首先创建一个command.job文件
#command.job type=command command=echo it18zhang
然后打成zip压缩包
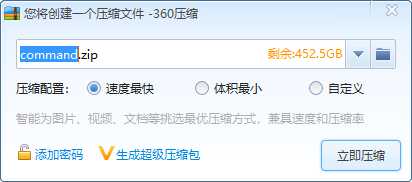
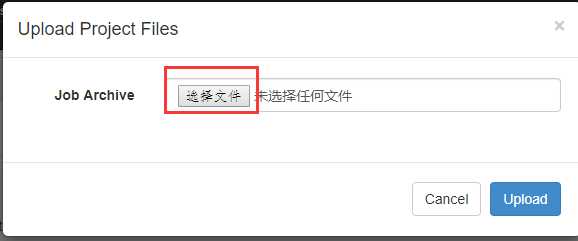
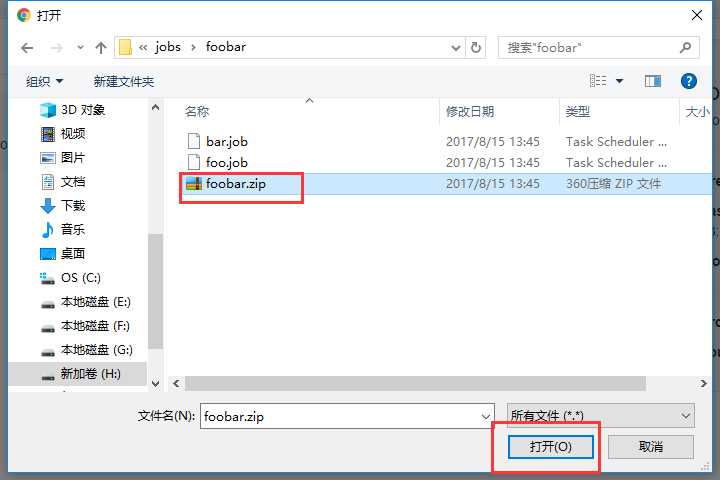
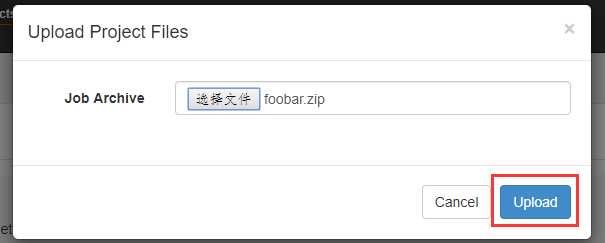
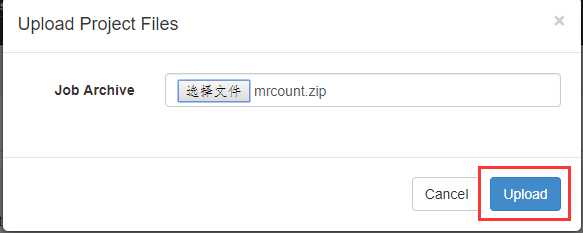
上传刚刚打包的zip包
上传完后可以执行他
可以定时执行
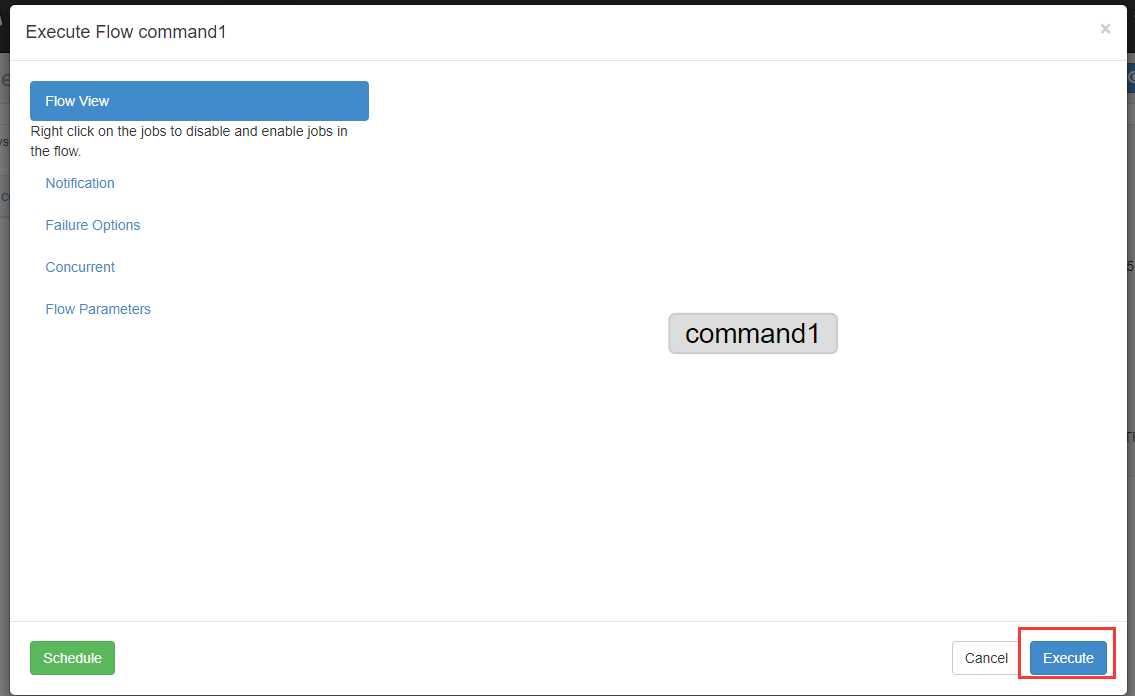
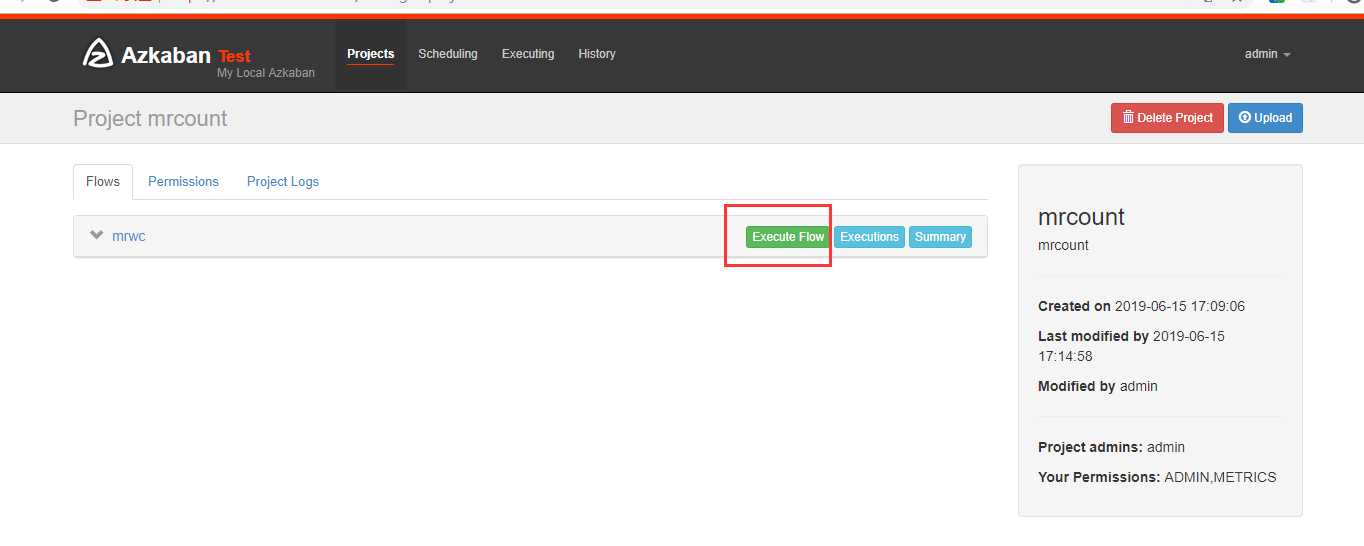
