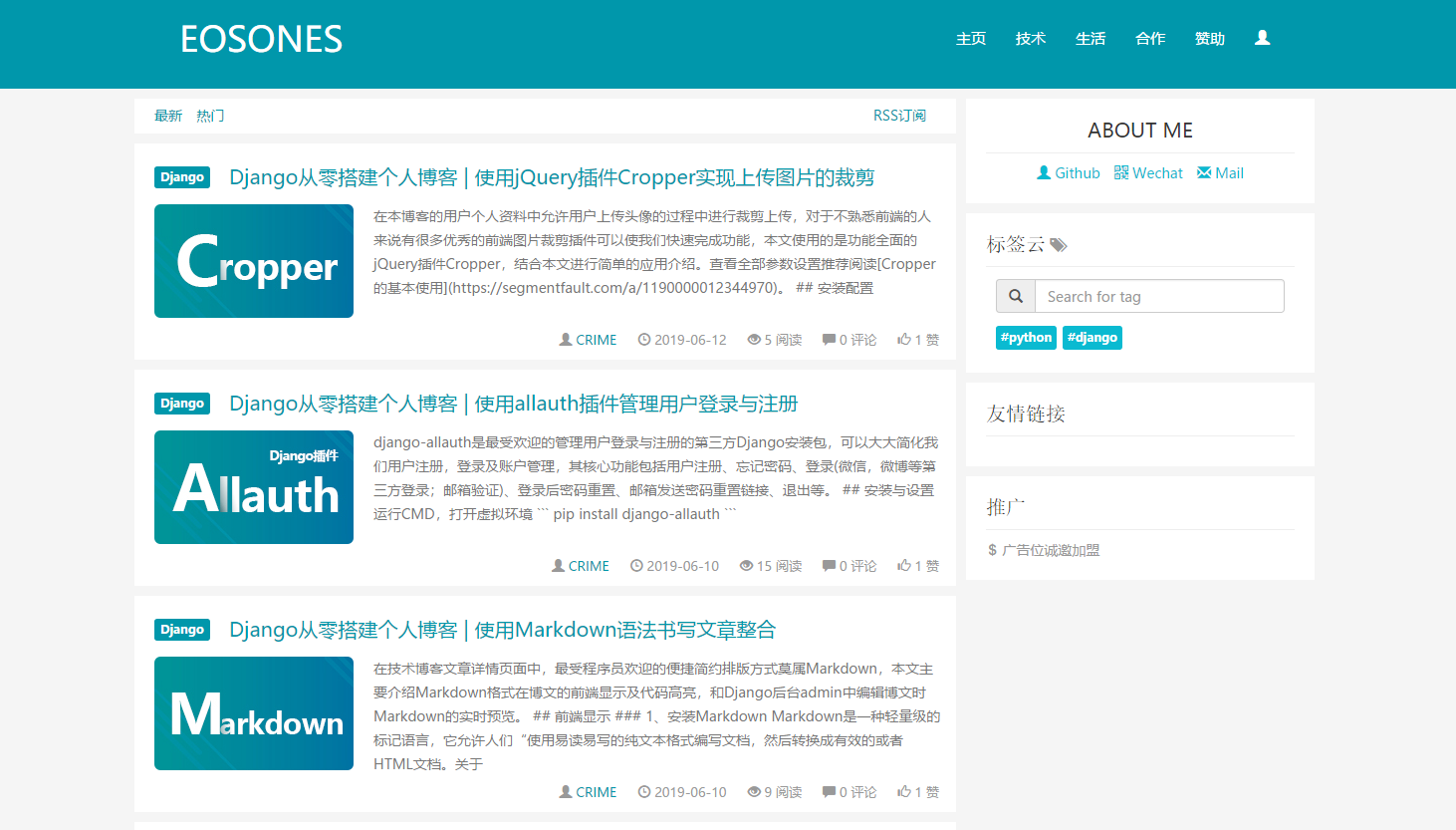
在整个博客的搭建中,文章相关的功能是最关键的,比如文章相关数据模型的设计、不同分类下文章的筛选显示、以及对显示功能完善的分页功能。本文针对本博客的文章主要功能通过这几方面进行介绍,参考全部代码请到Github查看。
在数据库设计之前,我们首先要确定网站功能,结合本站,最主要的是我们的博文表,名字可以直接叫做 article,其中包含博文的标题、内容、发表时间、修改时间、分类、标签、阅读量、喜欢量、作者、关键词等。博文表直接关联的有分类表(一对多)、标签表(多对多)和文章关键词表 (多对多),分类表是隶属在导航栏下,到此我们可以确定出这些最基本的数据表,博客(Article)、分类(Category)、标签(Tag)与文章关键词 (Keyword)、导航(Bigcategory)。
首先打开项目根目录,创建 Storm APP
python manage.py startapp Storm在 Myblog -> storm -> models.py 中首先设计导航表 (Bigcategory)与分类表(Category)。
from django.db import models
from django.conf import settings #引入定义字段SEO设置(提前设置)与自定义User(参考管理用户登录与注册博文)
from django.shortcuts import reverse #查找URL
import re
# 网站导航菜单栏表
class BigCategory(models.Model):
# 导航名称
name = models.CharField('导航大分类', max_length=20)
# 用作文章的访问路径,每篇文章有独一无二的标识
slug = models.SlugField(unique=True) #此字符串字段可以建立唯一索引
# 分类页描述
description = models.TextField('描述', max_length=240, default=settings.SITE_DESCRIPTION,help_text='用来作为SEO中description,长度参考SEO标准')
# 分类页Keywords
keywords = models.TextField('关键字', max_length=240, default=settings.SITE_KEYWORDS,help_text='用来作为SEO中keywords,长度参考SEO标准')
class Meta: #元信息
# admin中显示的表名称
verbose_name = '一级导航'
verbose_name_plural = verbose_name #复数形式相同
def __str__(self):
return self.name
# 导航菜单分类下的下拉菜单分类
class Category(models.Model):
# 分类名字
name = models.CharField('文章分类', max_length=20)
# 用作分类路径,独一无二
slug = models.SlugField(unique=True)
# 分类栏目页描述
description = models.TextField('描述', max_length=240, default=settings.SITE_DESCRIPTION,help_text='用来作为SEO中description,长度参考SEO标准')
# 导航菜单一对多二级菜单,django2.0后定义外键和一对一关系的时候需要加on_delete选项,此参数为了避免两个表里的数据不一致问题
bigcategory = models.ForeignKey(BigCategory,related_name="Category", on_delete=models.CASCADE,verbose_name='大分类')
