浏览器会自动给url后加一个“/” django会自动给路由的正则表达式前面加一个“/” django会给任何不带“/”结尾的url语句添加“/”(可设置) 短路路由规则:匹配到第一条就忽略后面所有! 所以路由顺序很重要!
注意:第一个参数是正则表达式,匹配规则按照从上往下一次匹配,匹配到一个之后立即匹配,直接执行对应的视图函数
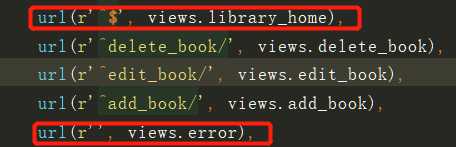
网站首页路由
url(r‘^$‘,views.home)
网站不存在页面
url(r‘‘,views.error)
urlpatterns = [ url(r‘^admin/‘, admin.site.urls), url(r‘^index/$‘, views.index), ]
url映射一般是一条正则表达式,“^” 字符串的开始,“$“ 字符串的结束
当写成\^$不输入任何url时不会在返回黄页,而是返回后面函数里对应的页面。一般这一条会写在url的最后
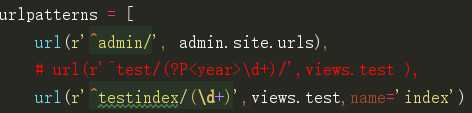
将加括号的正则表达式匹配到的内容当做位置参数自动传递给对应的视图函数 url(r‘^test/(\d+)/‘,views.test), # 匹配一个或多个数字 def test(request,xxx): print(xxx) return HttpResponse(‘test‘)
将加括号的正则表达式匹配到的内容当做关键字参数自动传递给对应的视图函数 url(r‘^test/(?P<year>\d+)/‘,views.test), # 匹配一个或多个数字 def test(request,year): print(year) return HttpResponse(‘test‘)
注意:无名分组和有名分组不能混着用!!! url(r‘^test/(\d+)/(?P<year>\d+)/‘,views.test)
但是支持用一类型多个形式匹配 无名分组多个 url(r‘^test/(\d+)/(\d+)/‘,views.test), 有名分组多个 url(r‘^test/(?P<year>\d+)/(?P<xxx>\d+)/‘,views.test),
试想一个场景,你有200多个a标签,href都指向index/,有一天在urls里面index改为了new_index,那么你只能手动改变a标签中的href,当你改完,又变成了my_index,那么一天的时间都可能在改地址,那么有没有什么方法,不再把程序写死,反向解析就是应用于此。
通过名字反向推导出页面文件,类似于字典
from django.shortcuts import reverse url(r‘^index6668888/$‘,views.index,name=‘index‘) # 可以给每一个路由与视图函数对应关系起一个名字 # 这个名字能够唯一标识出对应的路径 # 注意这个名字不能重复是唯一的
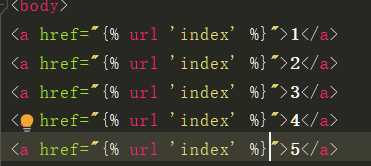
{% url ‘index‘ %} # {% url ‘放urls.py中路由与视图函数的name的值‘ %}
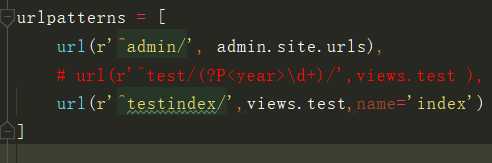
正则里面的路径名之后就可以任意修改了 name里面的值不建议修改
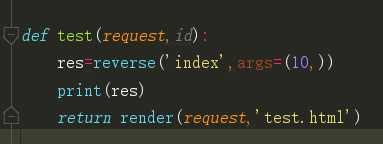
from django.shortcuts import reverse def test(request): res=reverse(‘index‘) print(res) return render(request,‘test.html‘)
{%for user_obj in user_list%}
<a href=‘edit/{{ user_obj.pk }}/‘></a>
{% endfor %}
from django.shortcuts import reverse def edit(request,edit_id): url = reverse(‘edit‘,args=(edit_id,))
{% url ‘edit‘ edit_id %}
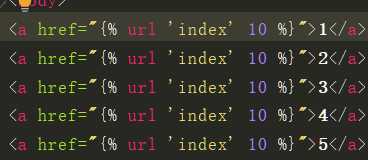
