Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。Kafka是一种高吞吐量的分布式发布订阅消息系统: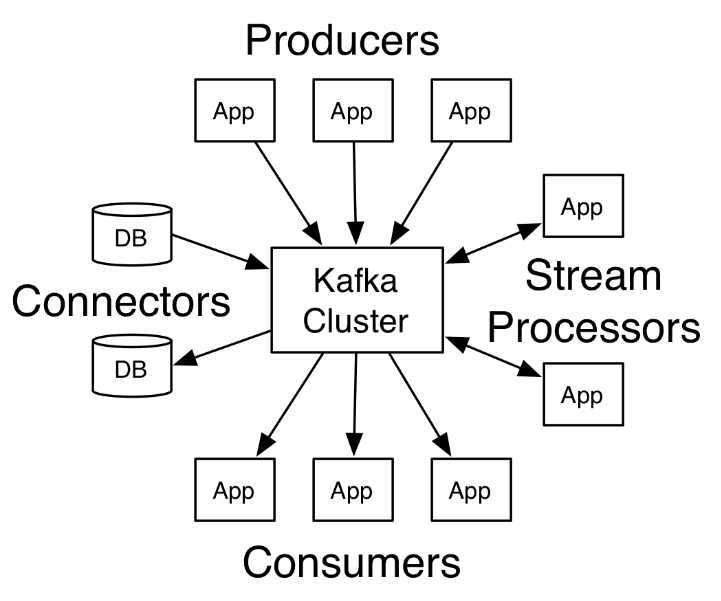
(1)通过O的磁盘数据结构提供消息的持久化,够保持长时间的稳定性能。
(2)高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
(3)支持通过Kafka服务器和消费机集群来分区消息。
(4)支持Hadoop并行数据加载。
本博客主要以:单节点单Broker部署、单节点多Broker部署、集群部署(多节点多Broker)来讲解。在实际生产环境中常用的是第三种方式,以集群的方式来部署Kafka。Kafka比较依赖zookeeper集群,如果想要使用Kafka,就必须部署zookeeper集群,Kafka中的消费偏置信息、kafka集群、topic信息会被存储在ZK中。
在部署集群前,需要部署部署zookeeper集群,直接按照zookeeper3.5.5集群部署就好。
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.2.1/kafka_2.12-2.2.1.tgz
安装
tar xf kafka_2.12-2.2.1.tgz -C /usr/local/src ln -s /usr/local/src/kafka_2.12-2.2.1 /usr/local/kafka
配置kafka
参考官网:http://kafka.apache.org/quickstart
进入kafka的config目录下,在server.properties文件,添加如下配置
broker.id=0 # broker id 全局唯一 listeners=PLAINTEXT://:9092 # 监听 log.dirs=/home/hadoop/kafka-logs # 日志目录 zookeeper.connect=localhost:2181 # 配置zookeeper的连接
原文:https://www.cnblogs.com/wzxmt/p/11032133.html