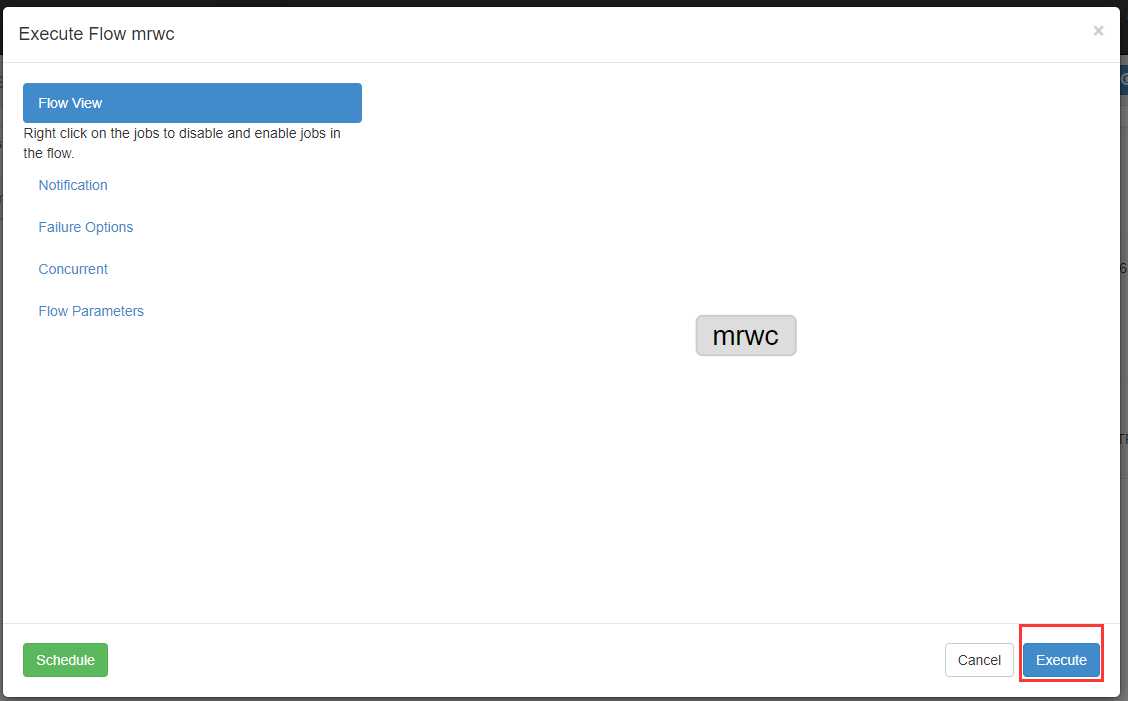
现在我们立马执行
现在我们要执行一个脚本
新建一个commad1.job文件
#command.job type=command command=bash hello.sh
再编写一个hello,sh脚本
#!/bin/bash echo ‘hello it18zhang~~~~‘
把两个文件都选上一起打包
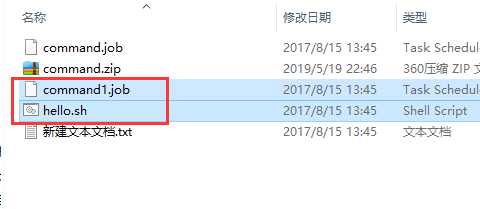


上传刚刚打的zip包
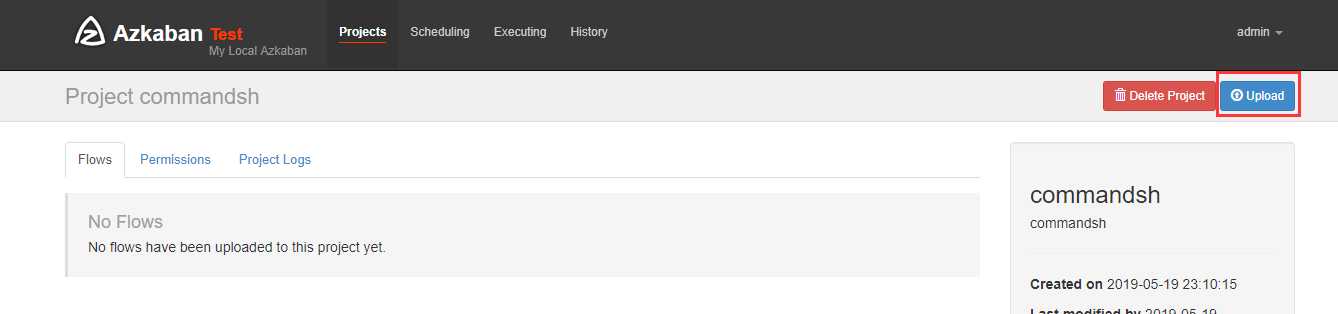
执行

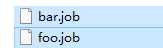
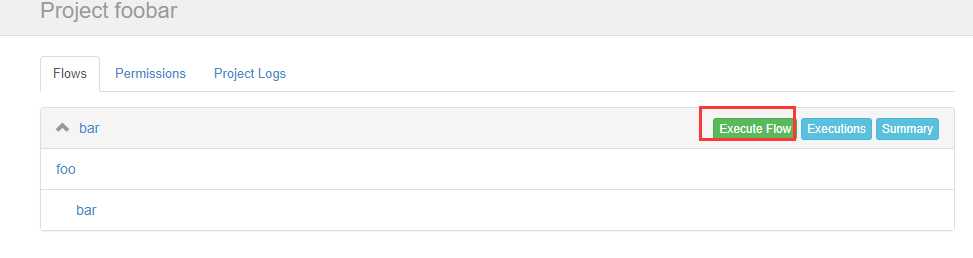
创建有依赖关系的多个job描述
新建一个bar.job
