实验结论
Part1: 验证性实验
验证性实验1:已知文件?le1.txt已经存在,将?le1.txt中小写字母转换成大写后,另存为?le2.txt
// 将file1.txt中小写字母转换成大写后,另存为file2.txt #include <stdio.h> #include <stdlib.h> int main() { FILE *fin, *fout; // 定义文件类型指针 int ch; fin = fopen("file1.txt", "r"); // 以只读文本方式打开文件file1.txt if (fin == NULL) { printf("fail to open file1.txt\n"); exit(0); } fout = fopen("d:\\file3.txt", "w"); // 以写文本方式打开文件file2.txt, 如果文件不存在,就创建一个 if (fout == NULL) { printf("fail to open or create file2.txt\n"); exit(0); } while( !feof(fin) ) { ch = fgetc(fin); // 从fin指向的文件file1.txt中读取单个字符,暂存在字符变量ch中 if(ch >= ‘a‘ && ch <= ‘z‘) // 如果是小写字母,则转换成大写 ch -= 32; fputc(ch, fout); // 将字符变量ch中的字符写入fout指向的文件file2.txt中 } fclose(fin); fclose(fout); return 0; }
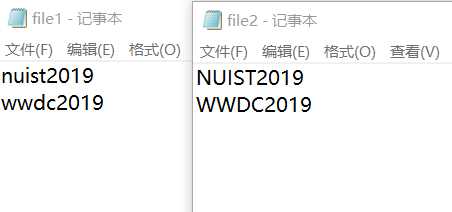
对于以"w"方式打开的文件,如果原先文件不存在,那么就新建一个;如果文件已经存在,那
么新写入的数据会覆盖文件中原来的内容。如果不希望覆盖可以选择在文件尾部追加的方式, 即"a"。
之前看实验七时没有太注意这条,在编程练习中好奇就去试了下,翻回来再看到这里,感觉c语言的确是很贴合思维的。
电脑是Mac OS,则按Mac OS下路径方式改写尝试。比如,改成"/Users/××/?le3.txt",其中, ××是Mac安装登录时的用户名。(感觉这里以后会有用,码一下)
验证性实验2:已知文本数据文件?le1.dat,从文件?le1.dat中读入数据,找出最高分和最低分学生信息,并输出在屏幕上。

如不知学生人数可作如下修改
for(i=0; i<N; i++) ↓↓↓ 改为 while( !feof(fp) )
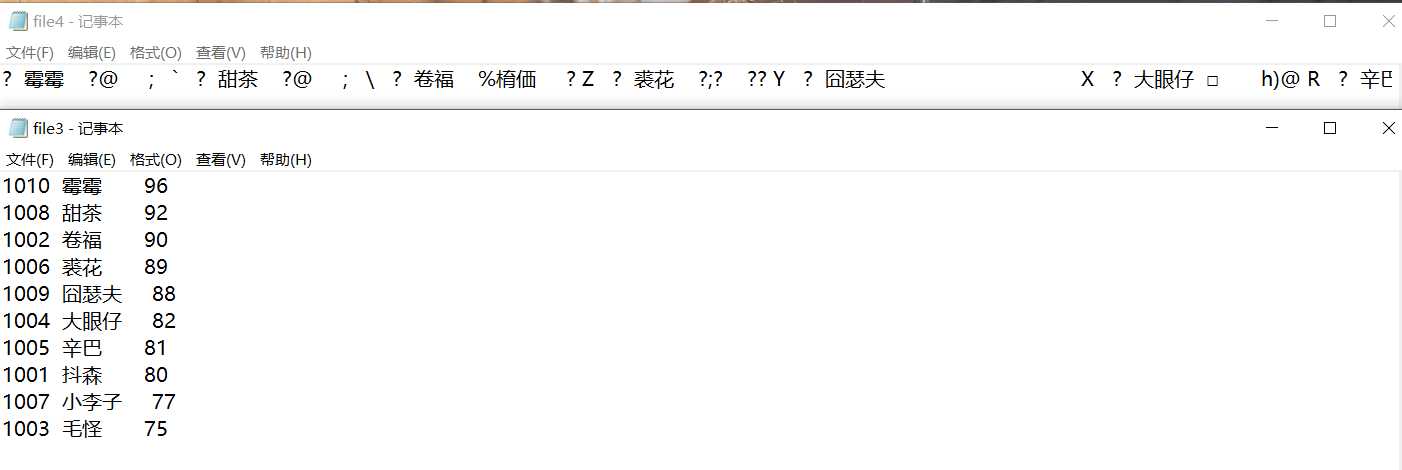
验证性实验3:已知文本数据文件?le1.dat,从文件?le1.dat中读入数据,按成绩从高到低排序,将排序结果输出到屏幕上,同时也以文本方式存入文件 ?le3.dat中
验证性实验4:已知文本数据文件?le1.dat,从文件?le1.dat中读入数据,按成绩从高到低排序,将排序结果输出到屏幕上,同时也以二进制方式存入文件 ?le4.dat中
//验证性实验3 // 从文本数据文件file1.dat中读入数据,按成绩从高到低排序,将排序结果输出到屏幕上,同时以文本方式存入文件file3.dat中。 #include <stdio.h> #include <stdlib.h> #define N 10 // 定义一个结构体类型STU typedef struct student { int num; char name[20]; int score; }STU; void sort(STU *pst, int n); // 函数声明 int main() { FILE *fin, *fout; STU st[N]; int i; // 以只读文本方式打开文件file1.dat fin = fopen("file1.dat", "r"); if( !fin ) { // 如果打开失败,则输出错误提示信息,然后退出程序 printf("fail to open file1.dat\n"); exit(0); } // 从fin指向的数据文件file1.dat中读取数据到结构体数组st for(i=0; i<N; i++) fscanf(fin, "%d %s %d", &st[i].num, st[i].name, &st[i].score); fclose(fin); // 关闭fin指向的文件file1.dat // 调用函数sort()对数组st中数据,按分数又高到低排序 sort(st, N); // 以写方式打开/创建文本文件file3.dat fout = fopen("file3.dat", "w"); if( !fout ) { // 如果打开失败,则输出错误提示信息,然后退出程序 printf("fail to open file1.dat\n"); exit(0); } // 将排序后的数组st中数据输出到屏幕,同时,也写入文件file3.dat for(i=0; i<N; i++) { printf("%-6d%-10s%3d\n", st[i].num, st[i].name, st[i].score); fprintf(fout, "%-6d%-10s%3d\n", st[i].num, st[i].name, st[i].score); } fclose(fout); // 关闭fout指向的文件file3.dat return 0; } // 函数功能描述:对pst指向的n个STU结构体数据进行排序,按成绩数据项由高到底排序 // 排序算法:冒泡法 void sort(STU *pst, int n) { STU *pi, *pj, t; for(pi = pst; pi < pst+n-1; pi++) for(pj = pi+1; pj < pst+n; pj++) if(pi->score < pj->score) { t = *pi; *pi = *pj; *pj = t; } } // 说明:冒泡排序算法是确定的,但其具体实现方式和细节却是灵活多样的 // 本例中,冒泡排序算法的函数体中,都是通过指针变量操作的。 // 而在前面章节的实例中,冒泡排序的函数体,有些是通过数组实现的,有些是指针和数组的混合 // 请结合代码体会和理解,做到理解算法本质,才能应对和理解灵活多样的实现形式
Part2: 编程练习
#include <stdio.h> #include <string.h> #include <stdlib.h> const int N = 10; // 定义结构体类型struct student,并定义其别名为STU typedef struct student { long int id; char name[20]; float objective; float subjective; float sum; char level[10]; }STU; // 函数声明 void input(STU s[], int n); void output(STU s[], int n); void process(STU s[], int n); int main() { STU stu[N]; printf("录入%d个考生信息: 准考证号,姓名,客观题得分(<=40),操作题得分(<=60)\n", N); input(stu, N); printf("\n对考生信息进行处理: 计算总分,确定等级\n"); process(stu, N); printf("\n打印考生完整信息: 准考证号,姓名,客观题得分,操作题得分,总分,等级\n"); output(stu, N); return 0; } // 录入考生信息:准考证号,姓名,客观题得分,操作题得分 void