204, 176, 134, 144, 123, 23, 0, 0, 0, 0, 12, 10, 0], [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 155, 236, 207, 178, 107, 156, 161, 109, 64, 23, 77, 130, 72, 15], [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 69, 207, 223, 218, 216, 216, 163, 127, 121, 122, 146, 141, 88, 172, 66], [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 200, 232, 232, 233, 229, 223, 223, 215, 213, 164, 127, 123, 196, 229, 0], [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 183, 225, 216, 223, 228, 235, 227, 224, 222, 224, 221, 223, 245, 173, 0], [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 193, 228, 218, 213, 198, 180, 212, 210, 211, 213, 223, 220, 243, 202, 0], [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 3, 0, 12, 219, 220, 212, 218, 192, 169, 227, 208, 218, 224, 212, 226, 197, 209, 52], [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 0, 99, 244, 222, 220, 218, 203, 198, 221, 215, 213, 222, 220, 245, 119, 167, 56], [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 4, 0, 0, 55, 236, 228, 230, 228, 240, 232, 213, 218, 223, 234, 217, 217, 209, 92, 0], [ 0, 0, 1, 4, 6, 7, 2, 0, 0, 0, 0, 0, 237, 226, 217, 223, 222, 219, 222, 221, 216, 223, 229, 215, 218, 255, 77, 0], [ 0, 3, 0, 0, 0, 0, 0, 0, 0, 62, 145, 204, 228, 207, 213, 221, 218, 208, 211, 218, 224, 223, 219, 215, 224, 244, 159, 0], [ 0, 0, 0, 0, 18, 44, 82, 107, 189, 228, 220, 222, 217, 226, 200, 205, 211, 230, 224, 234, 176, 188, 250, 248, 233, 238, 215, 0], [ 0, 57, 187, 208, 224, 221, 224, 208, 204, 214, 208, 209, 200, 159, 245, 193, 206, 223, 255, 255, 221, 234, 221, 211, 220, 232, 246, 0], [ 3, 202, 228, 224, 221, 211, 211, 214, 205, 205, 205, 220, 240, 80, 150, 255, 229, 221, 188, 154, 191, 210, 204, 209, 222, 228, 225, 0], [ 98, 233, 198, 210, 222, 229, 229, 234, 249, 220, 194, 215, 217, 241, 65, 73, 106, 117, 168, 219, 221, 215, 217, 223, 223, 224, 229, 29], [ 75, 204, 212, 204, 193, 205, 211, 225, 216, 185, 197, 206, 198, 213, 240, 195, 227, 245, 239, 223, 218, 212, 209, 222, 220, 221, 230, 67], [ 48, 203, 183, 194, 213, 197, 185, 190, 194, 192, 202, 214, 219, 221, 220, 236, 225, 216, 199, 206, 186, 181, 177, 172, 181, 205, 206, 115], [ 0, 122, 219, 193, 179, 171, 183, 196, 204, 210, 213, 207, 211, 210, 200, 196, 194, 191, 195, 191, 198, 192, 176, 156, 167, 177, 210, 92], [ 0, 0, 74, 189, 212, 191, 175, 172, 175, 181, 185, 188, 189, 188, 193, 198, 204, 209, 210, 210, 211, 188, 188, 194, 192, 216, 170, 0], [ 2, 0, 0, 0, 66, 200, 222, 237, 239, 242, 246, 243, 244, 221, 220, 193, 191, 179, 182, 182, 181, 176, 166, 168, 99, 58, 0, 0], [ 0, 0, 0, 0, 0, 0, 0, 40, 61, 44, 72, 41, 35, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=uint8)
