丢失更新( lost update)是一个经典的数据库问题。实际上,所有多用户计算机系统环境下有可能产生这个问题。简单说来,出现下面的情况时,就会发生丢失更新:
(1)事务T查询一行数据,放入本地内存,并显示给一个终端用户 User1。
(2)事务T2也查询该行数据,并将取得的数据显示给终端用户User2。
(3)User1修改这行记录,更新数据库并提交。
(4)User2修改这行记录,更新数据库并提交。
显然,这个过程中用户 User的修改更新操作“丢失”了。这可能会发生一个恐怖的结果。设想银行丢失了更新操作:一个用户账户中有10000元人民币,他用两个网上银行的客户端转账,第一次转9000人民币,因为网络和数据的关系,这时需要等待。但是如果这时用户可以操作另一个网上银行客户端,转账1元。如果最终两笔操作都成功了,用户的账号余款是9999人民币,第一转的9000人民币并没有得到更新。也许有人会说,不对,我的网银是绑定 USB Key的,不会发生这种情况—通过 USB Key登录也许可以解决这个问题,但是更重要的是,要在数据库层解决这个问题,以避免任何可能发生丢失更新的情况。
要避免丢失更新发生,其实需要让这种情况下的事务变成串行操作,而不是并发的操作。即在上述四种的第(1)种情况下,对用户读取的记录加上一个排他锁,同样,发生第(2)种情况下的操作时,用户也需要加一个排他锁。这种情况下,第(2)步就必须等待第(1)、(3)步完成,最后完成第(4)步,如以下所示:

理解脏读之前,需要理解脏数据的概念。脏数据和脏页有所不同。脏页指的是在缓冲池中已经被修改的页,但是还没有刷新到磁盘,即数据库实例内存中的页和磁盘的页中的数据是不一致的,当然在刷新到磁盘之前,日志都已经被写入了重做日志文件中。而所谓脏数据,是指在缓冲池中被修改的数据,并且还没有被提交(commit)。
对于脏页的读取,是非常正常的。脏页是因为数据库实例内存和磁盘的异步同步造成的,这并不影响数据的一致性。并且因为是异步的,因此可以带来性能的提高。而脏数据却不同,脏数据是指未提交的数据。如果读到了脏数据,即一个事务可以读到另外一个事务中未提交的数据,则显然违反了数据库的隔离性
脏读指的就是在不同的事务下,可以读到另外事务未提交的数据,简单来说,就是可以读到脏数据。比如下面的例子所示:

表t为我们之前64.1中建的表,不同的是在上述例子中,事务的隔离级别进行了更换,由默认的 REPEATABLE READ换成了 READ UNCOMMITTED,因此在会话A中事务并没有提交的前提下,会话B中两次 SELECT操作取得了不同的结果,并且这两个记录是在会话A中并未提交的数据,即产生了脏读,违反了事务的隔离性
脏读现象在生产环境中并不常发生。从上面的例子中就可以发现,脏读发生的条件是需要事务的隔离级别为 READ UNCOMMITTED,而目前绝大部分的数据库都至少设置成READ COMMITTED。 InnoDB存储引擎默认的事务隔离级别为 READ REPEATABLE,Microsoft SQL Server数据库为 READ COMMITTED, Oracle数据库同样也是READ COMMITTED。
不可重复读是指在一个事务内多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务的两次读数据之间,由于第二个事务的修改,第一个事务两次读到的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为不可重复读。
不可重复读和脏读的区别是:脏读是读到未提交的数据;而不可重复读读到的确实是已经提交的数据,但是其违反了数据库事务一致性的要求。可以通过下面一个例子来观察不可重复读的情况:

会话A中开始一个事务,第一次读取到的记录是1,另一个会话B中开始了另一个事务插入一条2的记录。在没有提交之前,会话A中的事务再次读取时,读到的记录还是1,没有发生脏读的现象。但会话2中的事务提交后,在对会话A中的事务进行读取时,这时读到的是1和2两条记录。这个例子的前提是,在事务开始前,会话A和会话B的事务隔离级别都调整为了 READ COMMITTED。
一般来说,不可重复读的问题是可以接受的,因为其读到的是已经提交的数据,本身并不会带来很大的问题。因此,很多数据库厂商(如 Oracle、 Microsoft SQL Server)将共数据库事务的默认隔离级别设置为 READ COMMITTED,在这种隔离级别下允许不可重复读的现象
InnoDB存储引擎中,通过使用Next- Key Lock算法来避免不可重复读的问题。在MySQL官方文档中,将不可重复读定义为 Phantom Problem,即幻象问题。在Next-Key Lock算法下,对于索引的扫描,不仅仅是锁住扫描到的索引,而且还锁住这些索引覆盖的范围(gap)。因此对于这个范围内的插入都是不允许的。这样就避免了另外的事务在这个范围内插入数据导致的不可重复读的问题。因此, InnoDB存储引擎的默认事务隔离级别是READ REPEATABLE,采用Next- Key Lock算法,就避免了不可重复读的现象。
1、MySQL 默认每一条 DML 是一个事务
mysql> show variables like ‘%autocommit%‘;
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
这个参数有一定的危险性,需要给开发做培训
2、在一个事务中,一条 select 语句,在整个事务的生命周期里面,查询到的数据是一致的。
是 MVCC 实现的
3、数据库对于大事务、长事务需要注意
4、空闲事务也是我们
start transaction;
update;
... //空闲等待,时间可能不可控
... //空闲等待,时间可能不可控
update
commit;
5、事务和事务锁有一定的关系
事务不提交、行锁就不会释放、事务锁就不会消失
6、死锁
7、事务分为 commit 和 rollback
8、commit 和 rollback 又分为显式和隐式
mysql> show global status like ‘%commit%‘;
+----------------+------+
| Variable_name | Value|
+----------------+------+
| Com_commit | 0 |——显示提交
| Com_xa_commit | 0 |
| Handler_commit | 3 |——隐式提交
9、事务有一个非常重要的表
select * from INNODB_TRX \G
可以看到是否存在长事务、大事务
10、事务有四个特性
永久性:
积分赠送的业务:A 账户把 100M 流量赠送给 B 账号
1:start transaction;
2:A:update 流量减少100
3、B:update 流量增加 100
4、commit
提交了之后,MySQL 会把这两个 SQL 产生的 redo log 写到磁盘上,这时候就算数据库崩了,数据库重新启动的时候,这个事务会前滚到成功的时候,
一致性/原子性:
A 用户给 B 用户转 100 万:
1:start transaction;
2:A:update 钱减少 100、这时候数据库崩了,数据库起来之后,一看是未提交事务就主动回滚了。
3、B:update 钱增加 100
4:commit
开始事务前的提交事务数:
MySQL> SHOW GLOBAL STATUS LIKE ‘%com_comm%‘;
+---------------+-------+
| Variable_name | VALUE |
+---------------+-------+
| Com_commit | 109 |
+---------------+-------+
1 ROW IN SET (0.01 sec)
MySQL> SHOW GLOBAL STATUS LIKE ‘%com_roll%‘;
+---------------------------+-------+
| Variable_name | VALUE |
+---------------------------+-------+
| Com_rollback| 1 |
| Com_rollback_to_savepoint | 0 |
+---------------------------+-------+
2 rows in set (0.01 sec)
如何开启一个事务:
MySQL> start transaction;
Query OK, 0 rows affected (0.00 sec)
MySQL> delete from t1 where id =2;
Query OK, 0 rows affected (0.00 sec)
MySQL> insert into t1 values(2,‘dskl‘);
Query OK, 1 row affected (0.03 sec)
MySQL> select * from t1;
+----+------+
| id | name |
+----+------+
| 2 | dskl |
| 3 | kljk |
| 4 | dsljk |
| 5 |sjdljok |
+----+---------+
4 rows in set (0.01 sec)
MySQL> delete from t1 where id=4;
Query OK, 1 row affected (0.00 sec)
MySQL> commit;
Query OK, 0 rows affected (0.01 sec)
事务提交后的事务数:
MySQL> show global status like ‘%com_comm%‘;
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Com_commit | 110 |
+---------------+-------+
1 row in set (0.01 sec)
MySQL> show global status like ‘%com_roll%‘;
+----------------+-------+
| Variable_name| Value |
+----------------+------+
| Com_rollback | 1 |
| Com_rollback_to_savepoint | 0 |
+-----------------------+-------+
1rows in set (0.01 sec)
1、有多个隔离级别,可以调整
2、每一个数据库都有自己默认的隔离级别
| tx_isolation | REPEATABLE-READ |默认可重复读
read-uncommitted(未提交读):可以读到别人未提交的数据
read-committed(已提交读),没有范围锁,其他用户可以看见,出现幻影读
repeatable-read(默认),采用范围锁,不会出现幻影现象
serialtable(序列化,同一时刻只有一个事务在执行)
未提交读:read-uncommitted:
mysql> set @@session.tx_isolation=‘READ-UNCOMMITTED‘;
会读到别人未提交的数据,读到脏数据隔离性最弱,并发性最好
已提交读:read-committed
mysql> set @@session.tx_isolation=‘READ-COMMITTED‘;
不会读到别人未提交数据
在同一个事务中,同一个SQL执行多次,得到的结果可能不同可重复读:repeatable-read
mysql> set @@session.tx_isolation=‘REPEATABLE-READ‘
MySQL 默认隔离级别,满足可重复读
在同一个事务中,同一个 SQL 执行多次,得到的结果是相同的
对于 select 来说,通过 MVCC 来实现
序列化:serialtable
mysql> set @@session.tx_isolation=‘SERIALIZABLE‘
隔离性最高
对于同一个数据来说,在同一个时间段内,只能有一个会话可以访问
select
dml
业务有串行化的需求,但是我们不会设置数据库为串行化,而是在应用端设置
A 会话:
看一下 t2 表里共有 14 行数据:

开启一个事务并查看一下 name=abc 的一共有 4 行数据:
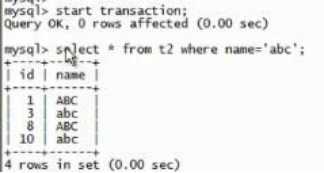
对这 4 行数据加了锁:对表加 is 锁,对 4 行加 x 行锁,事务没有提交
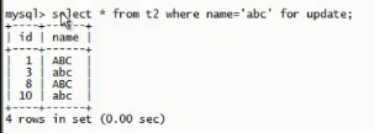
B 会话:
可以读 t2 表的所有的数据,这是写不阻塞读的特性:

想在 t2 表中插入 name 为 abc 的,被锁住了:
insert into t2(name) values(‘abc’);
查看锁等待,发现这个锁:

Requesting_trx_id 被 blocking_trx_id 锁住了:
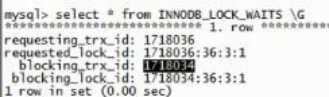
锁超时,释放锁:

昨天讲的是 update 和 delete 没什么影响,为什么 insert 也不行了呢?
因为如果插入成功,被锁的 4 行数据,一会变成 4 行,一会变成 5 行,造成不可重复读现象(即为幻影现象)。
上例中,如果把事务的隔离级别改成可重复读,就会出现幻影现象,具体表现形式是插入成功了。
不可重复读(幻影现象) 可重复读
MySQL 默认情况下是可重复读,解决了幻影问题

改成 read-committed(已提交读)后,出现幻影读
MySQL> set @@session.tx_isolation = ‘READ-COMMITTED‘;
Query OK, 0 rows affected (0.00 sec)
A:设置隔离级别为已提交读:
MySQL> set @@session.tx_isolation = ‘READ-COMMITTED‘;
Query OK, 0 rows affected (0.00 sec)
对这 4 行数据加了锁:对表加 is 锁,对 4 行加 x 行锁,事务没有提交

B:设置隔离级别为已提交读:
MySQL> set @@session.tx_isolation = ‘READ-COMMITTED‘;
Query OK, 0 rows affected (0.00 sec)
对 t2 表插入 name 为abc 的数据,成功了:

A:再去执行,发现成了 5 行 name 为 abc 的数据:
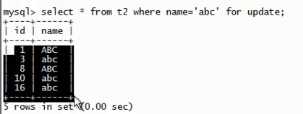
一会 4 行,一会 5 行,如果把这个参数设置成已提交读,就出现了幻影现象。
因为不同锁之间的兼容性关系,所以在有些时刻,一个事务中的锁需要等待另一个事务中的锁释放它所占用的资源。在 InnoDB存储引擎的源代码中,用Mutex数据结构来实现锁。在访问资源前需要用mutex enter函数进行申请,在资源访问或修改完毕后立即执行mutex exit函数。当一个资源已被一个事务占有时,另一个事务执行 mutex enter函数会发生等待,这就是阻塞。阻塞并不是一件坏事,阻塞是为了保证事务可以并发并且正常运行在 InnoDB存储引擎中,参数 innodb_ lock wait timeout用来控制等待的时间(默认是50秒), innodb rollback_ on timeout用来设定是否在等待超时时对进行中的事务进行回滚操作(默认是OFF,代表不回滚)。参数 innodb lock wait timeout是动态的,可以在 MySQL数据库运行时进行调整,而 innodb rollback_on_timeout.是静态的,不可在启动时进行修改,
需要牢记的是,默认情况下 InnoDB存储引擎不会回滚超时引发的错误异常。其实InnoDB存储引擎在大部分情况下都不会对异常进行回滚。
原文:https://www.cnblogs.com/5945yang/p/11061647.html