class Meta:#元信息
# admin中显示的表名称
verbose_name = '二级导航'
verbose_name_plural = verbose_name
# 默认排序
ordering = ['name']
def __str__(self):
return self.name
#返回当前的url(一级分类+二级分类)
def get_absolute_url(self):
return reverse('blog:category', kwargs={'slug': self.slug, 'bigslug': self.bigcategory.slug}) #寻找路由为blog:category的url
#返回当前二级分类下所有发表的文章列表
def get_article_list(self):
return Article.objects.filter(category=self)标签(Tag)与关键字(Keyword)表的创建:
# 文章标签
class Tag(models.Model):
name = models.CharField('文章标签', max_length=20)
slug = models.SlugField(unique=True)
description = models.TextField('描述', max_length=240, default=settings.SITE_DESCRIPTION,help_text='用来作为SEO中description,长度参考SEO标准')
class Meta:
verbose_name = '标签'
verbose_name_plural = verbose_name
ordering = ['id']
def __str__(self):
return self.name
def get_absolute_url(self):
return reverse('blog:tag', kwargs={'tag': self.name})
def get_article_list(self):
#返回当前标签下所有发表的文章列表
return Article.objects.filter(tags=self)
# 文章关键词,用来作为 SEO 中 keywords
class Keyword(models.Model):
name = models.CharField('文章关键词', max_length=20)
class Meta:
verbose_name = '关键词'
verbose_name_plural = verbose_name
ordering = ['name']
def __str__(self):
return self.name博客(Article)表的创建:
from mdeditor.fields import MDTextField #admin markdown编辑器插件
import markdown #导入markdown
# 文章
class Article(models.Model):
# 文章默认缩略图
IMG_LINK = '/static/images/article/default.jpg'
# 文章信息(作者一对多注册用户,这样用户也可以有发文权限)
author = models.ForeignKey(settings.AUTH_USER_MODEL,on_delete=models.CASCADE, verbose_name='作者')
title = models.CharField(max_length=150, verbose_name='文章标题')
summary = models.TextField('文章摘要', max_length=230, default='文章摘要等同于网页description内容,请务必填写...')
