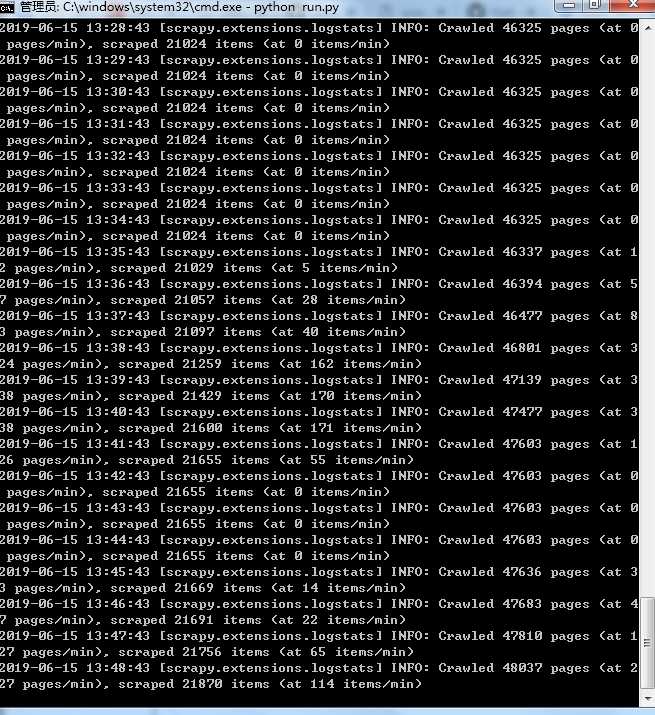
单机(不是分布式) 执行时间为晚上1点40多,运行到第二天1点48,大概12个小时,爬取了48037个网页
不过在运行过程中能看到有时候并没有进行爬取,而是卡住了
还有时候回出现一些错误,提取id和re的时候出现问题,没有发现该元素,预计是某些页面的格式不同,提取规则也不同,特别是hk页面(全球购)和图书页面以及彩票(这个要去除)
还要ip是个问题,由于是使用github上的轮子造的ip池,但是质量和数量也就那么一般,常规玩玩可以,大规模还是几台(目前还没掌握怎么弄0)adsl vps
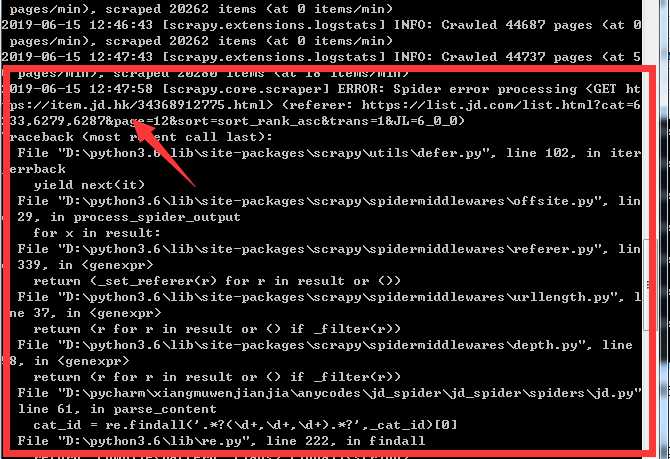
hk页面出现的问题是想要提取商品的catid,估摸是url或者xpath提取规则提取不到
原文:https://www.cnblogs.com/zengxm/p/11027399.html