一、JDK JRE JVM 三者的区别
JDK(Java Development Kit): 是太阳微系统针对Java开发人员发布的免费软件开发工具包 是整个Java和音,包括了Java运行环境JRE(Java Runtime Environment),一堆Java工具(javac,Java,jdb等)和Java基础类库(即JavaAPI包括rt.jar)
JRE(Java Runtime Environment):JRE顾名思义是java运行时环境,包含了java虚拟机,java基础类库。是使用java语言编写的程序运行所需要的软件环境,是提供给想运行java程序的用户使用的。
JVM(java virtual machine):JVM是JAVA虚拟机,它将.class字节码文件编译成机器语言,以便机器识别! JAVA程序就是在JVM里运行的。
二、Java常见数据类型
1、引用型数据类型(四类八种)
1)整形数据类型
①byte(8位字节)取值范围-128~127
②short(16位字节)取值范围215-1~-215
③int(32位字节)取值范围231-1~-231
④long(64位字节)取值范围263-1~-263
2)浮点型数据类型
①float(32位字节)取值范围2-149~2128-1
②double(64位字节)取值范围2-1074~21024-1
3) 字符型数据类型
①char(8位字节)
4)布尔型数据类型
①boolean
三、运算符
1、i++与++i的区别
1)i++是先赋值后+ ++i是先+后赋值,举个栗子
int i=0,j=0;
System.out.println(i++);
System.out.println(++j);
显而易见,输出结果为1,2
i++是先进行输出然后再进行自增运算而++j是先进行自增运算再进行输出的
2、三目运算符
1)int i = 1>2?1:2;
三目运算符分为3部分1>2为第一部分 条件表达式1
1为第二部分 条件表达式2
2位第三部分 条件表达式3
三目运算符是由三个操作对象构成,一般结构为
条件表达式1?条件表达式2:条件表达式3
意思为当条件表达式1为true的情况下返回条件表达式2否则返回条件表达式3
2)/和%的用法及区别
①用法:都是数学运算符 都输双目运算符
②区别:/用于数字运算求商,就是单纯的数学运算符号。举个栗子:
System.out.println(15/5)输出结果为3
%用于求余数,一般用来判断X能否被Y整除
System.out.println(15%5)输出结果为0
3)逻辑判断 & 与&& 的区别 || 用法
①& &&的用法及区别,& 等同于and 和 并且,举个栗子:
int o=1;
if(o>1&&o++>0){
}
System.out.println(o);输出结果为1
if(o>1&o++>0){
}
System.out.println(o);输出结果为2
根据上面两个栗子不难得出结论:& 不管左边表达式时是否返回为true都会执行右边的表达式
&& 当左边的表达式返回为false时将不会执行右边的表达式
②| ||的用法和区别,| ||等同于或者 or,举个栗子:
int i=1;
if(0<i|1<(++i)){
System.out.println(i);
}
if(0<i||1<(++i)){
System.out.println(i);
}
根据上面的两个栗子不难得出结论:| 不管左边的表达式返回是否为true 都将执行右边的表达式
|| 当左边表达式返回为true时将不会执行右边的表达式
四、对象的加载过程,封装,继承(重写与重载的区别),多态,抽象类,接口,访问修饰符权限大小
1)对象的初始化过程:
①包含继承的子类初始化过程为:(父)静态对象(子)--非静态对象(父)--构造方法(父)--非静态对象(子)--构造方法(子)
。举个栗子:
测试类

