导言:本文从微积分相关概念,梳理到概率论与数理统计中的相关知识,但本文之压轴戏在本文第4节(彻底颠覆以前读书时大学课本灌输给你的观念,一探正态分布之神秘芳踪,知晓其前后发明历史由来),相信,每一个学过概率论与数理统计的朋友都有必要了解数理统计学简史,因为,只有了解各个定理.公式的发明历史,演进历程.相关联系,才能更好的理解你眼前所见到的知识,才能更好的运用之。
5部分起承转合,彼此依托,层层递进。且在本文中,会出现诸多并不友好的大量各种公式,但基本的概念.定理是任何复杂问题的根基,所以,你我都有必要硬着头皮好好细细阅读。最后,本文若有任何问题或错误,恳请广大读者朋友们不吝批评指正,谢谢。
开头前言说,微积分是概数统计基础,概数统计则是DM&ML之必修课”,是有一定根据的,包括后续数理统计当中,如正态分布的概率密度函数中用到了相关定积分的知识,包括最小二乘法问题的相关探讨求证都用到了求偏导数的等概念,这些都是跟微积分相关的知识。故咱们第一节先复习下微积分的相关基本概念。
事实上,古代数学中,单单无穷小、无穷大的概念就讨论了近200年,而后才由无限发展到极限的概念。
极限又分为两部分:数列的极限和函数的极限。
定义 如果数列{xn}与常a 有下列关系:对于任意给定的正数e (不论它多么小), 总存在正整数N , 使得对于n >N 时的一切xn, 不等式 |xn-a |<e都成立, 则称常数a 是数列{xn}的极限, 或者称数列{xn}收敛于a , 记为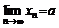 或
或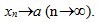
也就是说,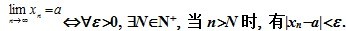
设函数f(x)在点x0的某一去心邻域内有定义. 如果存在常数A, 对于任意给定的正数e (不论它多么小), 总存在正数d, 使得当x满足不等式0<|x-x0|<d 时, 对应的函数值f(x)都满足不等式 |f(x)-A|<e , 那么常数A就叫做函数f(x)时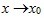 的极限, 记为
的极限, 记为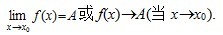
也就是说,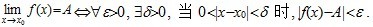
几乎没有一门新的数学分支是某个人单独的成果,如笛卡儿和费马的解析几何不仅仅是他们两人研究的成果,而是若干数学思潮在16世纪和17世纪汇合的产物,是由许许多多的学者共同努力而成。
甚至微积分的发展也不是牛顿与莱布尼茨两人之功。在17世纪下半叶,数学史上出现了无穷小的概念,而后才发展到极限,到后来的微积分的提出。然就算牛顿和莱布尼茨提出了微积分,但微积分的概念尚模糊不清,在牛顿和莱布尼茨之后,后续经过一个多世纪的发展,诸多学者的努力,才真正清晰了微积分的概念。
也就是说,从无穷小到极限,再到微积分定义的真正确立,经历了几代人几个世纪的努力,而课本上所呈现的永远只是冰山一角。
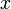 在
在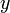 取得增量
取得增量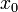 处可导,并称这个极限为函数处的导数,记为
处可导,并称这个极限为函数处的导数,记为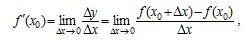
也可记为: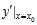 ,
,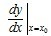 或
或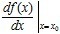 。
。
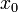 ,当变动到附近的相应于自变量增量
,当变动到附近的相应于自变量增量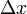 的微分,记作
的微分,记作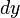 ,即
,即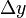 的线性主部。通常把自变量
的线性主部。通常把自变量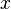 的增量
的增量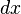 ,即
,即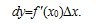 。
。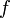 的不定积分,也称为原函数或反导数,是一个导数等于的函数
的不定积分,也称为原函数或反导数,是一个导数等于的函数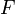 ,即
,即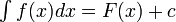
 ,在一个实数区间
,在一个实数区间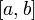 上的定积分
上的定积分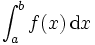
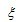 使下式成立:
使下式成立: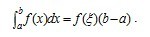
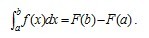
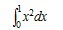 ,由于
,由于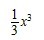 是
是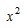 的一个原函数,所以
的一个原函数,所以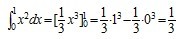 。
。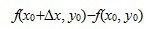 ,
,
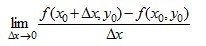
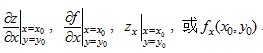
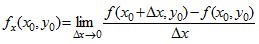 。类似的,二元函数对y求偏导,则把x当做常量。
。类似的,二元函数对y求偏导,则把x当做常量。(一)样本空间
定义:随机试验E的所有结果构成的集合称为E的 样本空间,记为S={e},
称S中的元素e为样本点,一个元素的单点集称为基本事件.
