MQ的优点和缺点?
优点:解耦 异步,削峰
解耦:
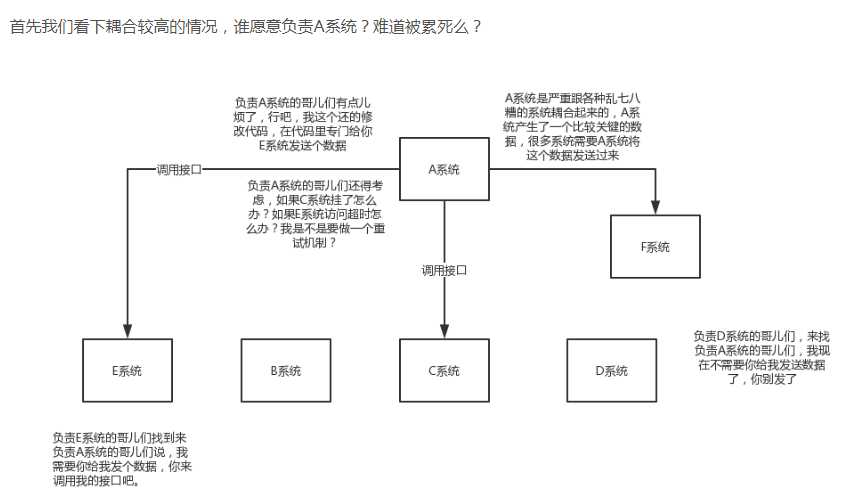
所以需要用来解耦:
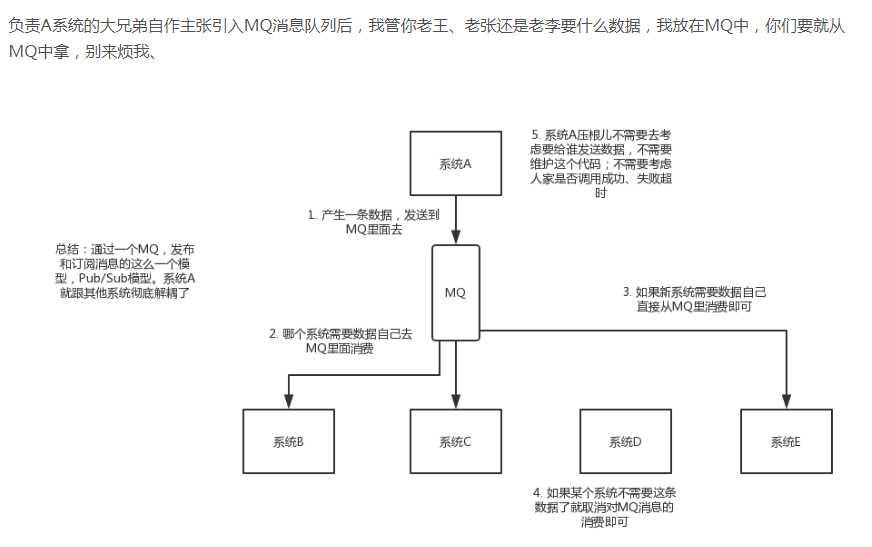
异步:
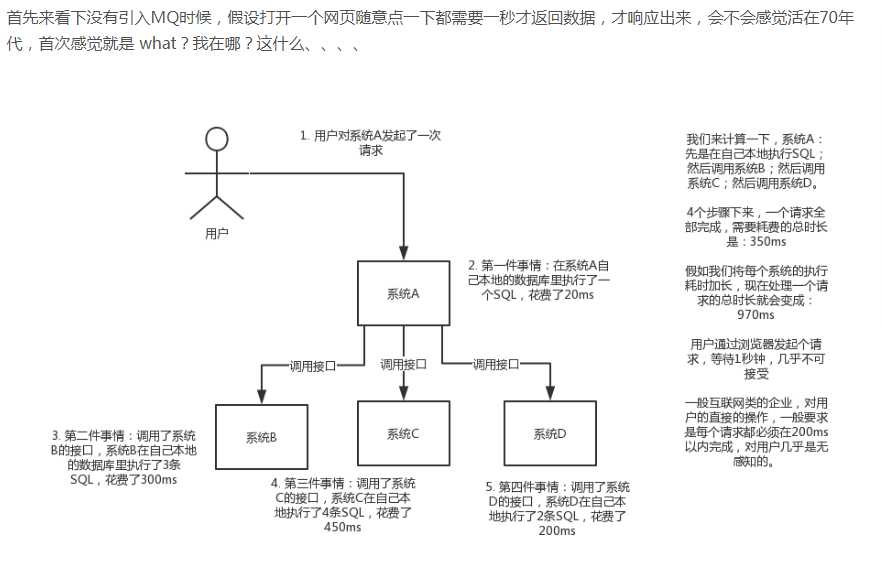
解决方法:
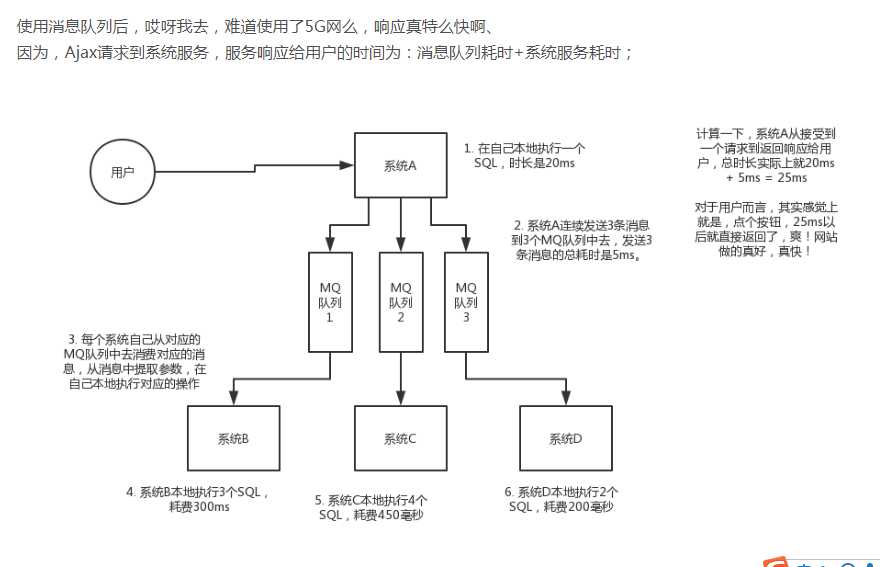
削峰:
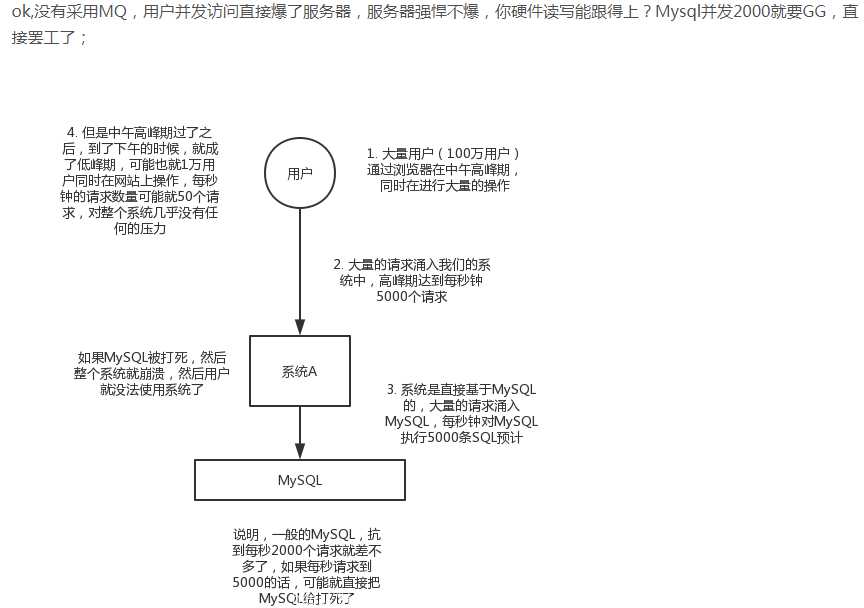
解决方法是:

缺点:降低高可用性.增加系统的复杂程度.一致性问题
降低高可用的原因:系统引入的外部依赖越多,越容易挂掉,本来你就是A系统调用BCD三个系统的接口就好了,现在又加入一个mq,万一mq挂掉了,整个系统也就崩溃了.