input(STU s[], int n) { FILE *fin; int i; fin=fopen("examinee.txt", "r"); if (fin == NULL) { printf("fail to open examinee.txt\n"); } for(i=0;i<n;i++) fscanf(fin,"%d %s %f %f", &s[i].id, s[i].name, &s[i].objective, &s[i].subjective); fclose(fin); } //输出考生完整信息: 准考证号,姓名,客观题得分,操作题得分,总分,等级 void output(STU s[], int n) { FILE *fout; int i; printf("-----------------\n"); printf("学号 姓名 客观 主观 总成绩 成绩等级\n"); fout = fopen("result.txt", "w"); if (fout == NULL) { printf("fail to open or create result.txt\n"); } for(i=0;i<n;i++){ printf("%4d %5s %6.2f %7.2f %7.2f %s\n", s[i].id, s[i].name, s[i].objective, s[i].subjective, s[i].sum, s[i].level); fprintf(fout,"%4d %5s %6.2f %7.2f %7.2f %s\n", s[i].id, s[i].name, s[i].objective, s[i].subjective, s[i].sum, s[i].level); } fclose(fout); } // 对考生信息进行处理:计算总分,排序,确定等级 void process(STU s[], int n) { int i,j; STU temp; for(i=0;i<n;i++) s[i].sum=s[i].objective+s[i].subjective; for(i=0;i<n-1;i++) { for(j=0;j<n-1-i;j++) if(s[j].sum<s[j+1].sum) { temp = s[j]; s[j] = s[j+1]; s[j+1] = temp; } } for(i=0;i<n;i++) { if(i<0.1*n) strcpy(s[i].level,"优"); else if(i<0.5*n&&i>=0.1*n) strcpy(s[i].level,"合格"); else if(i>=0.5*n) strcpy(s[i].level,"不合格"); } }
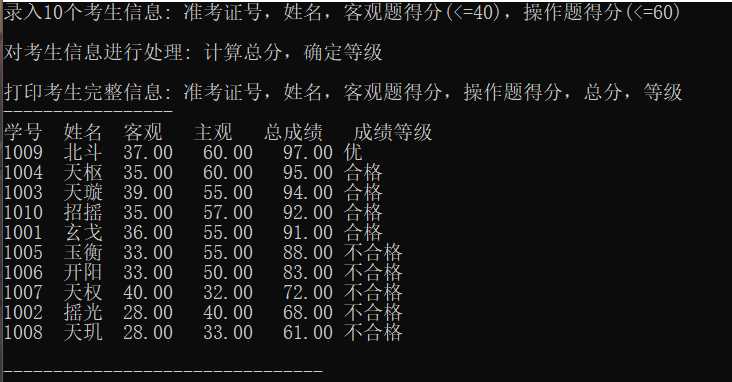
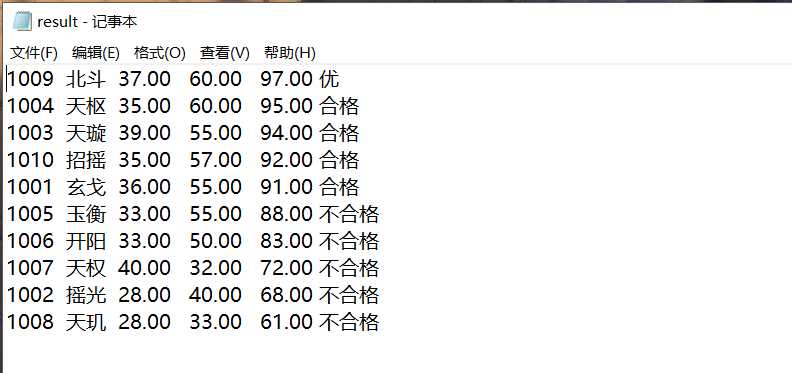
实验总结和体会
这次试验总体来说,我觉得还算顺理,内容并不复杂,只需要注意到这一串新函数的格式和定义就可以(当然写错的地方还是一如既往的多)。最花时间的应该还是part2的填空,实验前好奇把一个文件的dat后缀改成了txt。感觉并没有什么区别,以至于接下来几次试运行都显示一堆奇怪的字符,除了最后的等级是对的。其实还是怪我从别处搬运一两行来写自己的代码,有些是对不上的。
到底也是最后一次试验了,简单总结一下吧。这对于我自己是一次完全崭新的学习,它需要额外花时间去应用,去踩坑,去试错。去自己找资料,去看书,去把不懂得或者延伸的去解决。没有高数,大物那些在初中高中就开始构筑的基础,这样摸着石头过河的感觉好像真的很久没有过了,很怀念,也很有意思。
ps.之后抽个空把part3补上噜。(flag已立)
原文:https://www.cnblogs.com/astraeus/p/11062041.html