(二)条件概率
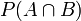 或者
或者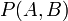 。
。
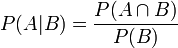
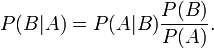 。
。
(三)全概率公式和贝叶斯公式
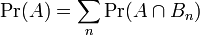
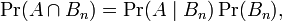
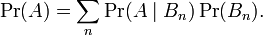
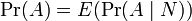 。但后者在连续情况下仍然成立:此处N是任意随机变量。这个公式还可以表达为:”A的先验概率等于A的后验概率的先验期望值。
。但后者在连续情况下仍然成立:此处N是任意随机变量。这个公式还可以表达为:”A的先验概率等于A的后验概率的先验期望值。
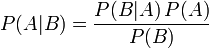
根据条件概率的定义,在事件B发生的条件下事件A发生的概率是
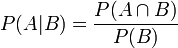
同样地,在事件A发生的条件下事件B发生的概率
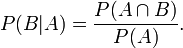
整理与合并这两个方程式,我们可以找到
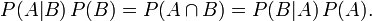
这个引理有时称作概率乘法规则。上式两边同除以P(B),若P(B)是非零的,我们可以得到贝叶斯定理:
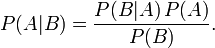
何谓随机变量?即给定样本空间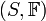 ,其上的实值函数
,其上的实值函数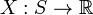 称为(实值)随机变量。
称为(实值)随机变量。
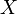 的取值是有限的或者是可数无穷尽的值为离散随机变量(用白话说,此类随机变量是间断的)。
的取值是有限的或者是可数无穷尽的值为离散随机变量(用白话说,此类随机变量是间断的)。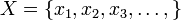
由全部实数或者由一部分区间组成,则称为连续随机变量,连续随机变量的值是不可数及无穷尽的(用白话说,此类随机变量是连续的,不间断的):
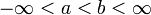
也就是说,随机变量分为离散型随机变量,和连续型随机变量,当要求随机变量的概率分布的时候,要分别处理之,如:
再换言之,对离散随机变量用求和得全概率,对连续随机变量用积分得全概率。这点包括在第4节中相关期望.方差.协方差等概念会反复用到,望读者注意之。

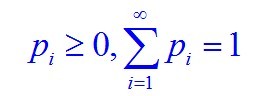
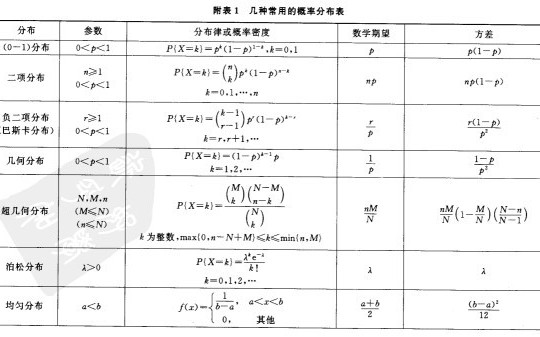
(一)(0-1)分布
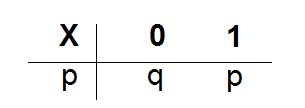
(二)、二项分布
(三)、泊松分布(Poisson分布)
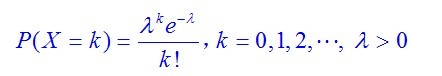
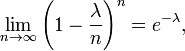
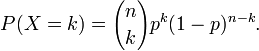
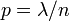 ,
,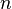 趋于无穷时
趋于无穷时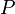
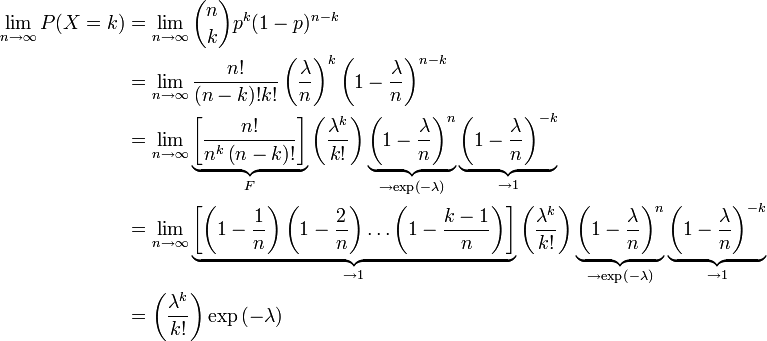
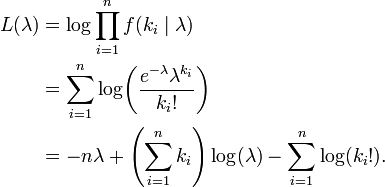
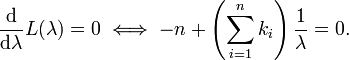
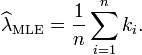
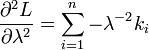
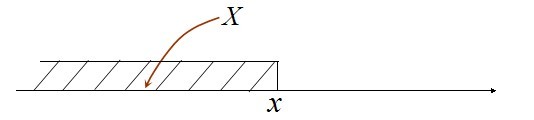

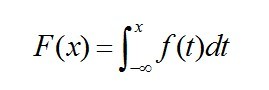
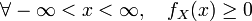 ;
;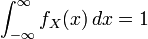 ;
;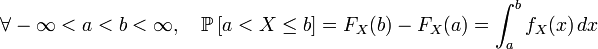 ;
;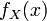 在一点
在一点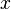 上连续,那么累积分布函数可导,并且它的导数:
上连续,那么累积分布函数可导,并且它的导数: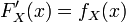 。如下图所示:
。如下图所示: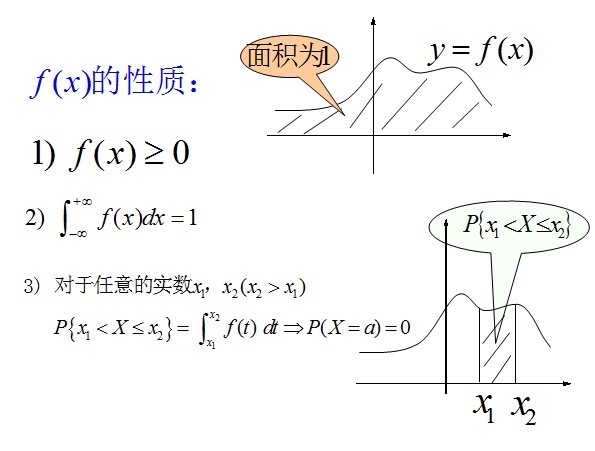

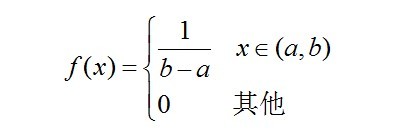
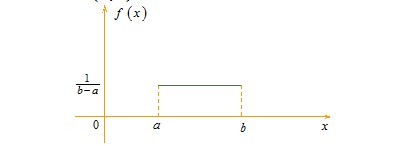
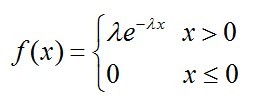
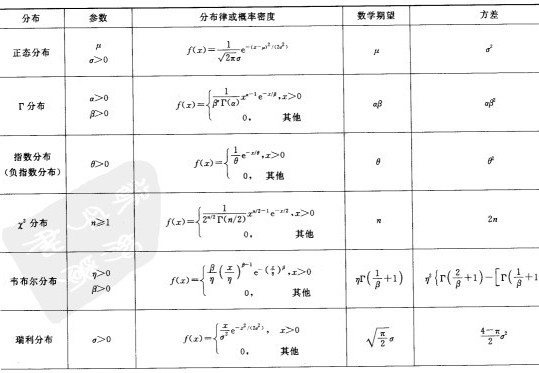