# 文章内容(普通字段models.TextField(verbose_name='文章内容'))
body = MDTextField(verbose_name='文章内容')
#图片链接
img_link = models.CharField('图片地址', default=IMG_LINK, max_length=255)
#自动添加创建时间
create_date = models.DateTimeField(verbose_name='创建时间', auto_now_add=True)
#自动添加修改时间
update_date = models.DateTimeField(verbose_name='修改时间', auto_now=True)
#浏览点赞整数字段
views = models.IntegerField('阅览量', default=0)
loves = models.IntegerField('喜爱量', default=0)
# 文章唯一标识符
slug = models.SlugField(unique=True)
#分类一对多文章 #related_name反向查询
category = models.ForeignKey(Category,on_delete=models.CASCADE, verbose_name='文章分类')
#标签多对多文章
tags = models.ManyToManyField(Tag, verbose_name='标签')
#文章关键词多对多文章
keywords = models.ManyToManyField(Keyword, verbose_name='文章关键词',help_text='文章关键词,用来作为SEO中keywords,最好使用长尾词,3-4个足够')
class Meta:
verbose_name = '博文'
verbose_name_plural = verbose_name
ordering = ['-create_date']
def __str__(self):
return self.title[:20]
#返回当前文章的url
def get_absolute_url(self):
return reverse('blog:article', kwargs={'slug': self.slug})
#将内容markdown
def body_to_markdown(self):
return markdown.markdown(self.body, extensions=[
# 包含 缩写、表格等常用扩展
'markdown.extensions.extra',
# 语法高亮扩展
'markdown.extensions.codehilite',
# 自动生成目录扩展
'markdown.extensions.toc',
])
#点赞+1方法
def update_loves(self):
self.loves += 1
self.save(update_fields=['loves']) #更新字段
#浏览+1方法
def update_views(self):
self.views += 1
self.save(update_fields=['views']) #更新字段
#前篇方法:当前小于文章并倒序排列的第一个
def get_pre(self):
return Article.objects.filter(id__lt=self.id).order_by('-id').first()
#后篇方法:当前大于文章并正序排列的第一个
def get_next(self):
return Article.objects.filter(id__gt=self.id).order_by('id').first()其中模型中定义的一些方便给前端传递数据的方法,可以使用Django的自定义templatetags功能,前端引用模板语言可以达到同样效果并使用更自由。
在此之前先配置url
#Myblog/urls.py
from django.conf.urls import re_path,include
urlpatterns = [
...
# storm博客应用
re_path(r'^',include('Storm.urls', namespace='blog')),
...
]#Myblog/Storm/urls.py
from django.urls import path
from django.conf.urls import re_path
from Storm import views
app_name='Storm'
urlpatterns = [
...
#一级二级菜单分类文章列表
#django 2.x中用re_path兼容1.x中的url中的方法(如正则表达式)
re_path(r'category/(?P<bigslug>.*?)/(?P<slug>.*?)/',views.CtegoryView.as_view(),name='category'),#?分隔实际的URL和参数,?p数据库里面唯一索引 & URL中指定的参数间的分隔符
re_path(r'category/(?P<bigslug>.*?)/',views.CtegoryView.as_view(),name='category'),
# 标签搜索文章列表
re_path(r'tags/(?P<tagslug>.*?)/', views.CtegoryView.as_view(),name='tag'),
...