父类
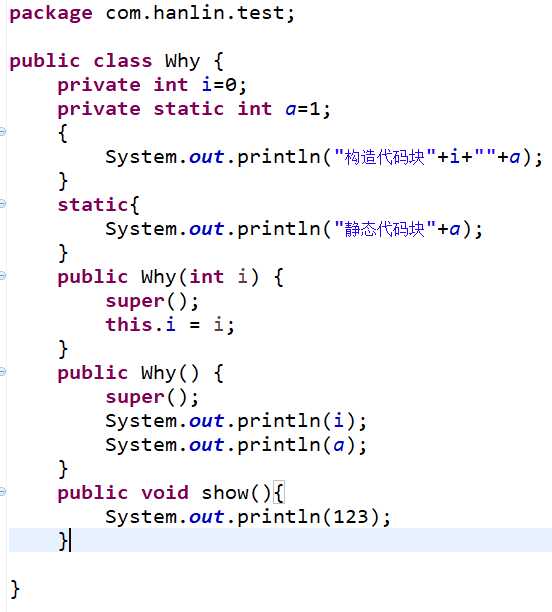
子类
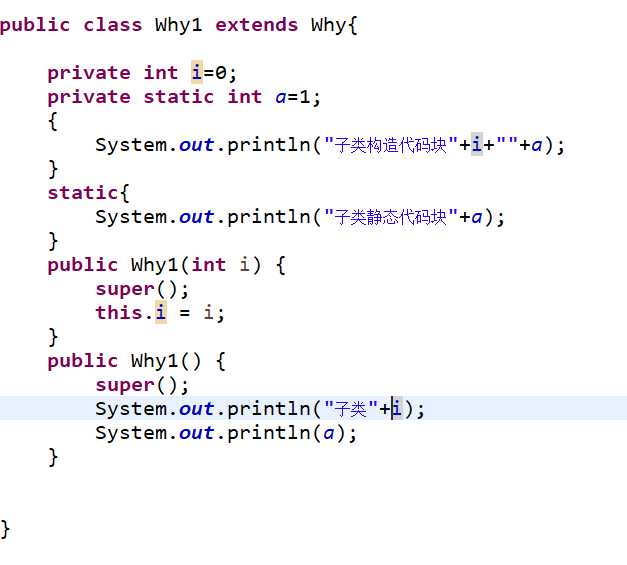
运行结果

从运行结果上可以看出:包含继承的子类初始化过程为:(父)静态对象(子)--非静态对象(父)--构造方法(父)--非静态对象(子)--构造方法(子)
②在不包含继承情况下对象的初始化过程是:静态对象--非静态对象--构造器
对象
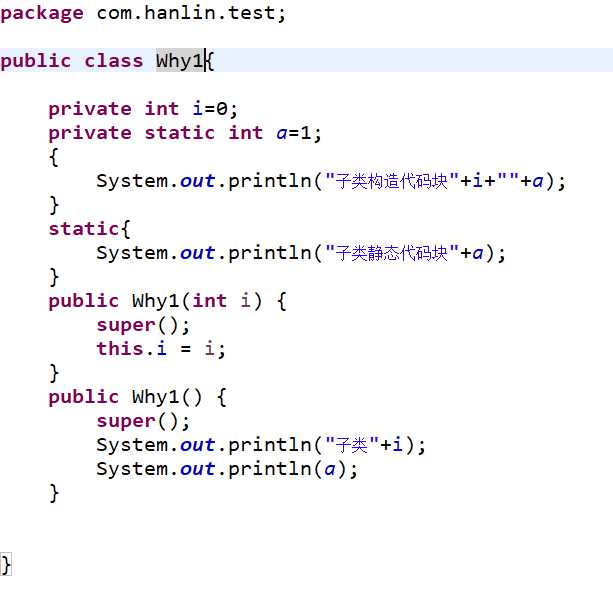
测试类

2)封装
封装:将属性或者方法私有化,设置公有的set get 方法;我个人理解就是将属性和方法统一提取到一个私密的空间里
然后给这个空间订上访问它的坐标,不能直接访问这些属性和方法,只能通过坐标来获取
3)继承
继承 是面向对象软件技术当中的一个概念,与多态、封装共为面向对象的三个基本特征。
继承可以使得子类具有父类的属性和方法或者重新定义、追加属性和方法等。
优点是:去除代码重复,提高代码复用性,便于维护。
在Java中类只支持单继承,接口支持多继承,接口不能被类继承,普通类继承抽象类得重写抽象类里边的所有抽象方法
4)抽象类
一个被abstract修饰的特殊的类,此类中可以有抽象方法和常量,也可以有非抽象方法和变量
抽象类不能被实例化,只能被继承
5)接口
一个被interface修饰的特殊的类,在此类中只允许有常量和抽象方法,在JDK1.8以后(包含1.8可以有普通方法和变量),
接口不能被实例化,只能被实现(implements)
实现一个接口就得重写它里边的所有抽象方法 接口支持多继承
6)访问修饰符权限大小
private(本类)<-default(本包)<-protected(不同包的子类)<-Public(公有)
private:私密的,故只能在本类中使用,封装就是将此类里所有的方法和属性的访问修饰符全部设定成private
default:默认的,在普通类中,默认的访问修饰符就是这个,它的访问权限仅仅比private大一级,仅限同一个包中使用
protected:这个访问修饰符又比default大一级,可以在不同包中访问,但前提是两者必须是继承关系
public:公开的,顾名思义,用这个访问修饰符修饰的所有属性和方法,在所有的类中都可以随意调用
五、数组的声明三种,如何遍历取值赋值 for循环执行顺序,选择排序,冒泡排序 Continue 与 break的区别 switch语句用法
1)数组的声明方式及遍历取值 赋值
①数组的三种创建方式,话不多说,上代码:
int []a=new int[6];
int[] b = {1,2,3};
int[] c=new int[]{1,2,3};
②数组的遍历取值方式共4种:
第一种,使用for循环,话不多说看代码:

第二种,使用while循环,继续放代码:

第三种,使用增强for循环,还是放代码:

第四种,使用do...while循环,最后一次放代码:
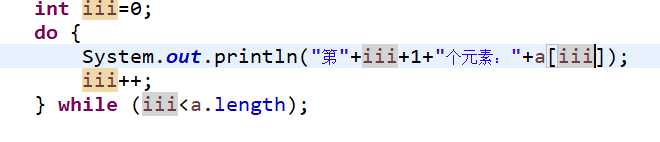
③数组的赋值
数组赋值可以在声明数组的时候就赋值,也可以通过下标赋值,上代码:
声明时赋值

运行结果

通过下标赋值
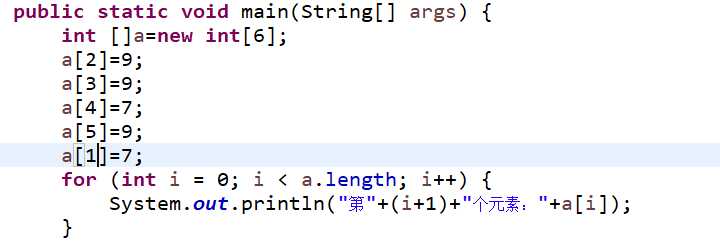
运行结果
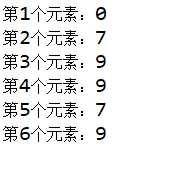
数组的下标是从0开始,0是第一个元素,如果没赋值的话它默认为0;
2)for循环的执行顺序
要知道for循环的执行顺序,首先得了解for循环总体分为几部分
for(初始化语句int i=0;条件语句i<20;迭代语句i++){
System.out.println("方法体")
}
如上所述,for循环总体分为4部分,1初始化语句,2条件语句,3迭代语句,4方法体
for循环刚开始第一次循环会首先执行初始化语句,也就是int i=0;然后执行条件判断语句 i<20,如果它返回false则不会进入下一步,
如果返回true则执行方法体System.out.println("方法体"),执行完方法体后,再执行迭代语句也就是1 2 4 3
当首次循环完毕之后进行第二次循环的时候将不会执行初始化语句,而是直接开始执行第二步,也就是条件语句,
返回true的情况下再执行方法体,然后继续迭代,直到条件语句返回为false为止;
3)选择排序
选择排序,顾名思义,有选择的进行排序,话不多说先看代码:
for (int i = 0; i < a.length-1; i++) {外层循环,确定的是要比较的次数
b=i;
for (int j = b+1; j < a.length; j++) {里层循环,将未比较的元素拿出来与外层循环的元素一一比较
if(a[b]>a[j]){判断两个元素的大小
b=j;记住值为小的一方的下标
}
}
if(b!=i){判断一次循环结束后值为小的下标是否为当前元素下标,如果是则跳过此段代码,如果不是则将当前元素与此次比较的最小元素进行更换位置
int c=a[i];
System.out.println(c);
a[i]=a[b];
a[b]=c;
}
}
上图: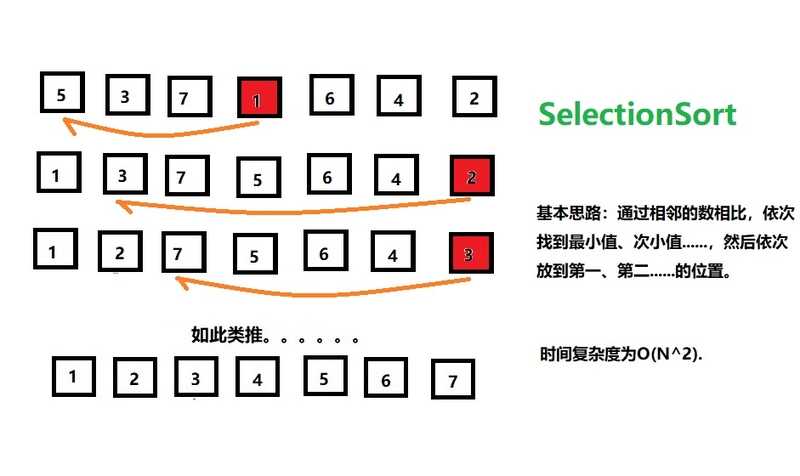
4)冒泡排序
冒泡排序:原理是每次比较两个相邻的元素,将较大的元素交换至右端。
思路拓展:每次冒泡排序操作都会将相邻的两个元素进行比较,看是否满足大小关系要求,如果不满足,就交换这两个相邻元素的次序,一次冒泡至少让一个元素移动到它应该排列的位置,重复N次,就完成了冒泡排序。
通过一个图来简单理解一下一次冒泡的过程【注意:图中每一竖列是一次比较交换】:

图中可以看出,经过一次冒泡,6这个当前数组中最大的元素飘到了最上面,如果进行N次这样操作,那么数组中所有元素也就到飘到了它本身该在的位置,就像水泡从水中飘上来,所以叫冒泡排序。
下图就是整个飘的过程:

以上,第五第六次可以看到,其实第五次冒泡的时候,数组已经是有序的了,因此,还可以优化,即如果当次冒泡操作没有数据交换时,那么就已经达到了有序状态
思路理清楚了那就上代码:
for (int i = 0; i <a.length-1; i++) {
for (int j = i+1; j < a.length-i-1; j++) {
System.out.println(a[i]+"---"+a[j]);
if(a[i]<a[j]){
b=a[i];
a[i]=a[j];
a[j]=b;
}
}
for (int i1 = 0; i1 < a.length; i1++) {
System.out.print(a[i1]+",");
}
}
通过代码的输出可以看出来,每次都是两个相林的数进行比较,如果外层循环的数小于里层循环的数则进行互换位置
这样第一轮比较出的结果就是最大的数换到了第一个,第二轮比较就开始从第二个数比较,第三轮是第三个数,直至结束;
5)Continue 与 break的区别 switch语句用法
①Continue与break的用法和区别:
Continue是跳出本次循环进行下一次循环,break是直接跳出,结束循环,看代码:

运行结果

break的运行结果
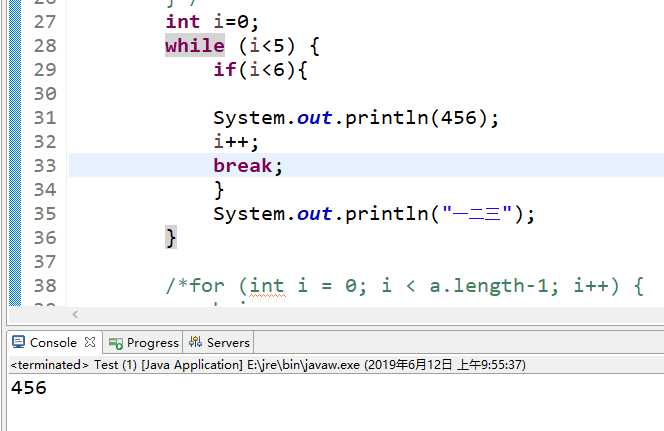
由上图可以看出不论是break还是Continue都具有跳出循环的功能,它们下面的输出语句都没执行,但是Continue的循环循环了5次,break只循环了一次。
由此可以得出结论,Continue具有跳出循环的功能,但是它只是跳出了本次循环,下一次循环还是会继续执行,直到循环结束。而break是直接结束了循环,让循环终止。
6)switch语句的用法
能用于switch判断的类型有:byte、short、int、char(JDK1.6),还有枚举类型,但是在JDK1.7后添加了对String类型的判断
case语句中少写了break,编译不会报错,但是会一直执行之后所有case条件下的语句而不再判断,直到default语句
若果没有符合条件的case就执行default下的代码块,default并不是必须的,也可以不写。废话不多说,看代码:
int i=0;
switch (i) {
case 0:
System.out.println(0);
break;
case 1:
System.out.println(1);
break;
default:
System.out.println("负数");
break;
}
switch只能判断相等。case语句后边一定要加break,不然一旦匹配到某个case之后,它后面的所有case都会默认执行,而不管是否匹配;
原文:https://www.cnblogs.com/wenhen/p/11006011.html