# bar.job type=command dependencies=foo command=echo bar
新建一个foo.job
# foo.job type=command command=echo foo
把这两个文件一起打成zip包
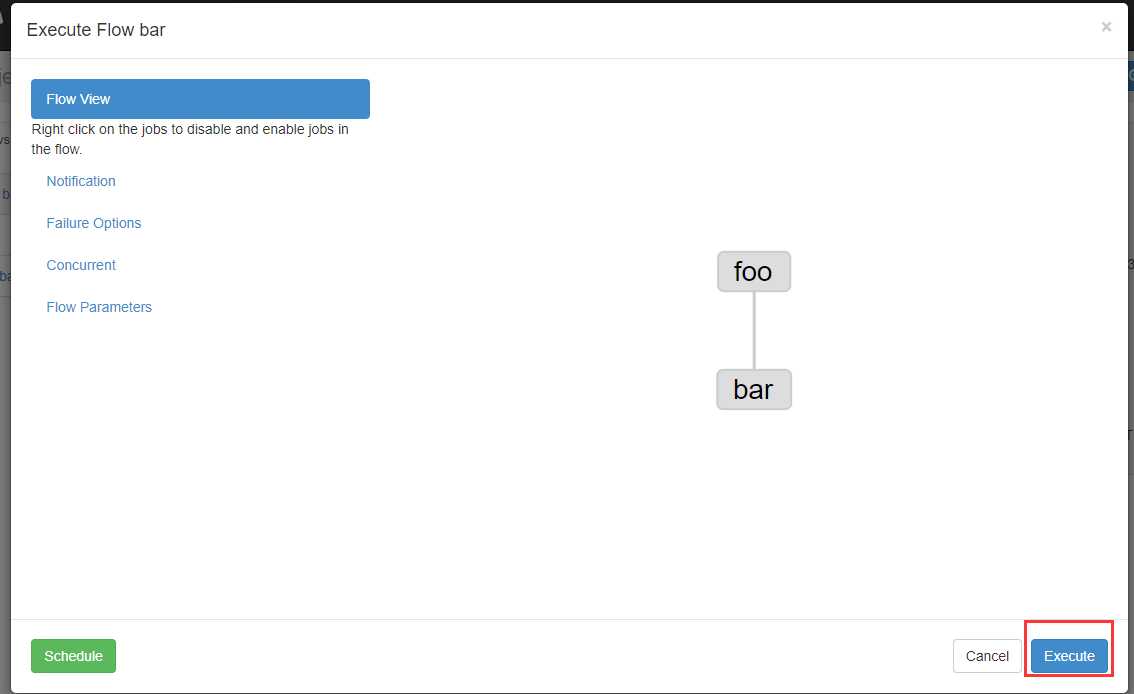

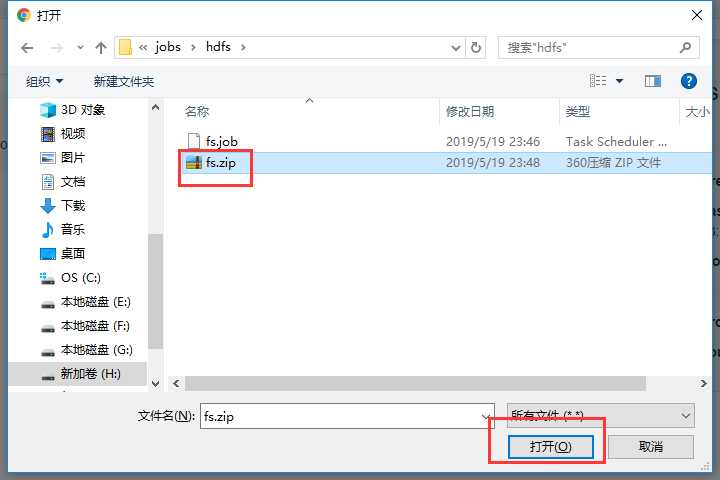
新建文件fs.job
# fs.job type=command command=/opt/modules/hadoop-2.6.0/bin/hadoop fs -mkdir /azaz
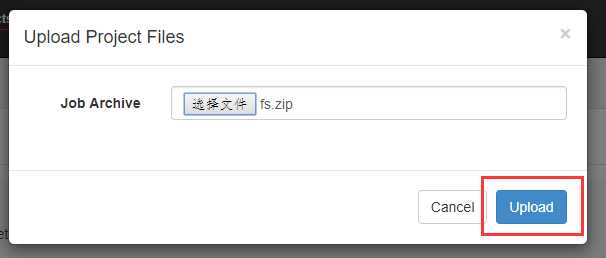
打包成zip包


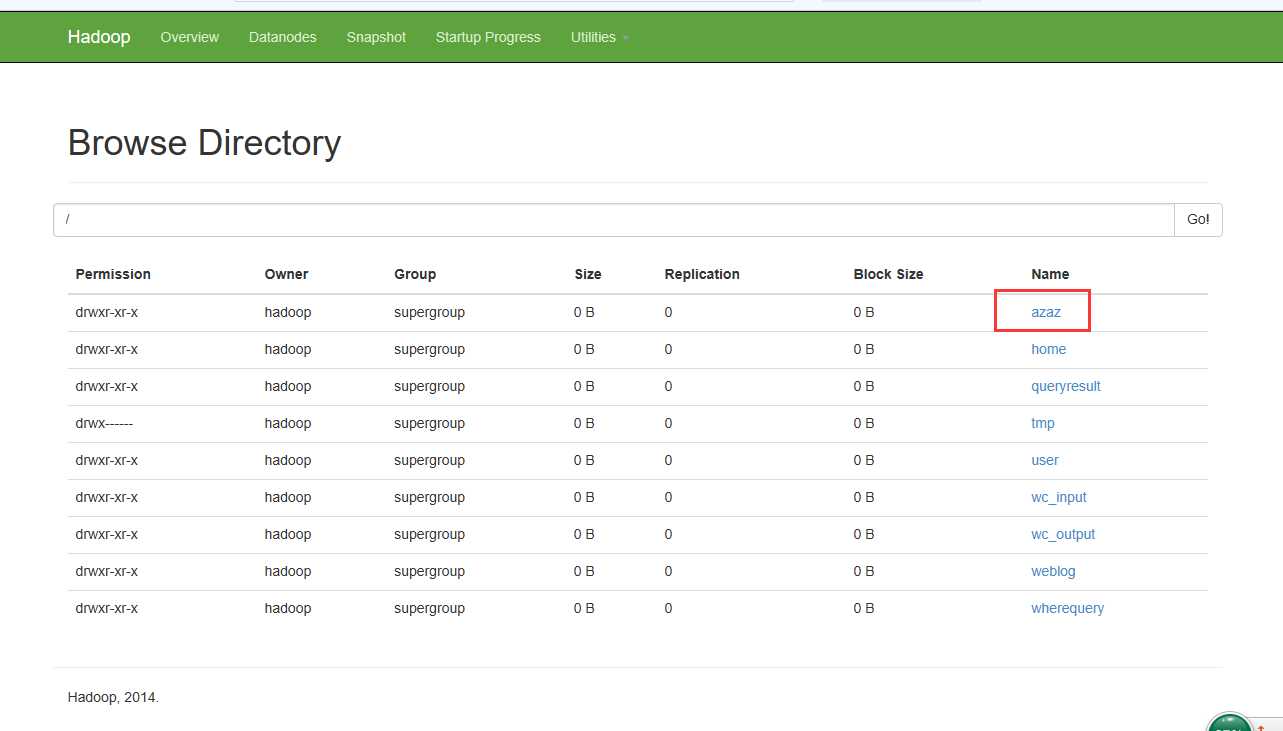