增加系统的复杂程度:硬生生的增加一个MQ进来怎么保证不被重复消费?怎么保证不会出现消息丢失的情况?怎么保证消息传递的顺序性?
一致性问题:系统A处理完以后直接返回成功了,人家都认为你这个请求成功了,但问题是,要是BCD三个系统成功了,结果C系统写库失败了,咋整?数据就不一致了.
如果发生丢消息的时候怎么解决?
采用持久化订阅的方式,防止消息的丢失 PTP模式,持久化是不会丢失消息的.
同时还可以采用mq手动签到的方式,client真的接收到了消息,才签到,否则就不能签到,直接接收再签到.
怎么保证MQ不会重复发送消息?
采用的是一张表来记录消息处理的状态,在处理MQ发送的消息的时候,我先查看一下这张表,是不是处理过相同的消息.如果发送过,就不在发送.
MQ重复消费的问题
1.首先产生mq重复消费的问题的原因
1.1 首先假如生产者生产数据,生产的数据都有一个offset标号,代表这个数据消费的顺序的序号
1.2 例如生产者生产了三条消息152,153,154,这时发送到mq,
1.3 mq按照顺序将数据提交到消费者
1.4 消费者是定时将消费的数据记录提交到zookeeper zk中记录了现在消费到第几条数据,告诉mq
1.5 如果此时消费了152,153消费者重启了,那么记录没提交到zk,此时mq以为消费者才消费到151,还会重新提交152,153
1.6 此时数据就出现了重复的问题,数据库就出现了脏数据
2.如何解决mq的重复消费问题
2.1 重复消费的问题会导致数据库出现脏数据,我们一般通过保证幂等性来解决这个问题
2.2 幂等性是什么。一次和多次请求某一个资源对于资源本身应该具有同样的结果。如何保证生产者重复消费数据保证幂等性
2.3 有多种方式实现。最简单的在插入数据库的数据加个唯一健,这样你插入相同的数据的时候只会保错,不会出现脏数据
2.4 在redis中存个id,每次操作数据之前查下id是否存在。存在的话就不做处理,不存在的话,我们就操作数据库。这样解决幂等性问题
mq消息的顺序是怎么进行保证的?
消息被发送的时候保持顺序
消息被存储的时候保持和发送的顺序的一致
消息被消费的时候保持和存储的消息顺序一致.
kafka、activemq、rabbitmq、rocketmq都有什么优缺点?