]网站前端功能中,可以进行筛选文章列表显示的途径有:通过一级导航、二级分类、标签以及自定义一级导航下的最新与最热筛选,我们通过url传参进行视图分别的处理。
一般的,视图函数从数据库中获取文章列表数据:
def index(request):
# ...
def archives(request, year, month):
# ...
def category(request, pk):
# ...在Django中专门提供了各种功能的处理类来使我们快捷的处理数据,其中ListView视图帮我们内部做这些查询等操作,只需将 model 指定为 Article,告诉 Django 我要获取的模型是 Article。template_name 指定这个视图渲染的模板。context_object_name 指定获取的模型列表数据保存的变量名。这个变量会被传递给模板。 paginate_by 通过指定属性即可开启分页功能。
from django.shortcuts import render,get_object_or_404
from Storm import models
#从数据库中获取某个模型列表数据基类ListView
from django.views.generic import ListView
#Django自带的分页模块
from django.core.paginator import Paginator
#分类查找文章列表视图类
class CtegoryView(ListView):
model=models.Article
template_name = 'articleList.html'
context_object_name = 'articleList'
paginate_by = 8 由于针对不同url进行文章筛选的方式不同,所以我们通过覆写了父类的 get_queryset 方法获取定制文章列表数据,通过覆写def get_context_data方法来获取定制的分页效果,其中调用了自定义方法 pagination_data 获得显示分页导航条需要的数据。
#分类查询文章与视图类
class CtegoryView(ListView):
model=models.Article
template_name = 'articleList.html'
context_object_name = 'articleList'
paginate_by = 8 #指定 paginate_by 属性来开启分页功能
#覆写了父类的 get_queryset 方法获取定制数据
#类视图中,从 URL 捕获的命名组参数值保存在实例的 kwargs 属性(是一个字典)里,非命名组参数值保存在实例的 args 属性(是一个列表)里
def get_queryset(self):
#get_queryset方法获得全部文章列表
queryset = super(CtegoryView, self).get_queryset()
# 导航菜单
big_slug = self.kwargs.get('bigslug', '')
# 二级菜单
slug = self.kwargs.get('slug', '')
# 标签
tag_slug = self.kwargs.get('tagslug', '')
if big_slug:
big = get_object_or_404(models.BigCategory, slug=big_slug)
queryset = queryset.filter(category__bigcategory=big)
if slug:
if slug=='newest':
queryset = queryset.filter(category__bigcategory=big).order_by('-create_date')
elif slug=='hottest':
queryset = queryset.filter(category__bigcategory=big).order_by('-loves')
else :
slu = get_object_or_404(models.Category, slug=slug)
queryset = queryset.filter(category=slu)
if tag_slug:
tlu = get_object_or_404(models.Tag, slug=tag_slug)
queryset = queryset.filter(tags=tlu)
return queryset
#在视图函数中将模板变量传递给模板是通过给 render 函数的 context 参数传递一个字典实现的
def get_context_data(self, **kwargs):
# 首先获得父类生成的传递给模板的字典。
context = super().get_context_data(**kwargs)
paginator = context.get('paginator')
page = context.get('page_obj')
is_paginated = context.get('is_paginated')
# 调用自己写的 pagination_data 方法获得显示分页导航条需要的数据,见下方。
pagination_data = self.pagination_data(paginator, page, is_paginated)
# 将分页导航条的模板变量更新到 context 中,注意 pagination_data 方法返回的也是一个字典。
context.update(pagination_data)
return context
def pagination_data(self, paginator, page, is_paginated):
if not is_paginated:# 如果没有分页,则无需显示分页导航条,不用任何分页导航条的数据,因此返回一个空的字典
return {}
# 当前页左边连续的页码号,初始值为空
left = []
# 当前页右边连续的页码号,初始值为空
right = []
# 标示第 1 页页码后是否需要显示省略号
left_has_more = False
# 标示最后一页页码前是否需要显示省略号
right_has_more = False
# 标示是否需要显示第 1 页的页码号。
first = False
# 标示是否需要显示最后一页的页码号
last = False
# 获得用户当前请求的页码号
page_number = page.number
# 获得分页后的总页数
total_pages = paginator.num_pages
# 获得整个分页页码列表,比如分了四页,那么就是 [1, 2, 3, 4]
page_range = paginator.page_range
#请求的是第一页的数据
if page_number == 1:
#获取了当前页码后连续两个页码