先创建一个输入路径

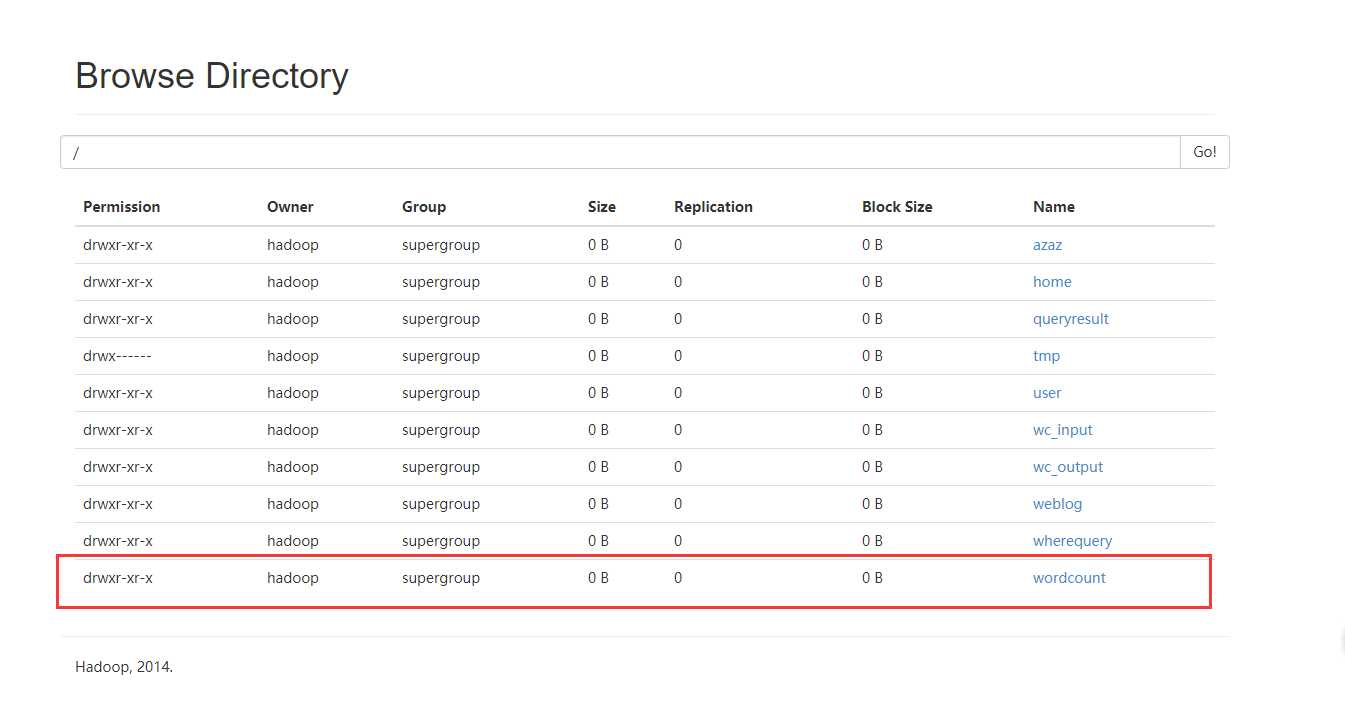
创建一个数据文件b.txt

输入一些单词
把b.txt文件上传到hdfs上

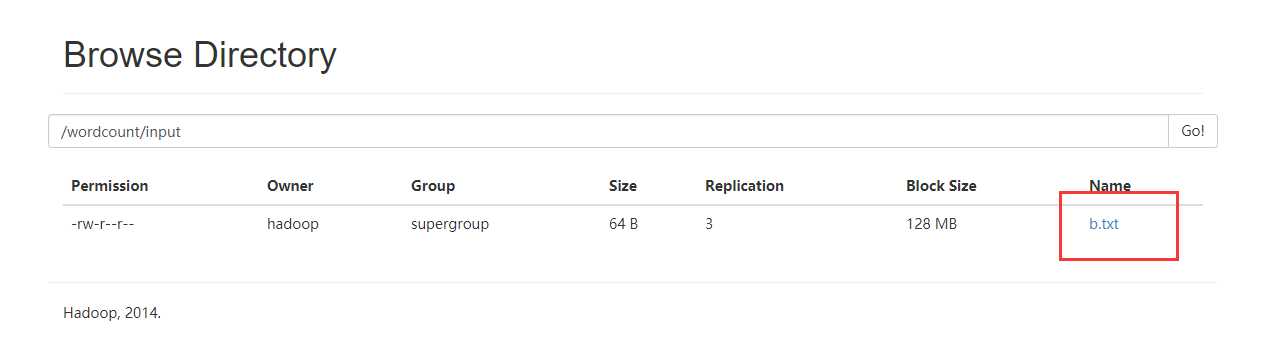
创建mrwc.job文件
# mrwc.job type=command command=/opt/modules/hadoop-2.6.0/bin/hadoop jar hadoop-mapreduce-examples-2.6.0.jar wordcount /wordcount/input /wordcount/azout
把这两个文件一起打包
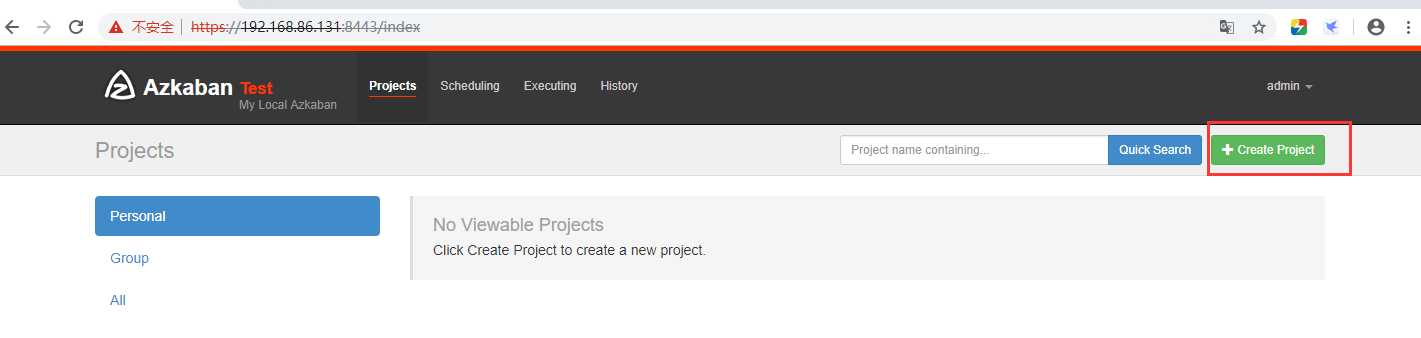
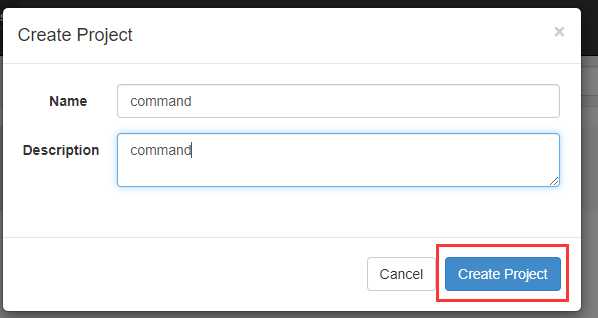