plt.figure() plt.imshow(train_images[0],cmap=‘gray‘) # gray是灰度显示
plt.imshow(train_images[0]); # 彩色显示并且不显示mat类
因为图像RGB最大值是255,所以对图像进行归一化处理
train_images = train_images/255.0
test_images = test_images/255.0
下面就是建立模型:
model = keras.Sequential([ keras.layers.Flatten(input_shape=(28,28)), # 输入的数据的大小 keras.layers.Dense(128,activation=tf.nn.relu), # 一般情况下神经元的个数都是2的n次方 keras.layers.Dense(64,activation=tf.nn.relu), keras.layers.Dense(10,activation=tf.nn.softmax) # softmax用作给出预测类别的概率 ] ) # # 同样的也可以写为下面的样子 # from keras.models import Sequential # from keras.layers import Dense # # 建立模型 # model = Sequential() # # 建立输入层和隐藏层 # model.add(Dense(units=128, # 神经元个数 # input_dim=784, # 输入的数据大小即28*28 # kernel_initializer=‘normal‘, # activation=‘relu‘ # 定义激活函数为relu # )) # # 建立输出层 # model.add(Dense(units=64, # kernel_initializer=‘normal‘, # activation=‘softmax‘ # 定义激活函数为softmax # ))
# 模型的训练方式 model.compile(optimizer=‘adam‘, # 设置优化器 loss=‘categorical_crossentropy‘, # 设置损失函数,在深度学习中使用cross_entropy(交叉熵)训练的效果比较好 metrics=[‘accuracy‘])# 设置评估模型的方式是准确率,当然也支持自定义
# 模型的训练 history = model.fit(train_images, # 训练数据 train_labels, # 训练标签 epochs=50, # 训练的周期为10,一般到达一定程度就不再会增加模型的精度 batch_size=200,# 每一个批次训练200项数据 verbose=2, # 显示训练过程 validation_split=0.2) # 训练之前keras会将传入的数据按照比例划分为0.8训练和0.2验证 # 传入数据后,预测的结果将和标签进行对比,如果不一样的话,差距有多大,是用上面定义的损失函数来衡量,并用optimzer取调参
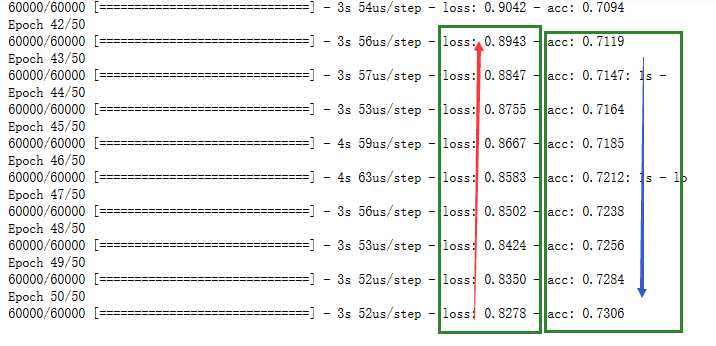
可以看到准确率acc是越来越高的,损失也是逐步降低的。
那模型训练完成之后如何去评估他的准确率呢?
test_losss,test_acc = model.evaluate(test_images,test_labels) print("Accuracy:",test_acc)
>>>
那如何判断是否还有进一步的空间呢?
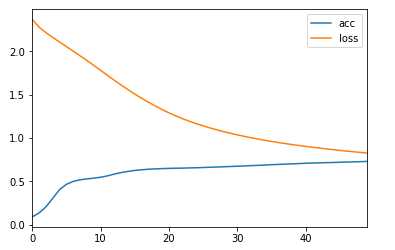
# 绘制出acc和loss hist_data = pd.DataFrame(history.history) # 先转为DataFrame hist_data.plot(kind="line") # 可以看到acc和loss并没有交叉,说明收敛还是不到位的,可以通过增加隐藏层,或者增加epochs
预测:
# 推荐 prediction = model.predict_classes(test_images) # 得到所有标签值 # 不推荐 # predictions = model.predict(test_images) # 预测所有 # predictions[2] # 预测给出的是一堆浮点数,得到的是预测label各个值得概率 # np.argmax(predictions[2]) # 利用np获取最大值索引 # test_labels[2]
那会不会出现过拟合的情况呢?
如何避免?
加入Dropout功能避免过度拟合
from keras.layers import Dropout # 导入dropout模块 model.add(Dropout(0.5)) # 加入Dropout功能
查看模型摘要:
print(model.summary())
几个隐藏层就加入几个Dropout即可很大程度上减少过拟合。
这样的预测没有考虑到图像的特征,所有下一个博客将使用卷积神经网络,更加提高模型的准确率。
原文:https://www.cnblogs.com/zhoulixiansen/p/10982136.html