right = page_range[page_number:(page_number + 2) if (page_number + 2) < paginator.num_pages else paginator.num_pages]
# 如果最右边的页码号比最后一页的页码号减去 1 还要小,
# 说明最右边的页码号和最后一页的页码号之间还有其它页码,因此需要显示省略号,通过 right_has_more 来指示。
if right[-1] < total_pages - 1:
right_has_more = True
# 如果最右边的页码号比最后一页的页码号小,说明当前页右边的连续页码号中不包含最后一页的页码
# 所以需要显示最后一页的页码号,通过 last 来指示
if right[-1] < total_pages:
last = True
# 如果用户请求的是最后一页的数据,
elif page_number == total_pages:
#获取了当前页码前连续两个页码
left = page_range[(page_number - 3) if (page_number - 3) > 0 else 0:page_number - 1]
# 如果最左边的页码号比第 2 页页码号还大,
# 说明最左边的页码号和第 1 页的页码号之间还有其它页码,因此需要显示省略号,通过 left_has_more 来指示。
if left[0] > 2:
left_has_more = True
# 如果最左边的页码号比第 1 页的页码号大,说明当前页左边的连续页码号中不包含第一页的页码,
# 所以需要显示第一页的页码号,通过 first 来指示
if left[0] > 1:
first = True
else:
# 用户请求的既不是最后一页,也不是第 1 页,则需要获取当前页左右两边的连续页码号,
# 这里只获取了当前页码前后连续两个页码,你可以更改这个数字以获取更多页码。
left = page_range[(page_number - 3) if (page_number - 3) > 0 else 0:page_number - 1]
right = page_range[page_number:(page_number + 2) if (page_number + 2) < paginator.num_pages else paginator.num_pages]
# 是否需要显示最后一页和最后一页前的省略号
if right[-1] < total_pages - 1:
right_has_more = True
if right[-1] < total_pages:
last = True
# 是否需要显示第 1 页和第 1 页后的省略号
if left[0] > 2:
left_has_more = True
if left[0] > 1:
first = True
data = {
'left': left,
'right': right,
'left_has_more': left_has_more,
'right_has_more': right_has_more,
'first': first,
'last': last,
}
return data通过视图类处理后的文章数据 articleList 在前端中用Django的模板语言可以直接引用,前端模板根据需求进行自定义。
{% for article in articleList %}
{{article.category.name}}
{{article.title}}
...
{{article.create_date | date:"Y-m-j"}}<
{{article.loves}}
{% endfor %}分页传来的数据中,除了我们自定义的 data 数据,还自带了paginator:Paginator 的实例,page_obj:当前请求页面分页对象,is_paginated:是否开启分页,其中page_obj具有当前页属性page_obj.number、判断是否含有上一页:page_obj.has_previous,是否含有下一页:page_obj.has_next。注意我们在这里用了Bootstrap的分页模板,需要在开头引入相关文件。

{% if is_paginated %}
<div class="PageList">
<nav aria-label="Page navigation">
<ul class="pagination pagination-sm">
<li class="{% if not page_obj.has_previous %} disabled {% endif %}">
<a href="{% if page_obj.has_previous %} ?page={{ page_obj.previous_page_number }} {% endif %}" aria-label="Previous">
<span aria-hidden="true">«</span>
</a>
</li>
{% if first %}
<li>
<a href="?page=1">1</a>
</li>
{% endif %}
{% if left %}
{% if left_has_more %}
<li>
<span>...</span>
</li>
{% endif %}
{% for i in left %}
<li>
<a href="?page={{ i }}">{{ i }}</a>
</li>
{% endfor %}
{% endif %}
<li class="active"><a href="?page={{ page_obj.number }}">{{ page_obj.number }}</a></li>
{% if right %}
{% for i in right %}
<li>
<a href="?page={{ i }}">{{ i }}</a>
</li>
{% endfor %}
{% if right_has_more %}
<li>
<span>...</span>
</li>
{% endif %}
{% endif %}
{% if last %}
<li>
<a href="?page={{ paginator.num_pages }}">{{ paginator.num_pages }}</a>
</li>
{% endif %}
<li class="{% if not page_obj.has_next %} disabled {% endif %}">
<a href="{% if page_obj.has_next %} ?page={{ page_obj.next_page_number }} {% endif %}" aria-label="Next">
<span aria-hidden="true">»</span>
</a>
</li>
</ul>
</nav>
</div>参考:追梦任务 | Django Pagination分页功能
原文:https://www.cnblogs.com/crime/p/11027968.html