一、etl在bi中的作用
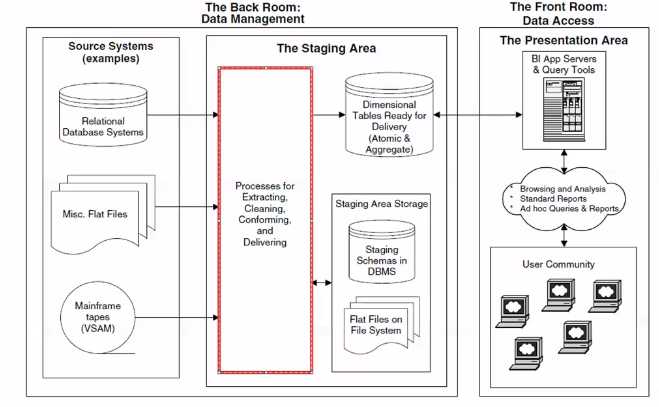
BI流程:
由数据后台例如数据库-----到数据缓冲区取出来-----数据集市-----给应用服务器提供数据------发布给用户
图中左边:为数据后台、业务系统、可能是数据库,从中抽出数据
中间:是etl的流程,抽到图中左下是数据缓冲区,左上是根据维度建好的多个数据集市。etl:描述将数据从来源端经过萃取(extract)、转置(transform)、加载(load)至目的端的过程。
右边:为数据前台,将应用服务器提供的数据发布给用户。
二、kettle的优点
1、流程式的设计方便易用
2、全面的数据访问支持
3、插件架构扩展性好
4、支持多平台.
三、构建一个简单的转换
在进行kettle流程之前,要先连接资源库,资源库包括:数据资源库和文件资源库。

这里我连接了数据资源库,工具-------资源库-------配置。
然后在左上角新建一个转换流程,kettle中主要包含转换和job两种作业方式。

做一个随机数生成---------然后过滤-----------输出到文本文件

生成的随机数都在0-1之间
右键随机数可以选择生成随机数的数量。
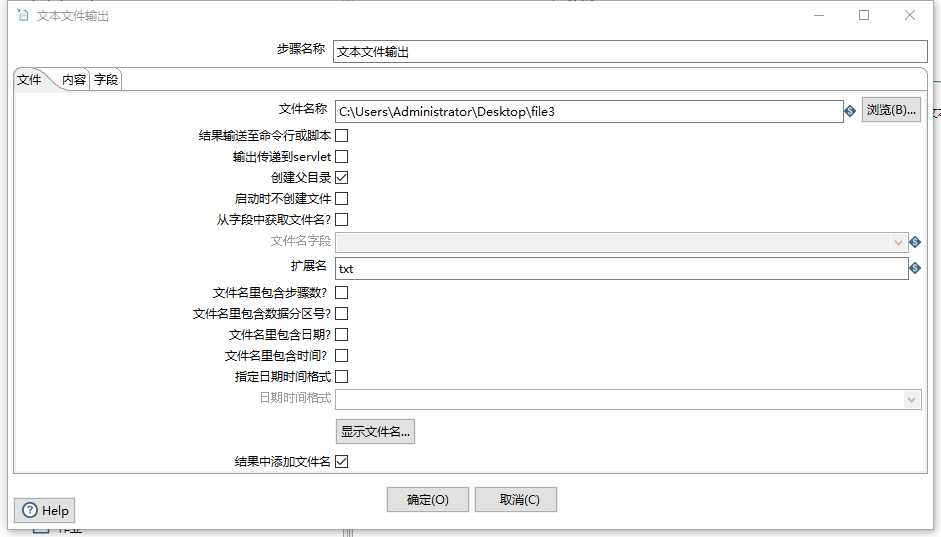
然后输出到桌面的文件中。
四、做一个由mysql写入pg的数据清洗写入流程。

表输入:从mysql中读取某表的数据并对数据进行清洗
SELECT id , ecode , outid , termid , cardsnr , opdt , colldt , rectype , ioflag , updateflag , updatedt , downdt , replace (replace(termname, ‘\0‘, ‘‘ ), ‘ ‘, ‘‘ ) AS termname , name FROM m_rec_kqmj WHERE substr(termname, 1, 1 ) IN ( ‘A‘, ‘B‘, ‘C‘, ‘D‘, ‘E‘, ‘F‘, ‘Y‘ )
表输出:将读取到的表写入到gp数据库中,在写入之前要在gp数据库中提前建好表。
表输入3:从mysql中读取另外一张表,这张表要与表输入中的表进行innerjoin,但此表不用写入到gp中。
记录集连接:根据字段选择连接方式,要提前对两表进行排序。
表输出2:将merge好的表写入gp数据库。
原文:https://www.cnblogs.com/languid/p/11024180.html