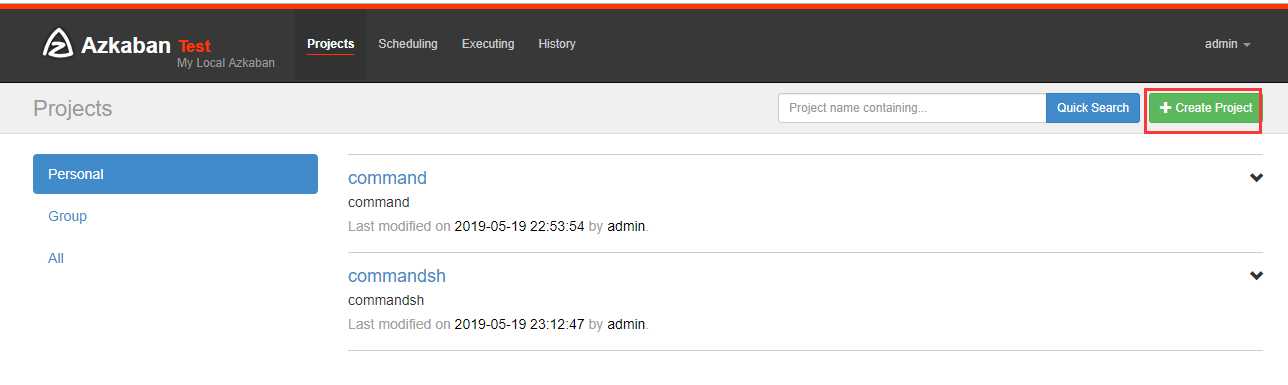
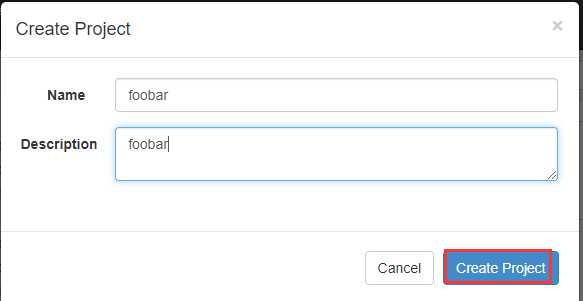
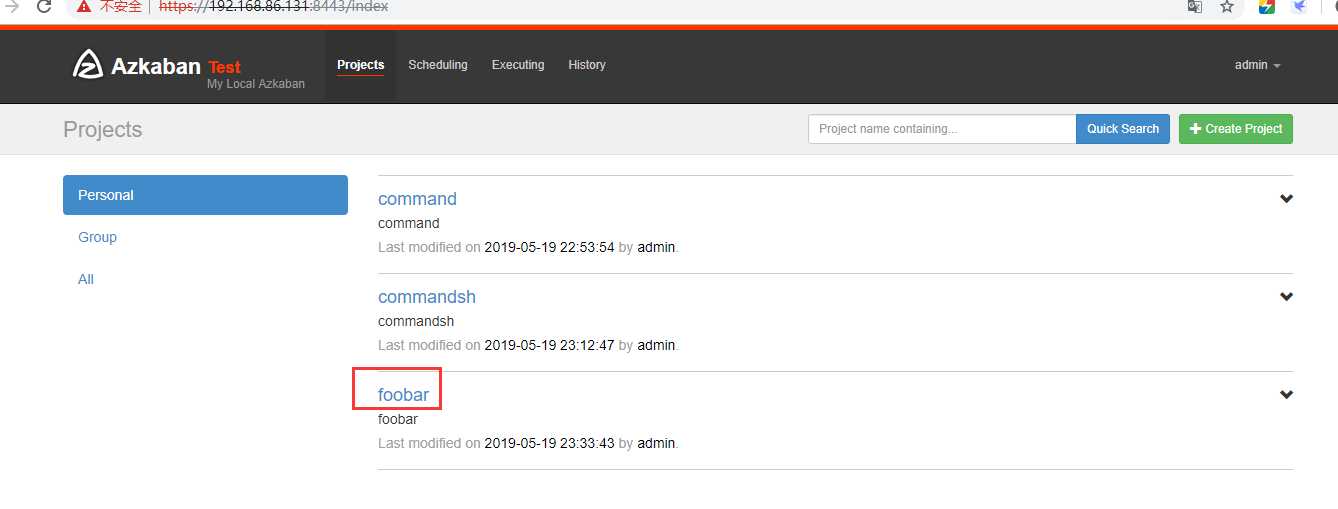
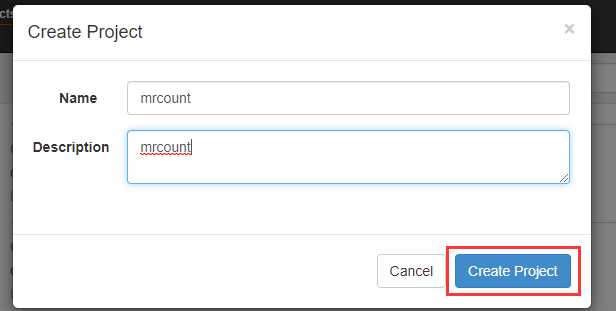
在azkaban创建一个project
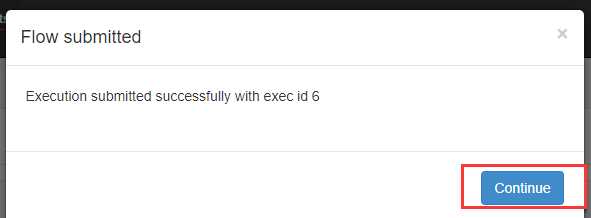
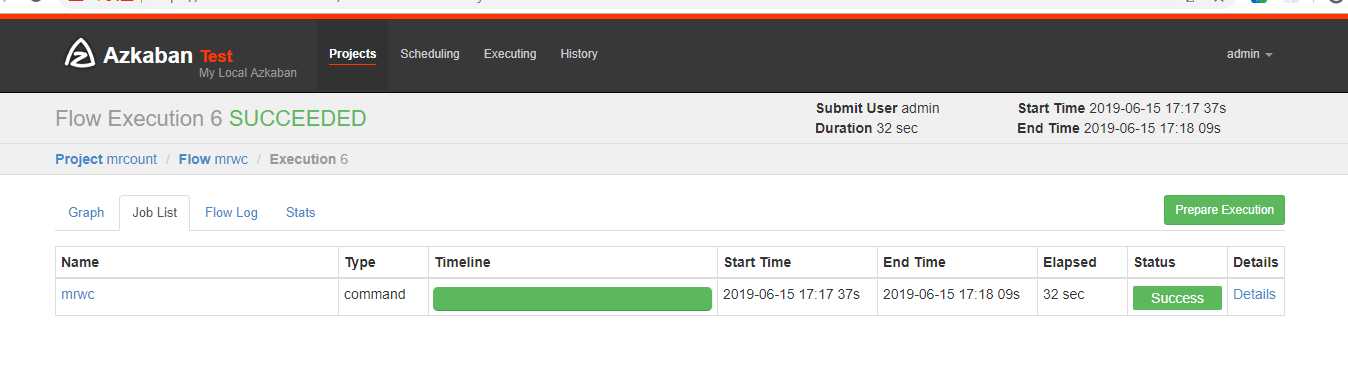
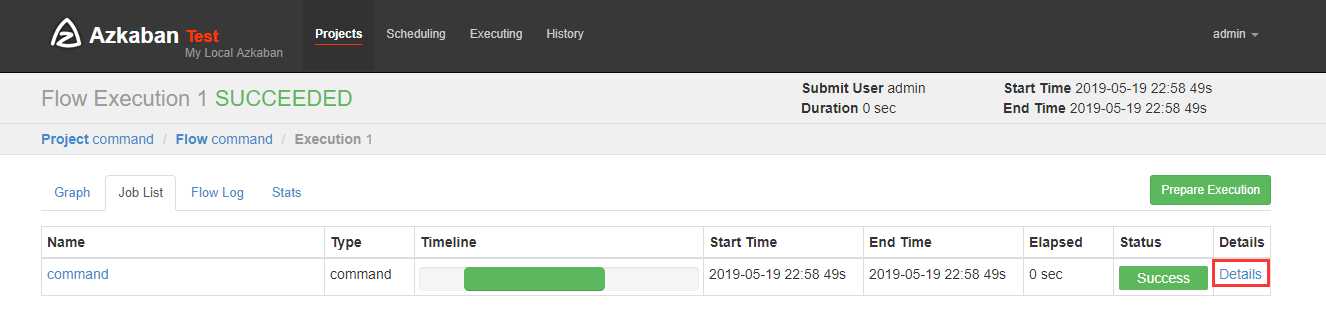
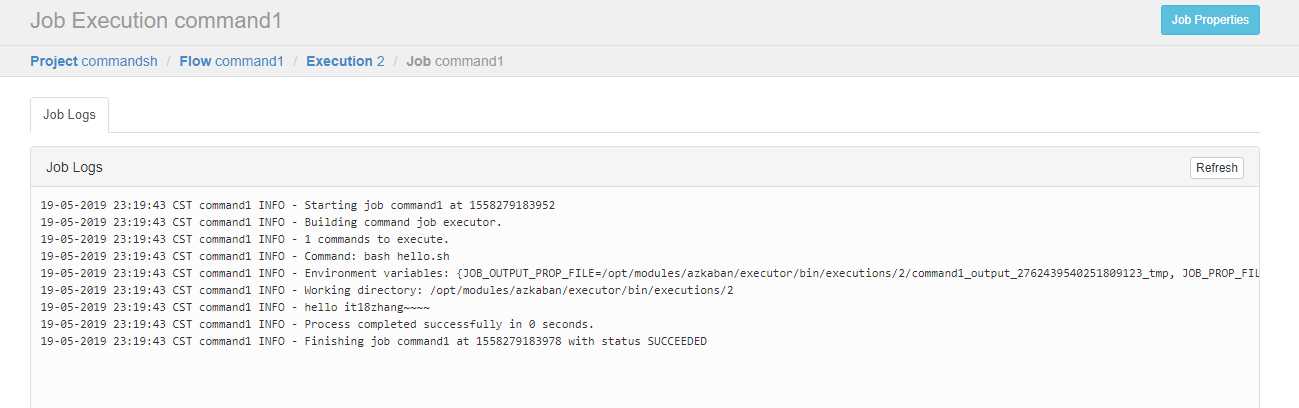
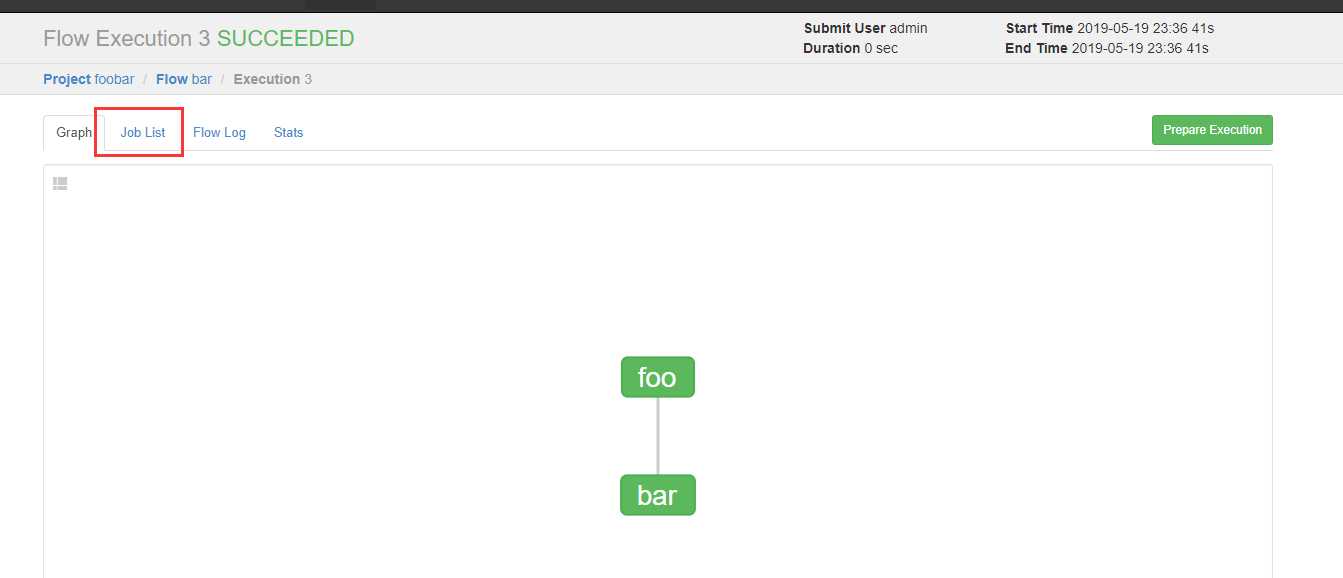
可以看到执行成功了
