初探时序数据库-InfluxDB
最近公司有个需求需要借助InfluxDB实现(或者更准确的说,使用该数据库可以更容易的实现),因此稍微看了下这个数据库,把比较重要的一些东西先简单记录一下,日后如果采坑,也会继续在下面补充。
一、什么是时序数据库,它可以用来做什么?
简单来说时序数据库就是带有时间戳的数据,InfluxDB属于一种时序数据库,不过这样解释比较笼统,因为作为关系型数据库的mysql也可以带有时间戳,所以结合实际场景解释比较好理解,比如,现在要记录某航空公司飞机的行程,需要时刻记录下每架飞机飞行的高度、速度、所经地区的温度、所经地区经纬度等信息,因为需要时刻记录,因此会产生大量数据,现在如果去查一下:经过纽约时的高度超过8km的飞机有哪些 或 再查下某架飞机经过的温度超过30℃的地区有哪些。
针对这种情况,再往Mysql里记录就不太适合了,这时可以使用时序数据库进行分布式存储,时序数据库对范围分组查询、最大值、最小值、均值、最大最小求和等计算的支持是非常友好的。
时序数据库还支持过期策略,超过指定期限的数据将被回收,因此用时序数据库做监控也是不错的选择。
二、InfluxDB基本概念
1.不需要专门建表,一般insert执行过去时,如果发现表不存在,就自动创建。
2.基本概念与mysql中概念的对应关系
| database | 数据库 | 类似mysql里的库 |
| measurement | 表 | 类似mysql里的表 |
| point | 一行数据记录 | 类似mysql里的一行数据 |
3.point的概念就类似于mysql里一行数据,point的构成部分有三个:
| time | 时间戳 | influxdb自带字段,单位:纳秒 |
| tags | 有各种索引的属性 | 可设置多个,逗号隔开 |
| fields | 没有索引的属性 | 可设置多个,逗号隔开 |
tags和fileds的区别:
1. field无索引,一般表示会随着时间戳而发生改变的属性,比如温度、经纬度等,类型可以是 string, float, int, bool
2. tag有索引,一般表示不会随着时间戳而发生改变的属性,比如城市、编号等,类型只可为 string
比较值得注意的是:在InfluxDB中,tags决定了series的数量,而series的数量越大,对于系统CPU和InfluxDB的性能影响越大,series估算方法下面会说。
4.sql语句示范
插入数据:
insert results,hostname=index2,name=index2333 value=2,value2=4
---------- ---------------------------------------- -------------------------
表名 tags的设置 fields的设置
上面这句sql的意思就是说在名为result的表里,插入两个分别命名为hostname和name取值分别为index2和index2333的tags,以及两个分别命名为value和value2取值分别为2和4的fields的数据。
注意:这里的指令直接输入整数,influxDB是按照浮点型处理的,如果一定要让上面的value=2和value2=4中的2和4是整型数据,那么需要在后面加上修饰词:value=2i,i就代表整型。
检索数据:
select * from results
打印结果为:
name: results2
time hostname name value value2
---- -------- ---- ----- ------
1560928150794920700 index2 index2333 2 4
分页检索:
SELECT * FROM 表 WHERE 条件 LIMIT rows OFFSET (page - 1)*rows