{% url ‘index‘ 1 %} # {% url ‘放urls.py中路由与视图函数的name的值‘ %} 推荐你用这种
<a href="{% url ‘index‘ year=1 %}">999</a>
res = reverse(‘index‘,args=(1,)) # 推荐你用这种 res = reverse(‘add‘,kwargs={‘year‘:1})
url = r‘^反向/无名(有名)‘,view.‘(传无名)‘,name=(‘反向‘) def xxx (request 无名) reverse(‘反向‘,args(无名,)) render(request,‘.html‘,{‘无名‘:无名}) 前端 href={%url ‘反向‘ 无名%}
django每一个app下面都可以有自己的urls.py路由层,templates文件夹,static文件夹
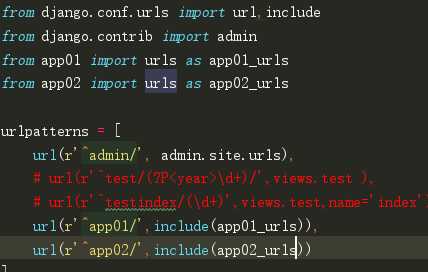
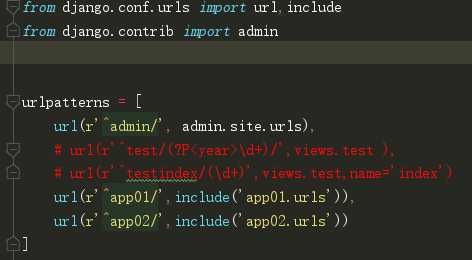
项目名下urls.py(总路由)不再做路由与视图函数的匹配关系而是做路由的分发
注意:路由分发 注意路由分发总路由千万不要$结尾
# 在应用下新建urls.py文件,在该文件内写路由与视图函数的对应关系即可 from django.conf.urls import url from app01 import views urlpatterns = [ url(r‘^index/‘,views.index) ]
内部用到了反射
如果两个app下起了相同的名字,那么反向解析不支持自动查找应用前缀
url(r‘^app01/‘,include(app01_urls,namespace=‘app01‘)), url(r‘^app02/‘,include(app02_urls,namespace=‘app02‘)) app01.urls.py from django.conf.urls import url from app01 import views urlpatterns = [ url(r‘^index/‘,views.index,name=‘index‘) ] app02.urls.py from django.conf.urls import url from app02 import views urlpatterns = [ url(r‘^index/‘,views.index,name=‘index‘) ] app01.views.py reverse(‘app01:index‘) app02.views.py reverse(‘app02:index‘)
假装自己的路径是一个静态(数据写死的)文件的路径,其实你
是经过了视图函数处理,动态渲染页面
提高百度收藏你这个网页力度,当别人搜索你这个页面相关的内容
百度会优先展示你的页面(这样虽然能提高你网页被访问概率,但是还是干不过RMB玩家)
url(r‘^index.html‘,views.index,name=‘app01_index‘)
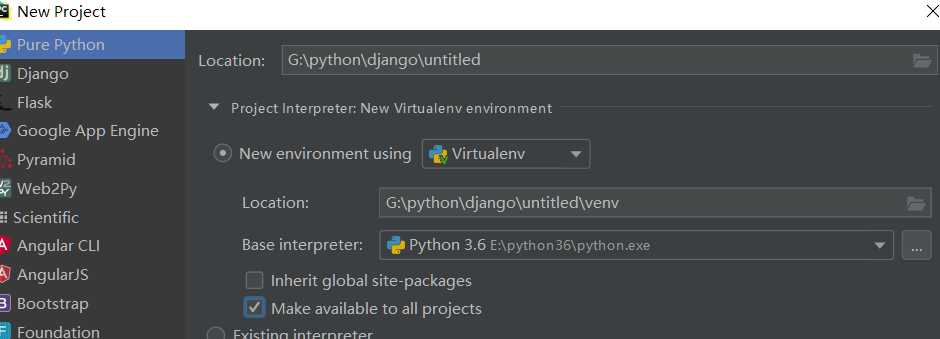
由来:
每个项目用到的模块不一样
目的:
为了让每一个项目都有仅仅属于自己的项目解释器
使用:
new project的时候选择虚拟环境创建项目
如果勾选了下面的make to all project你创建的虚拟环境就能够被其他新建的项目使用
1.0里面的url对应django2.0里面re_path
django2.0里面的path第一个是精准匹配(你怎么写的,我就怎么匹配)
django1.0版本中匹配到的参数都是字符串类型
1.0版本的url和2.0版本的re_path分组出来的数据都是字符串类型
默认有五个转换器,感兴趣的自己可以课下去试一下
str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式
int,匹配正整数,包含0。
slug,匹配字母、数字以及横杠、下划线组成的字符串。
uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
path,匹配任何非空字符串,包含了路径分隔符(/)(不能用?)