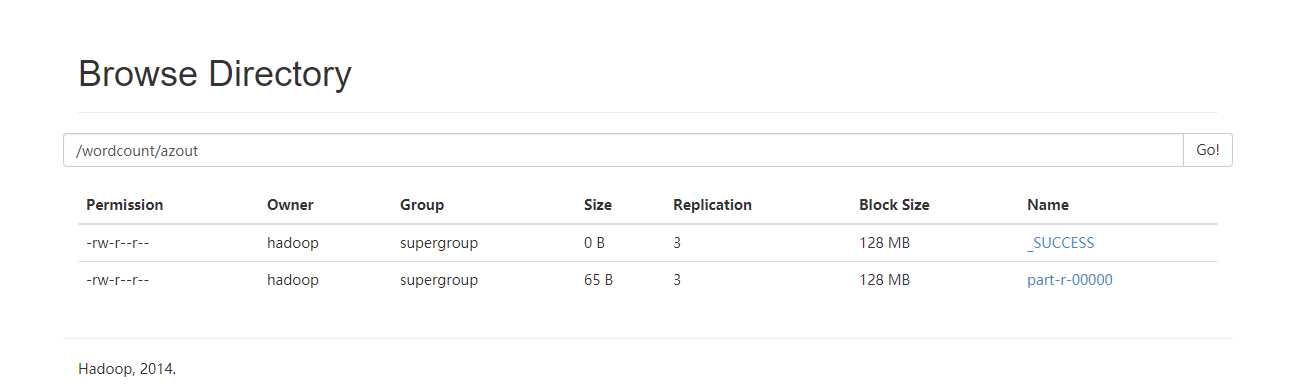
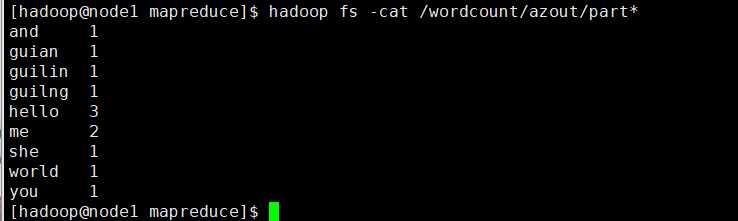
先创建目录
hadoop fs -mkdir -p /aztest/hiveinput
新建一个c.txt数据文件

把c.txt文件上传到HDFS上

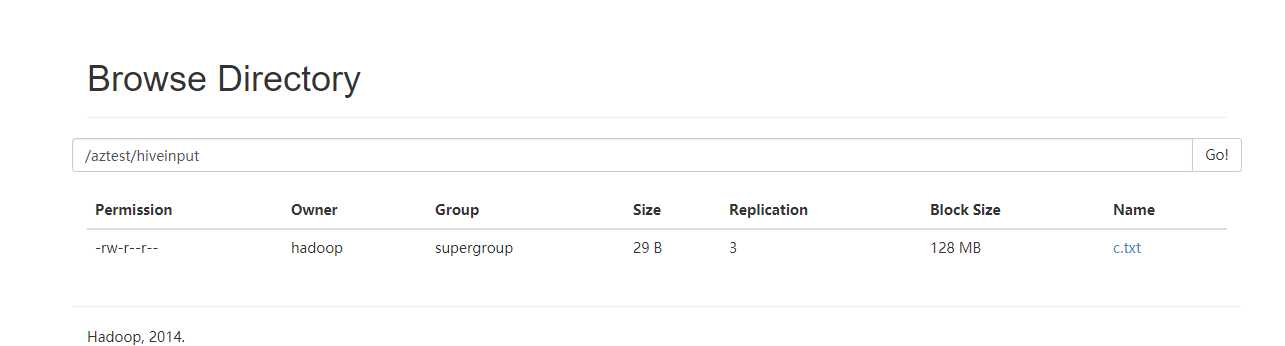
新建hivef.job
# hivef.job type=command command=/opt/modules/hive/bin/hive -f ‘test.sql‘
新建test.sql
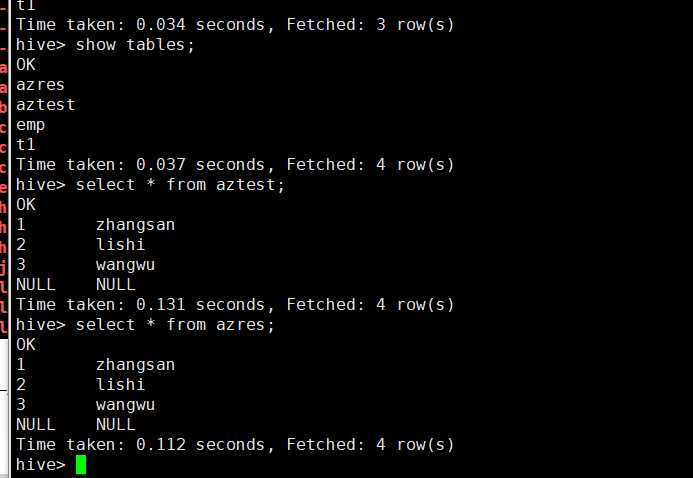
use default; drop table aztest; create table aztest(id int,name string) row