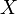 服从一个位置参数为
服从一个位置参数为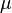 、尺度参数为
、尺度参数为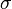 的概率分布,记为:
的概率分布,记为: 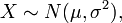
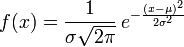
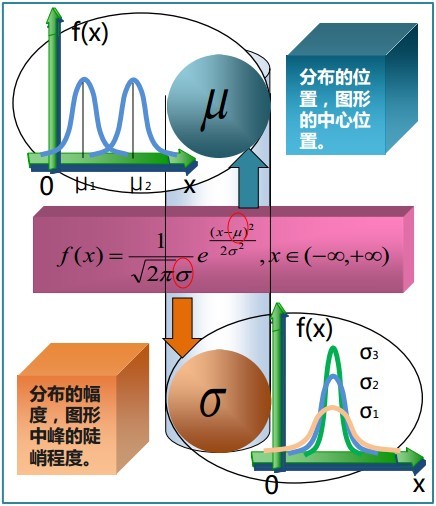
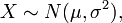 ,决定了分布的位置;其方差
,决定了分布的位置;其方差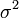 的开平方,即标准差等于尺度参数,决定了分布的幅度。正态分布的概率密度函数曲线呈钟形,因此人们又经常称之为钟形曲线。它有以下几点性质,如下图所示:
的开平方,即标准差等于尺度参数,决定了分布的幅度。正态分布的概率密度函数曲线呈钟形,因此人们又经常称之为钟形曲线。它有以下几点性质,如下图所示: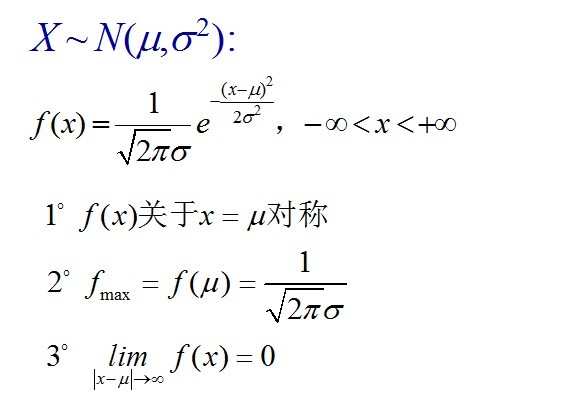
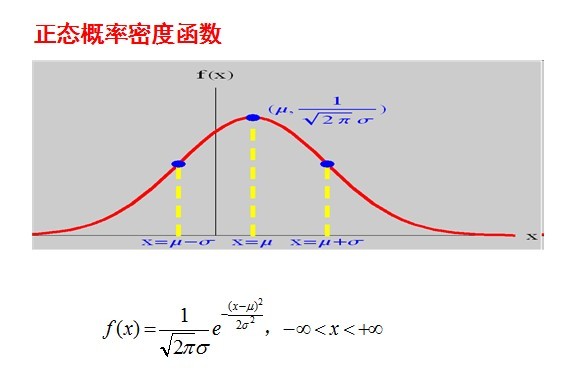 ,改变位置参数的大小时,f(x)图形的形状不变,只是沿着x轴作平移变换,如下图所示:
,改变位置参数的大小时,f(x)图形的形状不变,只是沿着x轴作平移变换,如下图所示: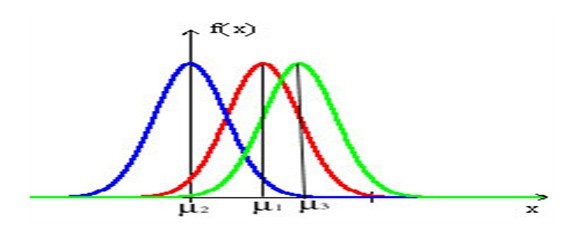 ,改变尺度参数的大小时,f(x)图形的对称轴不变,形状在改变,越小,图形越高越瘦,越大,图形越矮越胖。如下图所示:
,改变尺度参数的大小时,f(x)图形的对称轴不变,形状在改变,越小,图形越高越瘦,越大,图形越矮越胖。如下图所示: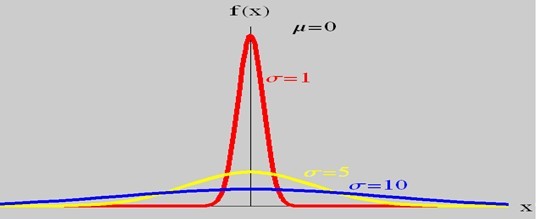
 , 尺度参数
, 尺度参数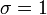 的正态分布,记为:
的正态分布,记为: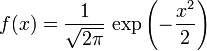
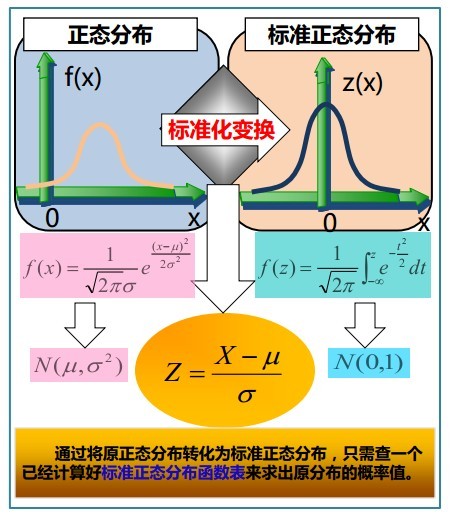
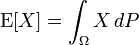
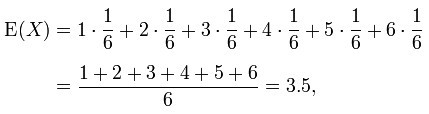
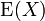 是随机变量X的期望值(平均数) 设
是随机变量X的期望值(平均数) 设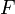
原文:https://www.cnblogs.com/aibabel/p/11006927.html