path(‘index/<str:id>/‘,index )
1.正则表达式
2.类
3.注册
class FourDigitYearConverter: regex = ‘[0-9]{4}‘ def to_python(self, value): return int(value) def to_url(self, value): return ‘%04d‘ % value # 占四位,不够用0填满,超了则就按超了的位数来! register_converter(FourDigitYearConverter, ‘yyyy‘) PS:路由匹配到的数据默认都是字符串形式
django必会三板斧
1.HttpResponse >>> 返回字符串
2.render >>> 支持模板语法,渲染页面,并返回给前端
3.redirect >>> 重定向(即可以重定向到别人的网址,也可以重定向到自己路由)
django返回的数据都是HttpResponse对象
JsonResponse(返回json格式的数据)
from django.http import JsonResponse def index(request): # res = {‘name‘:‘Jason大帅比‘,‘password‘:18} # return HttpResponse(json.dumps(res)) return JsonResponse({‘name‘:‘Jason大帅比‘,‘password‘:‘1888888‘},json_dumps_params={‘ensure_ascii‘:False})
FBV:基于函数的视图
CBV:基于类的视图
from django.views import View # Create your views here. class MyCls(View): def get(self): return HttpResponse(‘get‘) def post(self): return HttpResponse(‘post‘)
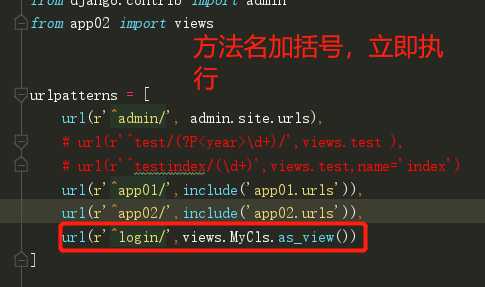
url(r‘^login/‘,views.MyCls.as_view()) # >>>等价于 url(r‘^login/‘,views.view)
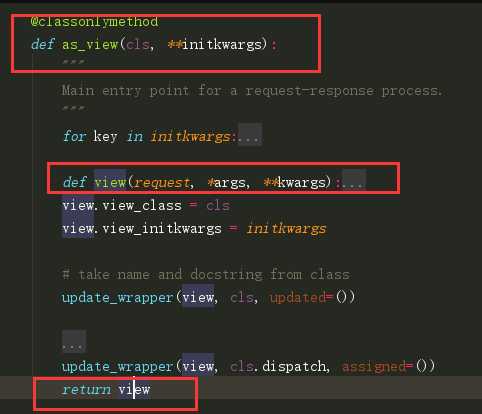
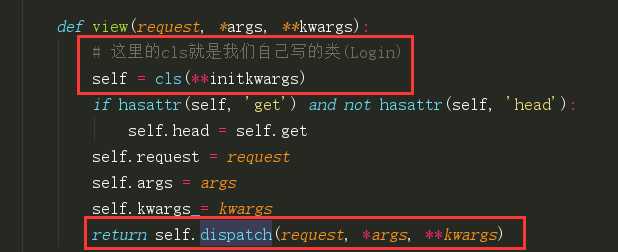
为什么我get请求就走get方法,post请求就走post方法

前端需要注意的点:
1.method需要指定成post
2.enctype必须是multipart/form-data

def upload(request): if request.method == ‘POST‘: # print(request.FILES) # print(type(request.FILES)) # print(request.FILES.get(‘myfile‘)) # print(type(request.FILES.get(‘myfile‘))) # 获取文件对象 file_obj = request.FILES.get(‘myfile‘) # print(file_obj.name) # 获取文件名 file_name = file_obj.name # 文件读写操作 with open(file_name,‘wb‘) as f: # for line in file_obj: for line in file_obj.chunks(): #l类似于迭代器,每次取一行 f.write(line) return render(request,‘upload.html‘)
request的八种属性: request.GET request.POST request.method request.body 原始数据 request.path # /upload/ request.get_full_path() # /upload/?id=1 request.META 网页原信息 request.FILES 文件
原文:https://www.cnblogs.com/zhengyuli/p/11000582.html