format delimited fields terminated by ‘,‘ ; load data inpath ‘/aztest/hiveinput‘ into table aztest; create table azres as select * from aztest; insert overwrite directory ‘/aztest/hiveoutput‘ select count(1) from aztest;
打包成hivef.zip

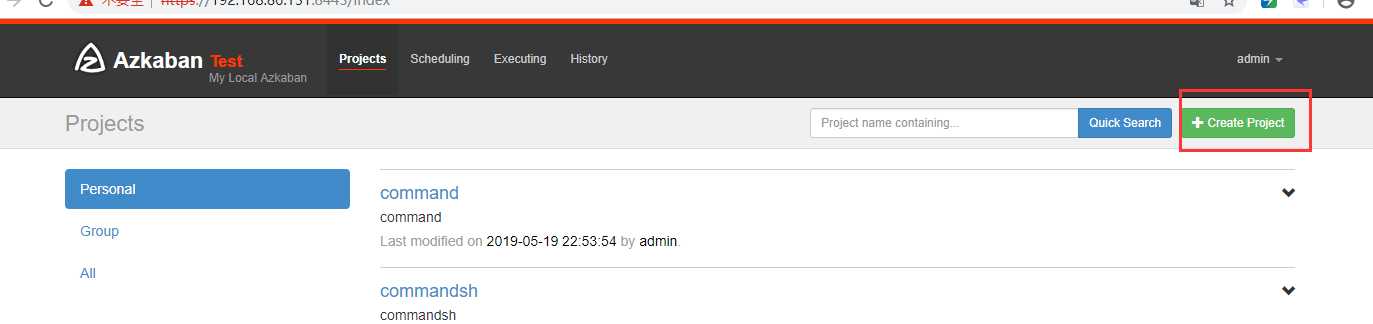
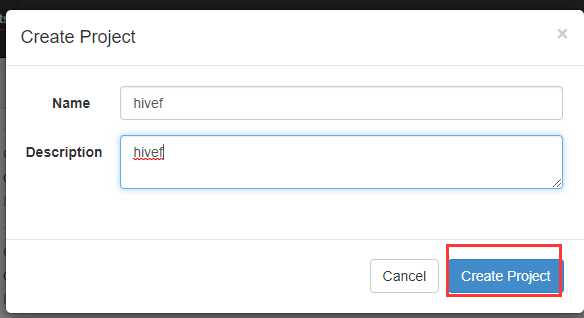
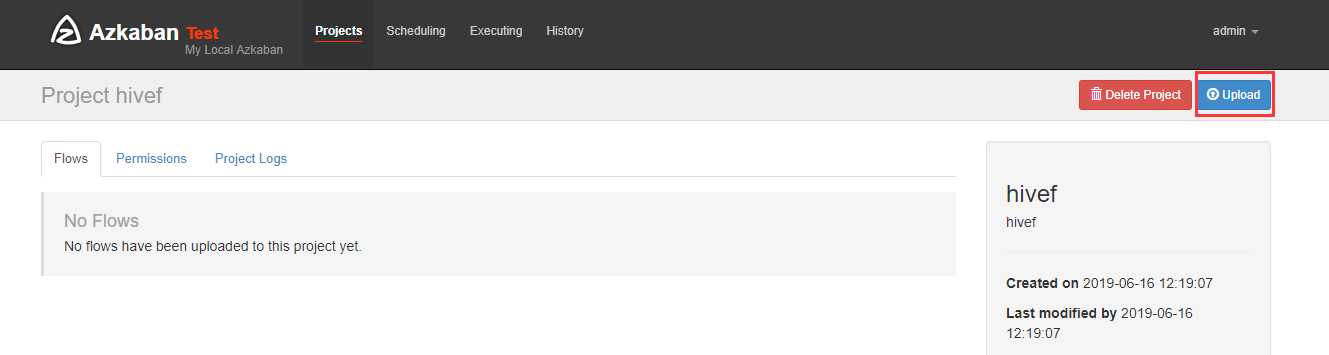
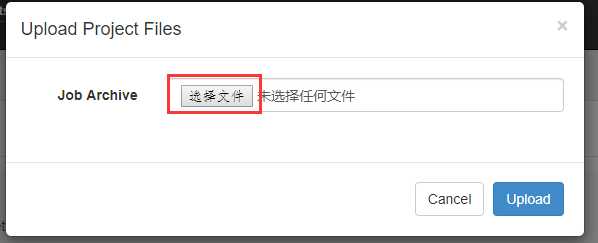