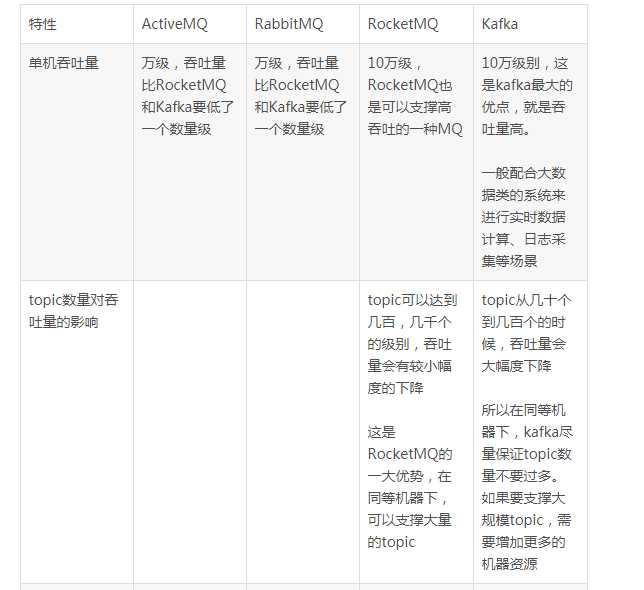
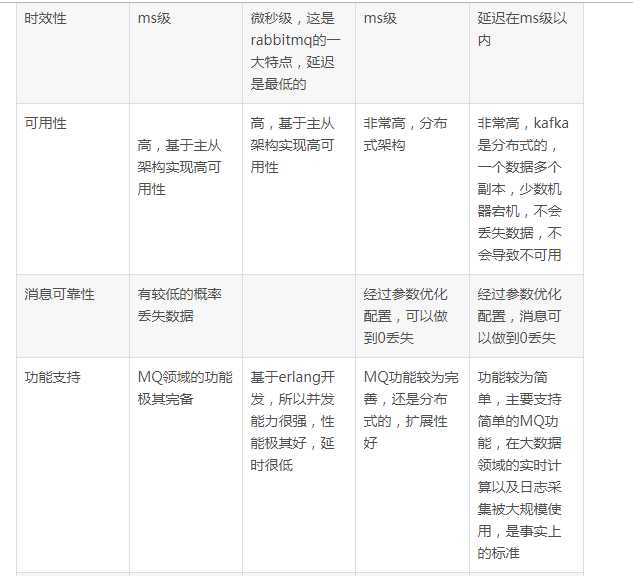
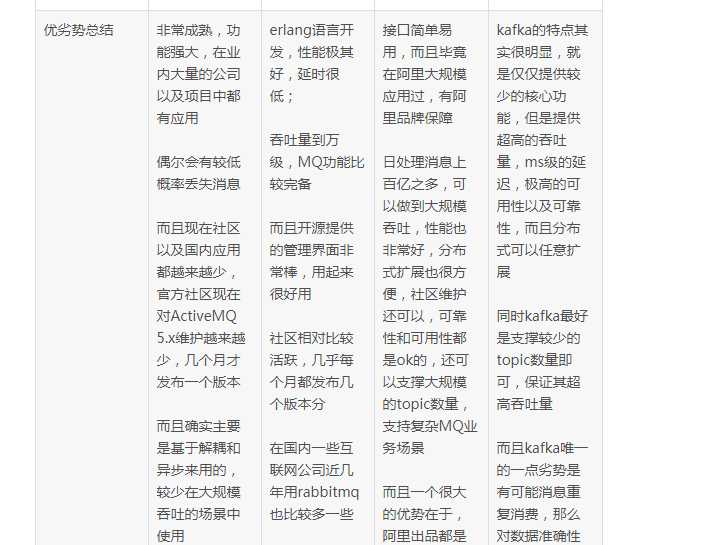

1. 引入消息队列之后如何保证其高可用性?
(1)RabbitMQ的高可用性
RabbitMQ是比较有代表性的,因为是基于主从做高可用性的,我们就以他为例子讲解第一种MQ的高可用性怎么实现。
rabbitmq有三种模式:单机模式,普通集群模式,镜像集群模式
(1.1) 单机模式
就是demo级别的,一般就是你本地启动了玩玩儿的,没人生产用单机模式
(1.2)普通集群模式
意思就是在多台机器上启动多个rabbitmq实例,每个机器启动一个。但是你创建的queue,只会放在一个rabbtimq实例上,但是每个实例都同步queue的元数据。完了你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从queue所在实例上拉取数据过来。
这种方式确实很麻烦,也不怎么好,没做到所谓的分布式,就是个普通集群。因为这导致你要么消费者每次随机连接一个实例然后拉取数据,要么固定连接那个queue所在实例消费数据,前者有数据拉取的开销,后者导致单实例性能瓶颈。
而且如果那个放queue的实例宕机了,会导致接下来其他实例就无法从那个实例拉取,如果你开启了消息持久化,让rabbitmq落地存储消息的话,消息不一定会丢,得等这个实例恢复了,然后才可以继续从这个queue拉取数据。
所以这个事儿就比较尴尬了,这就没有什么所谓的高可用性可言了,这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个queue的读写操作。
原文:https://www.cnblogs.com/qingmuchuanqi48/p/11006760.html