rows代表每页展示行数,page表示页码
删除表:
drop measurement "表名"
三、InfluxDB的时效设置
很遗憾,InfluxDB是不支持删除和修改的,删除有专门的操作,但是性能很低,不建议使用。
InfluxDB支持定期清除数据策略。
查看当前库对应策略配置的命令为:
show retention policies on "库名"
结果:
name duration shardGroupDuration replicaN default
------- --------- ------------------ --------- -------
autogen 0s 168h0m0s 1 true
name:过期策略名
duration:保留多长时间的数据,比如3w,意思就是把三周前的数据清除掉,只保留三周内的,支持h(小时),d(天),w(星期)这几种配法。
shardGroupDuration:存储数据的分组结构,比如设置为1d,表示的是每组存储1d的数据量,也就是说数据将按照天为单位划分存储分组,然后根据每条数据的时间戳决定把它放到哪个分组里,因此这个概念还会影响到过期策略,因为InfluxDB在清除过期数据时不可能逐条清理,而是通过清除整个ShardGroup的方式进行,因为通过跟当前时间对比就可以知道哪些分组里的数据一定是过期的,从而进行整组清理,效率往往更高,此外这个概念还会影响一些查询性能,比如我在2019-06-20查询当日数据的查询性能要优于查询2019-06-19数据的性能(因为查询跨组)。
replicaN:副本数量,一般为1个(这个大概就是备份的意思?这个配置在单实例模式下不起作用)
default:是否启用配置,设置为true表示默认的意思,一个库允许有多套策略配置(每套策略里都可以有自己的一份数据,比如同样一张表的数据在策略A和策略B的情况下是不同的,可以理解为一个库对应N个策略,每个策略里有自己的N多张表,相互独立),在不指定策略名称的情况下,默认使用default=true的策略。
当然,策略也支持修改,指令如下:
alter retention policy "autogen" on "test" duration 30d default
上面这条指令就会把上面策略明为autogen的策略有效保存时间改为30天。
了解完策略,结合上面提到的series、tags、fields等概念,画一下单个InfluxDB库的存储结构:
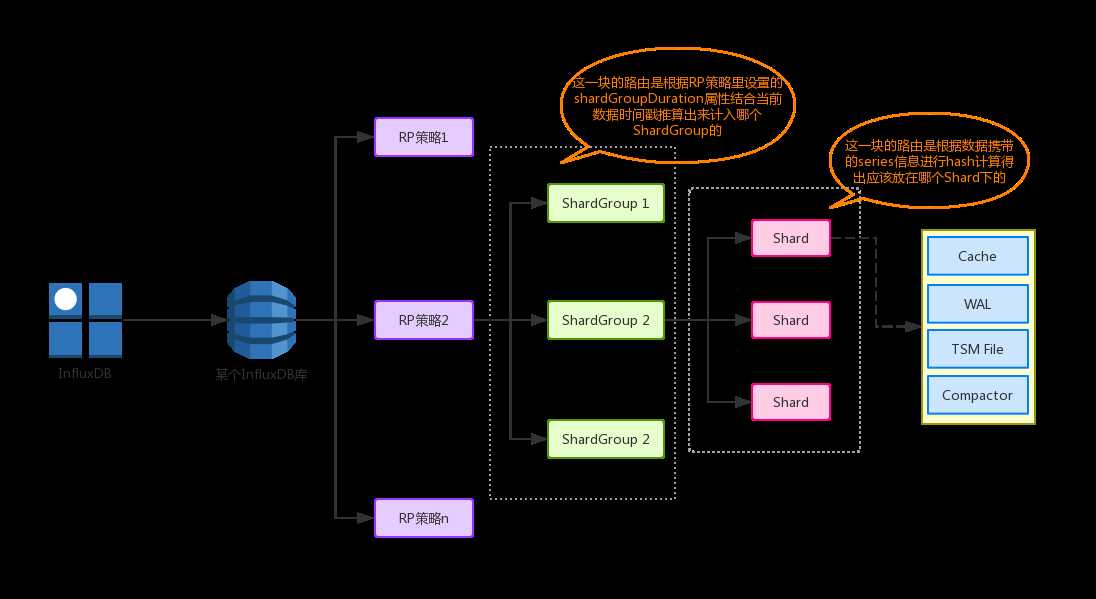
图1
图里没有体现出tags、fields这些数据层面的东西,它们最终被存放在了Shard里,之前说过tags会影响series的大小,其实series就相当于一个唯一化分类,series估算方式为:
series的个数 = RP × measurement × tags(tags去重后的个数)
比如一个database中有一个measurement,叫test,有两个RP(7d, 30d),tag有host,server。host的值有hostA、hostB,server为server1,server2。那么这个database的series值为2RP x 4tags = 8
回归图1前,先来了解下LSM-Tree,几乎所有的k-v存储的写密集型数据库都采用该数据结构实现,该数据结构的结构如下:
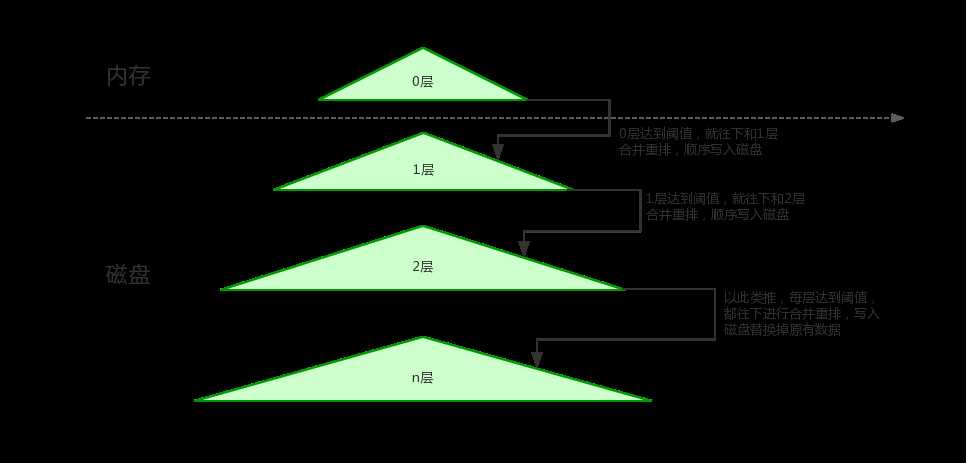
图2
如图2,该结构写入流程如下:
写入的数据首先加到0层,0层的数据存储在内存中,短期内查询的数据一般在0层,由于是内存操作,因此效率会非常高,当0层的数据达到一定大小时,此时会把0层 和位于它下面的1层进行合并,然后合并出来的新的数据(0层+1层的数据)会顺序写磁盘(这里由于是顺序写入磁盘,因此写性能会非常好),然后替换掉原来老的1层数据,当1层达到一定大小的时候,将继续和它的下层合并,以此类推,一级一级的往下递,除此之外还可以将合并之后旧文件全部删掉,留下最新的。
LSM-Tree参考文章:LSM-tree 基本原理及应用
然后回归图1,最终的数据会被存储进Shard,Shard里存在几个区域,就是最终存放数据的地方,下面针对这几个区域说明下它们的作用:
Cache:
相当于上面说的LSM-Tree的0层,存放于内存中,写入的数据时首先被该模块接收并存储,该模块在内存中表现为一个map结构,k = seriesKey + 分隔符 + fieldsName,v = 具体的filed对应的值的数组,具体结构体如下(参考网上资料):
type Cache struct {
commit sync.Mutex
mu sync.RWMutex
store map[string]*entry
size uint64 // 当前使用内存的大小
maxSize uint64 // 缓存最大值
// snapshots are the cache objects that are currently being written to tsm files
// they‘re kept in memory while flushing so they can be queried along with the cache.
// they are read only and should never be modified
// memtable 快照,用于写入 tsm 文件,只读
snapshot *Cache
snapshotSize uint64
snapshotting bool
// This number is the number of pending or failed WriteSnaphot attempts since the last successful one.
snapshotAttempts int
stats *CacheStatistics
lastSnapshot time.Time
}
基于前面说的LSM-Tree,可以知道这里的cache不是持续增长的,而是达到一定值就会进行跟下层存储在磁盘上的数据(1~n层)进行合并,然后清空cache,在InfluxDB中,这一部分存储在磁盘上的数据,就是指TSM File模块,下面会介绍。
WAL:
在上面对于Cache的描述中,Cache是基于内存做的写入数据接收方,那么如果中途机器宕掉,那么就会造成Cache里数据丢失的问题,为了解决这个问题,InfluxDB就设计了WAL模块,实际在写入一个数据时,不仅会先写进Cache,还会写入WAL,可以简单理解WAL就是对Cache里数据的备份,防止数据丢失,在Cache做完一次合并清除掉自身时,旧的WAL文件也会随之删除,然后新建一个WAL,迎接新一轮的写入。同样的,在InfluxDB启动时,也会先去读取WAL文件初始化Cache模块。
TSM File
用于组成TSM-Tree结构的主要磁盘文件(可以对应图2的1~n层),内部做了很多存储以及压缩优化,单个TSM File的最大大小为2GB。
Compactor:
在后台持续运行的一个task(频率为1s),主要做以下事情:
①在Cache达到阈值时,进行快照,然后将数据合并并保存在TSM File中
②合并TSM File,将多个小型TSM File进行合并,使得每个文件的大小尽可能达到单个文件最大大小(也就是上面说到的2GB)
③检查并删除一些已关闭的WAL文件
-后续遇坑更新-
原文:https://www.cnblogs.com/hama1993/p/11062245.html