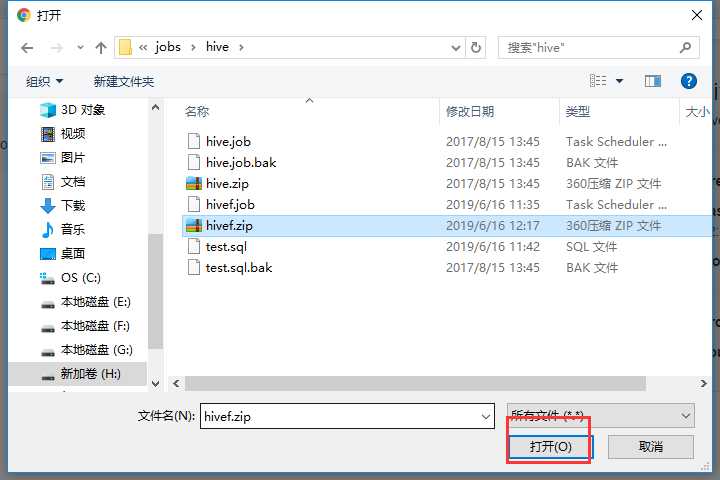
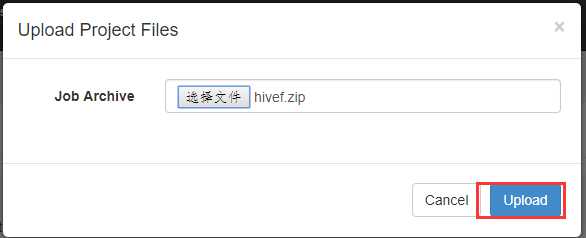
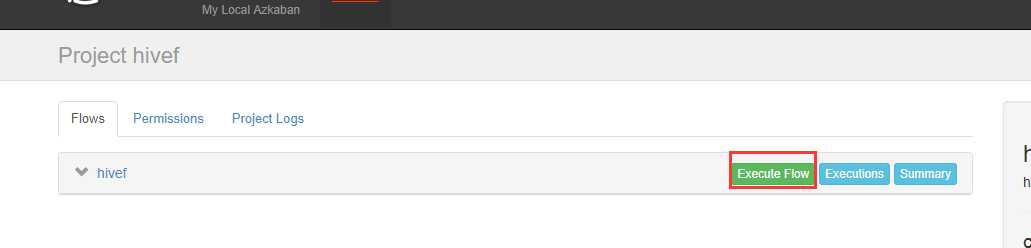
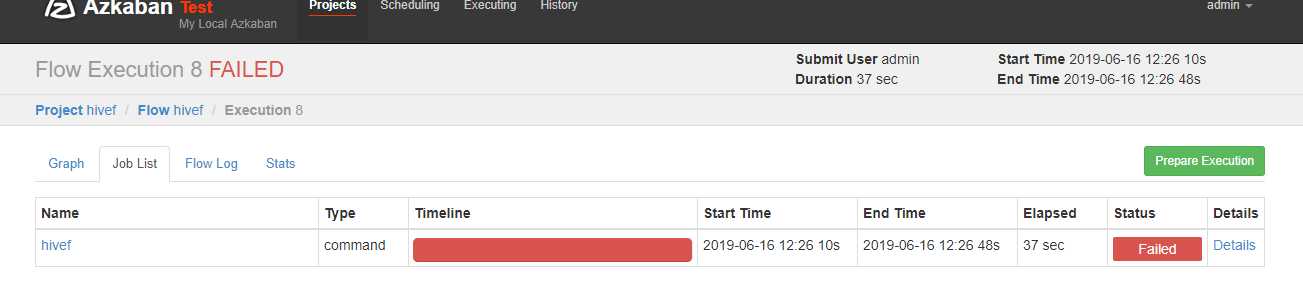
可以看到失败了,查看原因
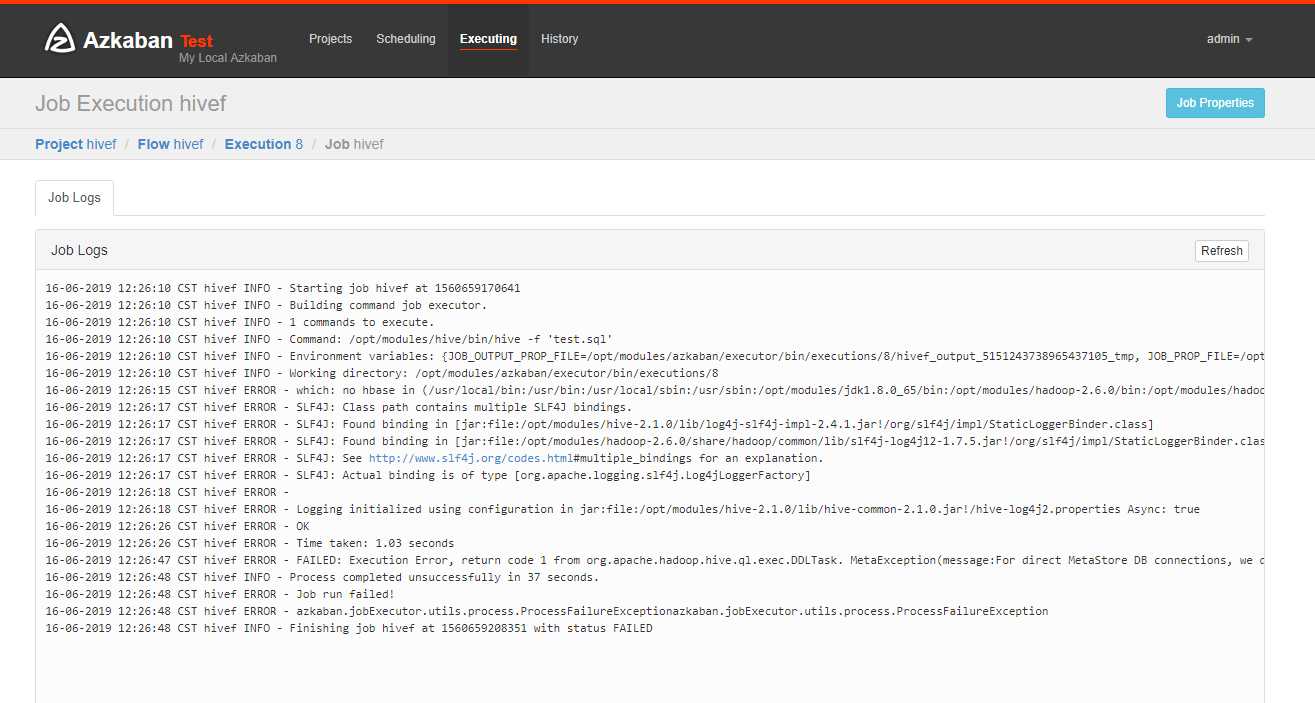
把本地hive的Lib目录下的mysql连接包的版本更换一下
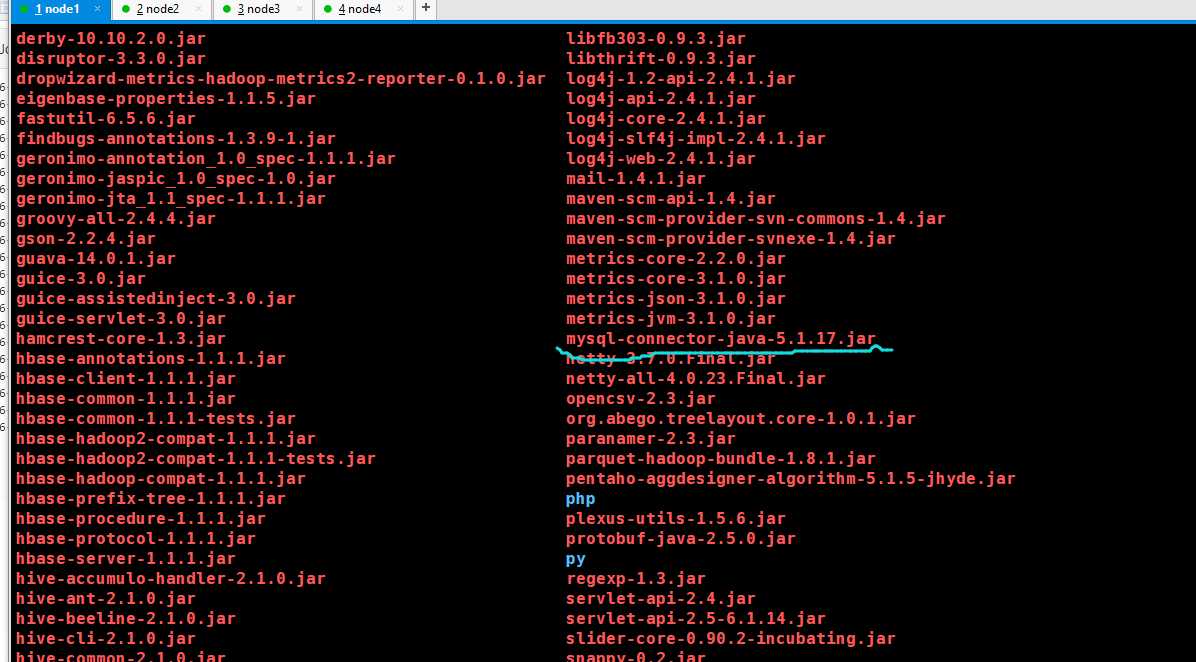
换成这个5.1.28版本
再运行一次,同样失败了,但是hive和hdfs上出来了相应的结果,具有原因我也不懂

原文:https://www.cnblogs.com/braveym/p/10891394.html